
Узнайте, как наши новейшие модели искусственного интеллекта преобразуют двухмерные изображения товаров в захватывающие трехмерные впечатления для покупателей в интернете.
Ежедневно миллиарды людей совершают покупки онлайн, надеясь воссоздать лучшие моменты шопинга в обычном магазине. Увидеть что-то, что привлекло ваше внимание, взять это в руки и рассмотреть лично — это ключевой момент в нашем взаимодействии с товарами. Но воссоздать интуитивно понятный, практический характер покупок в магазине — задача непростая, и сделать это на экране может быть сложно. Мы знаем, что технологии могут помочь преодолеть этот разрыв, предоставляя ключевые детали одним движением пальца. Но создание таких онлайн-инструментов в больших масштабах может быть дорогостоящим и трудоемким процессом для бизнеса.
Для решения этой проблемы мы разработали новые методы генеративного искусственного интеллекта, позволяющие создавать высококачественные и удобные для покупки 3D-визуализации товаров всего лишь из трех изображений. Сегодня мы рады представить новейшее достижение, основанное на передовой модели генерации видео от Google — Veo. Эта технология уже позволяет создавать интерактивные 3D-изображения для широкого спектра категорий товаров в Google Shopping.
воспроизведение видео без звука зацикливание пауза видео без звука зацикливание включение звука видео выключение звука
Примеры 3D-визуализации продукции, созданной на основе фотографий.
Первое поколение: нейронные поля излучения (NeRFs)
В 2022 году исследователи из разных подразделений Google объединились для разработки технологий, которые сделали бы визуализацию продуктов более захватывающей. Первоначальные усилия были сосредоточены на использовании нейронных полей излучения (NeRF) для обучения трехмерному представлению продуктов с целью рендеринга новых ракурсов (т.е. синтеза новых ракурсов), таких как вращение на 360°, на основе пяти или более изображений продукта. Это потребовало решения множества подзадач, включая выбор наиболее информативных изображений, удаление нежелательного фона, прогнозирование трехмерных априорных данных, оценку положения камеры на основе разреженного набора изображений, ориентированных на объекты, и оптимизацию трехмерного представления продукта.
В том же году мы объявили об этом прорыве и запустили первый важный проект — интерактивные 360-градусные визуализации обуви в поиске Google. Хотя эта технология была многообещающей, она страдала от шума во входных сигналах (например, неточных положений камеры) и неоднозначности из-за недостатка входных изображений. Эта проблема стала очевидной при попытке воссоздать сандалии и туфли на каблуках, тонкую структуру и более сложную геометрию которых было трудно восстановить, имея всего несколько изображений.
Это заставило нас задуматься: могут ли недавние достижения в области генеративных диффузионных моделей помочь нам улучшить изученное 3D-представление?

В нашем подходе первого поколения для рендеринга новых ракурсов использовались нейронные поля излучения ( NeRF ), сочетающие в себе несколько 3D-техник, таких как NOCS для прогнозирования XYZ-координат, CamP для оптимизации камеры и Zip-NeRF для современного синтеза новых ракурсов из разреженного набора изображений.
Второе поколение: масштабирование с использованием априорного распределения диффузии, обусловленного углом обзора.
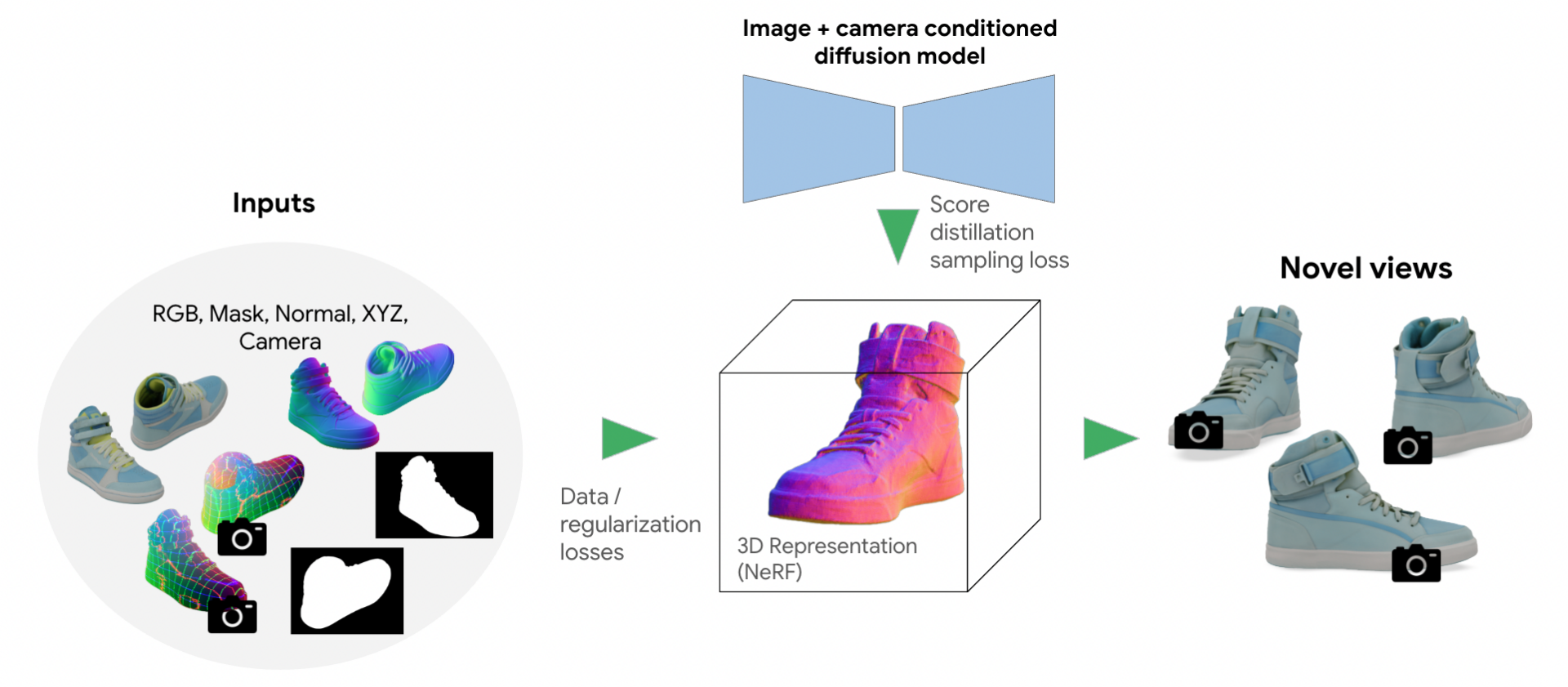
В 2023 году мы представили подход второго поколения, который использовал предварительное диффузионное моделирование, обусловленное ракурсом, для устранения ограничений первого подхода. Обусловленность ракурсом означает, что вы можете предоставить модели изображение верхней части обуви и спросить : «Как выглядит передняя часть этой обуви?» Таким образом, мы можем использовать модель диффузионного моделирования, обусловленного ракурсом, чтобы помочь предсказать, как выглядит обувь с любой точки зрения, даже если у нас есть только фотографии с ограниченного ракурса.
На практике мы используем вариант метода дистилляционной выборки оценок (SDS), впервые предложенный в DreamFusion. Во время обучения мы визуализируем 3D-модель из случайного ракурса камеры. Затем мы используем модель диффузии, обусловленную ракурсом, и доступные изображения поз для генерации целевого объекта из того же ракурса камеры. Наконец, мы вычисляем оценку, сравнивая визуализированное изображение и сгенерированный целевой объект. Эта оценка напрямую влияет на процесс оптимизации, уточняя параметры 3D-модели и повышая ее качество и реализм.
Этот подход второго поколения обеспечил значительные преимущества в масштабировании, позволив нам создавать 3D-модели многих моделей обуви, ежедневно просматриваемых в Google Shopping. Сегодня вы можете найти интерактивные 360° визуализации сандалий, туфель на каблуках, ботинок и других категорий обуви, совершая покупки в Google, и большинство из них созданы с помощью этой технологии!

Во втором поколении использовался подход, основанный на модели диффузии, обусловленной особенностями представления, с применением архитектуры TryOn . Модель диффузии выступает в качестве обученного априорного распределения, использующего метод дистилляционной выборки оценок, предложенный в DreamFusion, для повышения качества и точности новых представлений.
Третье поколение: Обобщение с помощью Veo
Наше последнее достижение основано на Veo, передовой технологии генерации видео от Google. Ключевое преимущество Veo заключается в его способности создавать видеоролики, которые передают сложные взаимодействия между светом, материалом, текстурой и геометрией. Мощная архитектура на основе диффузии и возможность тонкой настройки для решения различных многомодальных задач позволяют ему преуспевать в синтезе новых ракурсов.
Для тонкой настройки Veo с целью преобразования изображений товаров в единое 360-градусное видео, мы сначала подготовили набор данных, содержащий миллионы высококачественных синтетических 3D-моделей. Затем мы визуализировали 3D-модели с различных ракурсов камеры и условий освещения. Наконец, мы создали набор данных из парных изображений и видео и использовали Veo для генерации 360-градусных вращений на основе одного или нескольких изображений.
Мы обнаружили, что этот подход эффективно применим к широкому спектру категорий товаров, включая мебель, одежду, электронику и многое другое. Veo не только смог генерировать новые изображения, соответствующие имеющимся изображениям товаров, но и смог запечатлеть сложные взаимодействия освещения и материалов (например, блестящие поверхности), что представляло собой проблему для подходов первого и второго поколений.
воспроизведение видео без звука зацикливание пауза видео без звука зацикливание включение звука видео выключение звука
Подход третьего поколения основан на технологии Veo и позволяет создавать 360-градусные вращения из одного или нескольких изображений товаров.
Кроме того, этот подход третьего поколения позволил избежать необходимости оценки точных положений камеры на основе небольшого набора изображений объекта, что упростило задачу и повысило надежность. Тщательно настроенный подход Veo обладает высокой эффективностью — с помощью одного изображения можно создать реалистичное трехмерное представление объекта. Но, как и любая генеративная 3D-технология, Veo придется воспроизводить детали из невидимых ракурсов, например, заднюю часть объекта, если доступен только вид спереди. По мере увеличения количества входных изображений, Veo также повышает свою способность генерировать высококачественные и точные новые ракурсы. На практике мы обнаружили, что для улучшения качества трехмерных изображений и уменьшения искажений достаточно всего трех изображений, охватывающих большинство поверхностей объекта.
Заключение и перспективы на будущее
За последние несколько лет в области 3D-генеративного искусственного интеллекта достигнут огромный прогресс: от NeRF до моделей диффузии, обусловленной ракурсом, и теперь Veo. Каждая из этих технологий сыграла ключевую роль в том, чтобы сделать онлайн-шопинг более осязаемым и интерактивным. В перспективе мы с нетерпением ждём возможности продолжать расширять границы в этой области и помогать нашим пользователям делать онлайн-шопинг всё более приятным, информативным и увлекательным.
Благодарности
Эта работа стала возможной благодаря Филиппу Хенцлеру, Мэтью Берруссу, Мэтью Левину, Лори Чжан, Ке Ю, Чун-И Вэну, Джейсону Й. Чжану, Чанчангу Ву, Ире Кемельмахер-Шлизерман, Карлосу Эрнандесу, Кеунхонгу Парку и Рикардо Мартину-Бруалле. Мы благодарим Александра Холински, Бена Пула, Джона Баррона, Пратула Сринивасана, Ховарда Чжоу, Федерико Томбари и многих других из Google Labs, Google DeepMind и Google Shopping.
Источник: research.google