Пошаговое интерактивное руководство по одной из самых сложных областей машинного обучения.
Делиться

В принципе, обучение с подкреплением — обучение на основе наблюдений и вознаграждений — является методом, наиболее похожим на то, как учатся люди (и животные).
Несмотря на это сходство, она также остается самой сложной и запутанной областью в современном машинном обучении. Как сказал известный Анджей Карпати:
Обучение с подкреплением — это ужасно. Так уж получилось, что всё, что у нас было раньше, было намного хуже.
Для лучшего понимания метода я пошагово продемонстрирую, как агент учится ориентироваться в окружающей среде с помощью Q-обучения. Текст начнётся с основных принципов и закончится полностью функционирующим примером, который можно запустить в игровом движке Unity.
Для понимания этой статьи необходимы базовые знания языка программирования C#. Если вы не знакомы с игровым движком Unity, просто представьте, что каждый объект — это агент, который:
- Выполняет функцию
Start()один раз в начале программы. - и непрерывно
Update()параллельно с другими агентами.
Сопутствующий репозиторий для этой статьи находится на GitHub. Все изображения предоставлены автором.
Что такое обучение с подкреплением?
В обучении с подкреплением (Reinforcement Learning, RL) у нас есть агент, который способен совершать действия, наблюдать за результатами этих действий и учиться на основе вознаграждений/наказаний за эти действия.

Способ, которым агент принимает решение о действии в определенном состоянии, зависит от его политики . Политика π — это функция, определяющая поведение агента, сопоставляющая состояния с действиями. Для заданного множества состояний S и множества действий A политика представляет собой прямое отображение: π: S → A
Кроме того, если мы хотим, чтобы у агента было больше возможных вариантов выбора, мы можем создать стохастическую политику. В этом случае политика определяет вероятность совершения каждого действия в данном состоянии не за счет одного действия: π: S × A → [0, 1] .
Пример навигации робота
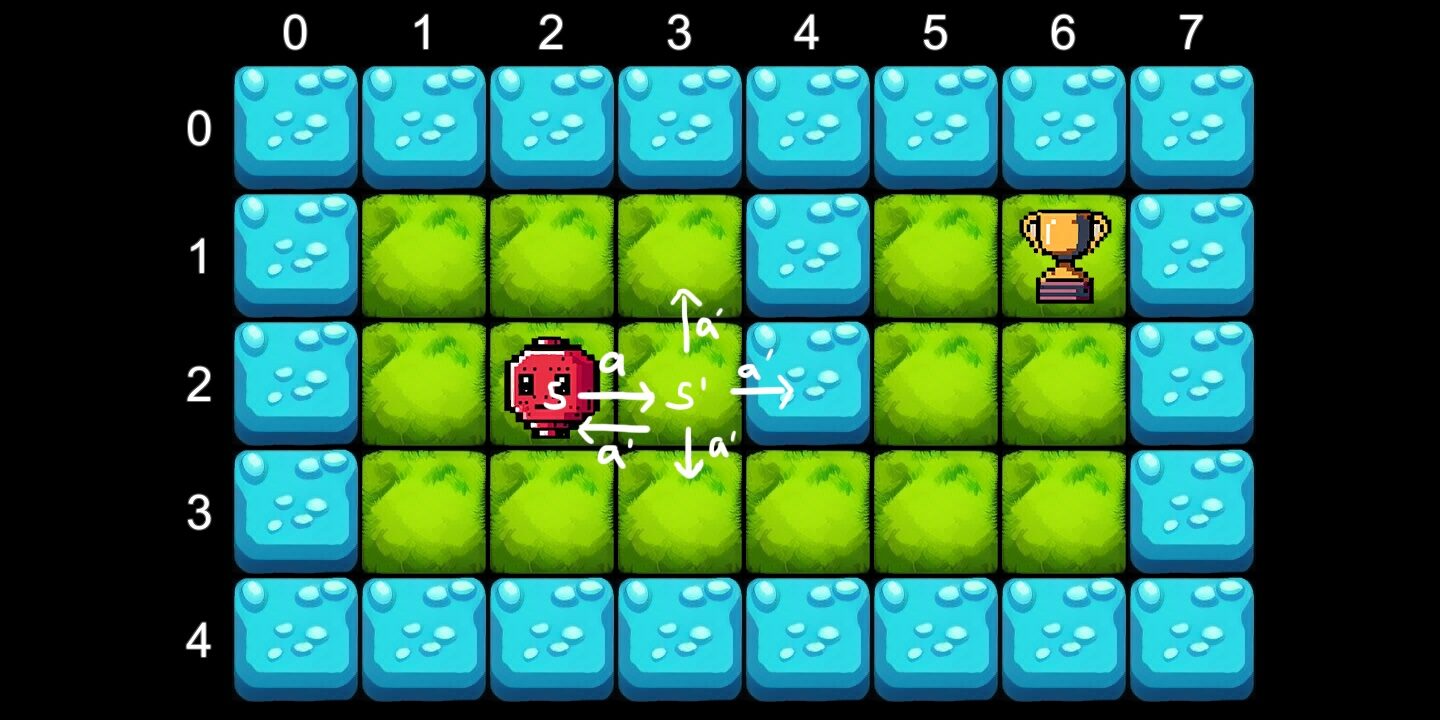
Для иллюстрации процесса обучения мы создадим пример робота, перемещающегося в двухмерной среде, используя одно из четырех действий, A = {Left, Right, Up, Down} . Робот должен найти путь к награде из любой точки карты, не упав в воду.

Награды будут закодированы вместе с типами плиток с помощью перечисления (Enum):
public enum TileEnum { Water = -1, Grass = 0, Award = 1 }
Состояние определяется его положением на сетке, то есть у нас есть 40 возможных состояний: S = [0…7] × [0…4] (сетка из 8 × 5 плиток), которые мы кодируем с помощью двумерного массива:
_map = { { -1, -1, -1, -1, -1, -1, -1, -1 }, // all water border { -1, 0, 0, 0, -1, 0, 1, -1 }, // 1 = Award (trophy) { -1, 0, 0, 0, -1, 0, 0, -1 }, { -1, 0, 0, 0, 0, 0, 0, -1 }, { -1, -1, -1, -1, -1, -1, -1, -1 }, // all water border }
Мы храним карту в элементе управления TileGrid , который выполняет следующие вспомогательные функции:
// Obtain a tile at a coordinate public T GetTileByCoords(int x, int y); // Given a tile and an action, obtain the next tile public T GetTargetTile(T source, ActionEnum action); // Create a tile grid from the map public void GenerateTiles();
Мы будем использовать разные типы тайлов, поэтому используем общий тип T Каждый тайл имеет TileType заданный в TileEnum , и, следовательно, свою награду, которую можно получить как (int) TileType .
Уравнение Беллмана
Задача поиска оптимальной стратегии может быть решена итеративно с использованием уравнения Беллмана. Уравнение Беллмана постулирует, что долгосрочная выгода от действия равна непосредственной выгоде от этого действия плюс ожидаемая выгода от всех будущих действий.
Его можно вычислять итеративно для систем с дискретными состояниями и дискретными переходами между состояниями. Имеются следующие характеристики:
-
s— текущее состояние, -
A— множество всех действий, -
s'— состояние, достигнутое в результате действийaсостоянииs, -
γ— коэффициент дисконтирования (чем больше вознаграждение, тем меньше его ценность). -
R(s, a)— непосредственное вознаграждение за совершение действияaв состоянииs
Уравнение Беллмана гласит, что значение V(s) состояния s равно:

Решение уравнения Беллмана итеративным методом
Вычисление уравнения Беллмана — задача динамического программирования. На каждой итерации n мы вычисляем ожидаемое будущее вознаграждение, достижимое за n+1 шагов для всех клеток. Для каждой клетки мы сохраняем это значение в переменной Value .
Мы начисляем вознаграждение в зависимости от целевого значения клетки: 1 , если награда получена, -1 если робот упал в воду, и 0 в противном случае. После получения награды или попадания в воду никакие действия невозможны, поэтому значение состояния остается равным исходному значению 0 .
Мы создаём менеджер, который будет генерировать сетку и вычислять количество итераций:
private void Start() { tileGrid.GenerateTiles(); } private void Update() { CalculateValues(); Step(); }
Для отслеживания значений мы будем использовать класс VTile , который содержит Value . Чтобы избежать прямого получения обновленных значений, мы сначала устанавливаем NextValue , а затем устанавливаем все значения сразу в функции Step() .
private float gamma = 0.9; // Discounting factor // The Bellman equation private double GetNewValue(VTile tile) { return Agent.Actions .Select(a => tileGrid.GetTargetTile(tile, a)) .Select(t => t.Reward + gamma * t.Value) // Reward in [1, 0, -1] .Max(); } // Get next values for all tiles private void CalculateValues() { for (var y = 0; y < TileGrid.BOARD_HEIGHT; y++) { for (var x = 0; x < TileGrid.BOARD_WIDTH; x++) { var tile = tileGrid.GetTileByCoords(x, y); if (tile.TileType == TileEnum.Grass) { tile.NextValue = GetNewValue(tile); } } } } // Copy next values to current values (iteration step) private void Step() { for (var y = 0; y < TileGrid.BOARD_HEIGHT; y++) { for (var x = 0; x < TileGrid.BOARD_WIDTH; x++) { tileGrid.GetTileByCoords(x, y).Step(); } } }
На каждом шаге значение V(s) каждой плитки обновляется до максимального значения из всех действий, равного непосредственной награде, плюс дисконтированная стоимость полученной плитки. Будущая награда распространяется от плитки «Награда» с убывающей отдачей, регулируемой γ = 0.9 .

Качество действий (Q-значения)
Мы нашли способ связать состояния со значениями, чего достаточно для решения этой задачи поиска пути. Однако этот подход фокусируется на окружающей среде, игнорируя агента. Для агента же обычно важно знать, какое действие было бы оптимальным в данной среде.
В Q-обучении значение действия называется его качеством (Q-значением). Каждой паре (state, action) присваивается одно Q-значение.

Где новый гиперпараметр α определяет скорость обучения — насколько быстро новая информация вытесняет старую. Это аналогично стандартному машинному обучению, и значения обычно схожи, здесь мы используем 0.005 . Затем мы вычисляем выгоду от совершения действия, используя временную разницу D(s,a) :

Поскольку мы больше не рассматриваем все действия в текущем состоянии, а оцениваем качество каждого действия отдельно, мы максимизируем не все возможные действия в текущем состоянии, а все возможные действия в состоянии, которого мы достигнем после выполнения действия, качество которого мы вычисляем, в сочетании с вознаграждением за выполнение этого действия.

Член, описывающий временную разницу, объединяет непосредственное вознаграждение с наилучшим возможным будущим вознаграждением, что делает его прямым выводом уравнения Беллмана (подробнее см. в Википедии).
Для обучения агента мы снова создаем сетку, но на этот раз мы также создаем экземпляр агента, размещенный в точке (2,2) .
private Agent _agent; private void ResetAgentPos() { _agent.State = tileGrid.GetTileByCoords(2, 2); } private void Start() { tileGrid.GenerateTiles(); _agent = Instantiate(agentPrefab, transform); ResetAgentPos(); } private void Update() { Step(); }
Объект Agent имеет текущее состояние QState . Каждое QState хранит значение Q для каждого доступного действия. На каждом шаге агент обновляет качество каждого действия, доступного в состоянии:
private void Step() { if (_agent.State.TileType != TileEnum.Grass) { ResetAgentPos(); } else { QTile s = _agent.State; // Update Q-values for ALL actions from current state foreach (var a in Agent.Actions) { double q = s.GetQValue(a); QTile sPrime = tileGrid.GetTargetTile(s, a); double r = sPrime.Reward; double qMax = Agent.Actions.Select(sPrime.GetQValue).Max(); double td = r + gamma * qMax - q; s.SetQValue(a, q + alpha * td); } // Take the best available action a ActionEnum chosen = PickAction(s); _agent.State = tileGrid.GetTargetTile(s, chosen); } }
Agent обладает набором возможных действий в каждом состоянии и выберет наиболее подходящее действие в каждом из этих состояний.
Если существует несколько оптимальных действий, одно из них выбирается случайным образом, поскольку действия были перемешаны заранее. Из-за этой случайности каждое обучение будет проходить по-разному, но, как правило, стабилизируется в диапазоне от 500 до 1000 шагов.
Это основа Q-обучения. В отличие от значений состояний, качество действий может применяться в ситуациях, когда:
- Наблюдение в данный момент является неполным (поле зрения агента).
- Наблюдение меняется (объекты движутся в окружающей среде).
Исследование против эксплуатации (ε-жадность)
До сих пор агент всегда выбирал наилучший возможный вариант, однако это может привести к тому, что он быстро застрянет в локальном оптимуме. Ключевой проблемой в Q-обучении является компромисс между исследованием и использованием:
- Эксплойт — выбор действия с наибольшим известным значением Q (жадный подход).
- Исследуйте — выберите случайное действие, чтобы обнаружить потенциально лучшие пути.
ε-Жадная политика
При заданном случайном значении r ∈ [0, 1] и параметре epsilon возможны два варианта:
- Если
r > epsilonто выберите наилучшее действие (использование уязвимости). - В противном случае выберите случайное действие (исследование).
Распад Эпсилона
Как правило, на ранних этапах мы стремимся провести более тщательное исследование, а на более поздних — максимально эффективно использовать полученные данные. Это достигается за счет уменьшения epsilon с течением времени:
float epsilon = max(epsilonMin, epsilon − epsilonDecay)
После достаточного количества шагов политика агента сходится к тому, что он почти всегда выбирает действие максимального качества.
private epsilonMin = 0.05; private epsilonDecay = 0.005; private ActionEnum PickAction(QTile state) { ActionEnum action = Random.Range(0f, 1f) > epsilon ? Agent.Actions.Shuffle().OrderBy(state.GetQValue).Last() // exploit : Agent.RndAction(); // explore epsilon = Mathf.Max(epsilonMin, epsilon - epsilonDecay); return action; }
Более широкая экосистема RL
Q-обучение — это один из алгоритмов в более широком семействе методов обучения с подкреплением (Reinforcement Learning, RL). Алгоритмы можно классифицировать по нескольким направлениям:
- Пространство состояний: дискретное (например, настольные игры) | непрерывное (например, шутеры от первого лица)
- Пространство действий: Дискретное (например, стратегические игры) | Непрерывное (например, вождение)
- Тип политики: Внеполитическая (Q-обучение:
a'всегда максимизируется) | В рамках политики (SARSA:a'выбирается текущей политикой агента) - Оператор: Ценность | Качество | Преимущество
A(s, a) = Q(s, a) − V(s)
Полный список алгоритмов обучения с подкреплением можно найти на странице Википедии, посвященной обучению с подкреплением. Дополнительные методы, такие как клонирование поведения, там не указаны, но также используются на практике. В реальных решениях обычно используются расширенные варианты или комбинации вышеперечисленных методов.
Q-обучение — это метод дискретных действий, не основанный на политике обучения. Расширение его применения на непрерывные пространства состояний/действий приводит к появлению таких методов, как глубокие Q-сети (DQN), которые заменяют Q-таблицу нейронной сетью.
В примере с сеткой Q-таблица содержит |S| × |A| = 40 × 4 = 160 элементов — вполне управляемо. Но для такой игры, как шахматы, пространство состояний превышает 10⁴⁴ позиций, что делает невозможным хранение или заполнение явной таблицы. В таких случаях для сжатия информации могут использоваться нейронные сети.

(s, a) , сеть принимает состояние в качестве входных данных и выдает Q-значения для всех действий, обобщая результаты на аналогичные состояния, которые она никогда раньше не видела.Практическое обучение с подкреплением в играх
Приведенный выше текст должен дать базовое представление о концепции агентов обучения с подкреплением. Конечно, на практике вы вряд ли будете реализовывать алгоритм обучения с подкреплением вручную.
Движок Unity предоставляет пакет RL-Agents, который можно использовать, например, для обучения автогонщиков. В передовых лабораториях проводятся масштабные исследования методов RL с использованием игровых сред, например, игры в прятки:
Модели, разработанные в этих лабораториях, уже превзошли лучших игроков мира в сложных настольных играх, таких как Го, в динамичных стратегических играх, таких как Starcraft и Dota, и даже в играх, требующих человеческого уровня общения, таких как Diplomacy.
Адам Стрек Посмотреть все работы Адама Стрека
Источник: towardsdatascience.com