
RAG (Retrieval-Augmented Generation или генерация, дополненная поиском) — это метод искусственного интеллекта, сочетающий генеративную большую языковую модель (LLM) с внешней базой знаний для создания более точных, контекстно-зависимых и актуальных ответов. Принцип его работы заключается в том, что сначала извлекается релевантная информация из набора документов или источников данных, а затем эта информация передается в LLM для формирования окончательного ответа. Этот процесс позволяет модели выдавать более точные ответы, менее подверженные “галлюцинациям”, и ее можно обновлять без дорогостоящего переобучения.
Сегодня мы разберёмся, как собрать базовую RAG-систему на PHP (да, да, не надо удивляться) с помощью фреймворка Neuron AI. Это будет наш маленький proof-of-concept — минимально работающий, но вполне реальный пример.
Ну что, начнём генерацию?
1. Что вообще такое RAG и зачем оно нужно
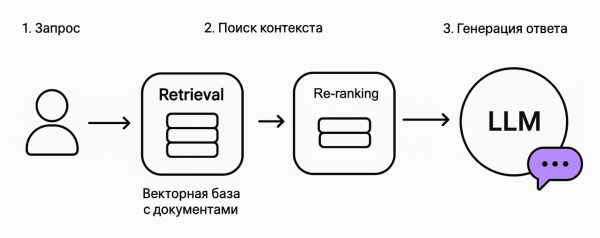
Итак, если коротко: RAG — это подход, при котором нейросеть не просто “фантазирует” ответ, а сначала ищет релевантные данные в базе (например, Wiki, документации, БД), а потом использует их при генерации ответа.
В классике жанра это два шага:
Retrieval — поиск нужных фрагментов (через векторный поиск).
Generation — генерация ответа с использованием найденных данных.
Типы RAG бывают разные — от простого “векторного поиска + LLM” до сложных систем с re-ranking, кэшированием контекста и цепочками размышлений (chain-of-thought, но об этом лучше не на проде). Мы не будем сильно углубляться в теорию, в Интернете и на Хабре есть огромное количество адекватных материалов, например: тут или тут, в том числе как и когда возник этот подход и Генерация дополненная поиском (спойлер — начал формироваться примерно в 2020 году)

Где это можно применять:
корпоративные чаты для поиска по документации;
голосовые ассистенты;
внутренние help-боты для службы поддержки;
ну и просто чтобы похвастаться коллегам.
2. Почему PHP и Neuron AI?
Хороший вопрос.
Можно, конечно, собрать RAG на Python — взять LangChain, LlamaIndex, Milvus, Chroma и почувствовать себя настоящим Data Scientist’ом. Примеров и туториалов полно. Но если у вас весь веб-проект уже на PHP, зачем тянуть Python только ради векторного поиска? Честно говоря, я не вижу в этом смысла — да и не хочу поднимать ещё один стек, если всё можно сделать «по-домашнему», на PHP.
Поэтому, тут на сцену выходит Neuron AI — лёгкий PHP-фреймворк, который добавляет в мир PHP то, что раньше казалось невозможным: работу с LLM, embeddings и даже собственный VectorStore. Раньше я уже писал про этот фреймворк и одна из причин написания этой статьи — обещание показать реальные примеры применения этого фреймворка.
Возможно, он не идеален, но зато прост, понятен и интегрируется в существующие PHP-приложения за пару строк. В духе старого доброго Laravel — но в данном случае для AI.
3. Что мы будем делать
Создадим AI-агента, который сможет отвечать на вопросы, используя вашу внутреннюю базу знаний.
Технически мы сделаем простую RAG-систему, которая:
создаёт векторное хранилище из документов;
ищет нужные куски по запросу (выбирает topK ближайших документов по векторному сходству);
генерирует ответ на основе найденного.
Представим, что у нас есть внутренняя база вроде Wiki или Confluence, и мы хотим, чтобы бот мог отвечать на вопросы по ней.
RAG для этого подходит идеально, особенно когда в команду приходит новичок, для которого ваша документация — это настоящая «Terra Incognita».
4. Процесс с примерами кода
4.1. Требования
PHP 8.2+
Composer
Neuron AI (composer require neuron-ai/neuron)
Ключ для LLM API (например, OpenAI)
4.2. Почему FileVectorStore
Для примера мы не будем поднимать никаких векторных баз данных типа Faiss или Pinecone. Нам достаточно обычного FileVectorStore — простой файловой базы, где всё хранится в файле .store.
Да, не масштабируется, но зато не ломается. Для демо — то что нужно. Впрочем, если у вас всего лишь пара тысяч документов, то вполне сойдёт и для локального использования в реальном проекте.
4.3. Установка и инициализация
Добавим необходимые пакеты
composer require neuron-ai/neuron composer require openai-php/laravel
Создаём структуру проекта:
/demo/ ├── store/ │ ├── docs/ ├── src/ │ ├── Commands/ │ ├── Classes/ └── index.php
4.4. Создание документной базы
В качестве примера поместим в нашу store/docs/ четыре демонстрационных документа в формате .md (он используется по умолчанию, но вы можете работать и другими форматами, такими как HTML, XML, PDF и т.д.). Эти четыре Markdown-документа, содержат описание компании, культуру, услуги и техническую экспертизу.
company-culture.md# Linx Team — Company Culture & Values ## Core Values ### Innovation We embrace new technologies and methodologies. Our team is constantly learning and experimenting with cutting-edge solutions to stay ahead of industry trends. ### Quality We are committed to delivering high-quality code and products. Every line of code is reviewed, tested, and optimized for performance and maintainability. ### Collaboration We believe in the power of teamwork. Our collaborative culture encourages open communication, knowledge sharing, and mutual support. ### Continuous Learning Professional growth is important to us. We invest in our team’s development through training, conferences, and mentorship programs. ### Transparency We maintain open and honest communication with our clients and team members. Clear expectations and regular updates ensure successful partnerships. ## Work Environment ### Remote-Friendly We offer flexible work arrangements with options for remote work, allowing our team to maintain work-life balance. ### Modern Office Our N city office is equipped with modern amenities and collaborative spaces for team members who prefer working on-site. ### Team Events Regular team building activities, workshops, and social events foster strong relationships and company culture. ## Professional Development ### Training Programs We provide access to online courses, certifications, and training programs to help team members advance their skills. ### Mentorship Experienced team members mentor junior developers, fostering knowledge transfer and career growth. ### Conference Attendance We support team members attending industry conferences and speaking at events. ### Open Source Contributions We encourage and support contributions to open source projects, giving back to the community. ## Benefits ### Competitive Compensation We offer competitive salaries and benefits packages. ### Health Insurance Comprehensive health insurance coverage for employees and their families. ### Flexible Hours Flexible working hours that accommodate personal needs while meeting project deadlines. ### Professional Development Budget Annual budget for training, courses, and professional development.company-overview.md# Linx Team — Company Overview ## About Us Linx Team is a leading software development company specializing in web and mobile applications. Founded in 2015, we have established ourselves as a trusted partner for businesses seeking innovative technology solutions. ## Our Location Based in city N, in Country, we serve clients globally with a diverse team of talented professionals. ## Team Size We have many over 27 employees and 2 managers working across multiple departments: — Software Development — UI/UX Design — Project Management — Quality Assurance — DevOps and Infrastructure ## Mission Our mission is to deliver high-quality, scalable software solutions that drive business growth and innovation for our clients. ## Vision We envision a future where technology seamlessly integrates with business processes, enabling organizations to achieve their full potential. services-portfolio.md# Linx Team — Services & Portfolio ## Services Offered ### Custom Software Development We build tailored software solutions from scratch, designed specifically for your business needs. Our team handles everything from requirements analysis to deployment and maintenance. ### Web Application Development Creating responsive, scalable web applications using modern frameworks and best practices. We specialize in both frontend and backend development. ### Mobile Application Development Developing native and cross-platform mobile applications for iOS and Android that provide excellent user experiences. ### Consulting Services Our experienced consultants provide strategic guidance on technology architecture, system design, and technology stack selection. ### Staff Augmentation We provide skilled developers and specialists to augment your existing team, helping you scale quickly without long-term commitments. ### DevOps & Infrastructure Managing cloud infrastructure, implementing CI/CD pipelines, and optimizing system performance and reliability. ## Industries We Serve ### FinTech Building secure financial applications with compliance and regulatory requirements. ### E-Commerce Creating high-performance online stores with payment processing and inventory management. ### Healthcare Developing HIPAA-compliant healthcare solutions with patient data protection. ### SaaS Building scalable Software-as-a-Service platforms for various business domains. ### Enterprise Software Developing complex enterprise solutions for large organizations. ## Project Success — **100+ Projects Delivered** — Successfully completed projects for clients worldwide — **Client Retention Rate** — High percentage of clients return for additional projects — **On-Time Delivery** — Consistent track record of meeting project deadlines — **Quality Assurance** — Rigorous testing ensures bug-free deployments technical-expertise.md# Linx Team — Technical Expertise ## Core Technologies ### Backend Development — **Laravel** — PHP framework for building robust web applications — **Node.js** — JavaScript runtime for scalable server-side applications — **Python** — For data processing and automation — **PostgreSQL** — Advanced relational database — **MongoDB** — NoSQL database for flexible data structures ### Frontend Development — **React** — Modern JavaScript library for building user interfaces — **Vue.js** — Progressive JavaScript framework — **TypeScript** — Typed superset of JavaScript — **Tailwind CSS** — Utility-first CSS framework — **Next.js** — React framework with server-side rendering ### Cloud & DevOps — **AWS** — Amazon Web Services cloud platform — **Docker** — Containerization technology — **Kubernetes** — Container orchestration — **CI/CD Pipelines** — Continuous integration and deployment — **Infrastructure as Code** — Terraform and CloudFormation ### Mobile Development — **React Native** — Cross-platform mobile development — **Flutter** — Google’s mobile framework — **iOS and Android** — Native development capabilities ## Best Practices — Clean Code Architecture — Test-Driven Development (TDD) — Agile Methodologies — Security-First Approach — Performance Optimization
4.5. Создание VectorStore
Создадим файл src/Classes/PopulateVectorStore.php:
PopulateVectorStore.phpnamespace AppdemosrcClasses; require_once __DIR__ . ‘/../../../../vendor/autoload.php’; use NeuronAIRAGDataLoaderFileDataLoader; use OpenAIFactory; class PopulateVectorStore { public static function populate(): void { $vectorDir = __DIR__ . ‘/../../store’; $storeFile = $vectorDir . ‘/demo.store’; $metaFile = $vectorDir . ‘/demo.meta.json’; // Ensure directory exists if (!is_dir($vectorDir)) { mkdir($vectorDir, 0755, true); } // Clear existing store file_put_contents($storeFile, »); // Initialize OpenAI client $apiKey ='<your-OPENAI_API_KEY-here>’; if (!is_string($apiKey) || trim($apiKey) === ») { throw new RuntimeException(‘OpenAI API key not configured. Ensure OPENAI_API_KEY is set.’); } $client = (new Factory()) ->withApiKey($apiKey) ->make(); $model = ‘text-embedding-3-small’; // Probe expected dimension once $expectedDim = 1536; // Docs $documents = FileDataLoader::for($vectorDir . ‘/docs’)->getDocuments(); $written = 0; // Generate embeddings and write to store foreach ($documents as $document) { $content = $document->getContent(); // Get embedding from OpenAI try { $response = $client->embeddings()->create([ ‘model’ => $model, ‘input’ => $content, ‘dimensions’ => $expectedDim, ]); // SDK v0.12+ exposes embeddings via `$response->embeddings` if (isset($response->embeddings[0]->embedding)) { $embedding = $response->embeddings[0]->embedding; } else { // Fallback for array casting if SDK shape changes $arr = method_exists($response, ‘toArray’) ? $response->toArray() : []; if (isset($arr[‘data’][0][’embedding’])) { $embedding = $arr[‘data’][0][’embedding’]; } else { throw new RuntimeException(‘Unable to parse embedding from OpenAI response’); } } } catch (Throwable $e) { throw new RuntimeException(‘Failed to generate embedding: ‘ . $e->getMessage()); } // Normalize and validate embedding if (!is_array($embedding)) { echo «! Skipped document due to invalid embedding type.n»; continue; } $embedding = array_map(static function ($v) { return is_numeric($v) ? (float)$v : 0.0; }, $embedding); if (count($embedding) !== $expectedDim) { echo «! Skipped document due to dimension mismatch (got » . count($embedding) . «, expected $expectedDim).n»; continue; } // Write as JSON line to store file (strict JSONL) // FileVectorStore expects all fields at top level $jsonLine = json_encode([ ’embedding’ => $embedding, ‘content’ => $content, ‘sourceType’ => $document->getSourceType(), ‘sourceName’ => $document->getSourceName(), ‘id’ => md5($content), ‘metadata’ => [], ], JSON_UNESCAPED_SLASHES | JSON_UNESCAPED_UNICODE); file_put_contents($storeFile, $jsonLine . «n», FILE_APPEND); $written++; echo «✓ Added embedding ($written) for: » . $storeFile . » | » . str_replace(«n», ‘ ‘, substr(trim($content), 0, 70)) . «…n»; } // Write metadata file for consistency checks $meta = [ ‘model’ => $model, ‘dimension’ => $expectedDim, ‘generatedAt’ => date(DATE_ATOM), ‘count’ => $written, ]; file_put_contents($metaFile, json_encode($meta, JSON_UNESCAPED_SLASHES | JSON_UNESCAPED_UNICODE | JSON_PRETTY_PRINT)); echo «n✓ Vector store populated with $written documents (dimension: $expectedDim)n»; } }
Для запуска вызовем index.php со следующим кодом:
<?php use AppdemosrcClassesPopulateVectorStore; require_once __DIR__ . ‘/src/Classes/PopulateVectorStore.php’; PopulateVectorStore::populate();
В результате мы увидим в окне терминала следующее:
php app/demo/index.php ✓ Added embedding (1) for: /app/demo/src/Commands/../../store/demo.store | # Linx Team — Company Culture & Values ## Core Values ### Innovation… ✓ Added embedding (2) for: /app/demo/src/Commands/../../store/demo.store | ## Work Environment ### Remote-Friendly We offer flexible work arrang… ✓ Added embedding (3) for: /app/demo/src/Commands/../../store/demo.store | ## Benefits ### Competitive Compensation We offer competitive salarie… ✓ Added embedding (4) for: /app/demo/src/Commands/../../store/demo.store | # Linx Team — Company Overview ## About Us Linx Team is a leading sof… ✓ Added embedding (5) for: /app/demo/src/Commands/../../store/demo.store | # Linx Team — Services & Portfolio ## Services Offered ### Custom So… ✓ Added embedding (6) for: /app/demo/src/Commands/../../store/demo.store | ### DevOps & Infrastructure Managing cloud infrastructure, implementin… ✓ Added embedding (7) for: /app/demo/src/Commands/../../store/demo.store | # Linx Team — Technical Expertise ## Core Technologies ### Backend D… ✓ Added embedding (8) for: /app/demo/src/Commands/../../store/demo.store | js** — React framework with server-side rendering ### Cloud & DevOps … ✓ Vector store populated with 8 documents (dimension: 1536)
у нас создалось 2 новых файла: demo.meta.json и demo.store
Давайте заглянем в demo.meta.json — тут всё понятно
{ «model»: «text-embedding-3-small», «dimension»: 1536, «generatedAt»: «2025-11-15T13:28:53+00:00», «count»: 8 }
a вот в demo.store мы увидим следующее:
{«embedding»:[-0.02263086,-0.007472924,0.029841794,…],»content»:»# Linx Team — … «,»sourceType»:»files»,»sourceName»:»company-culture.md»,»id»:»28b40662dad319d6f5718881af03283b»,»metadata»:[]} {«embedding»:[-0.023948364,0.009718814,0.06337647,…],»content»:»## Work Enviro … «,»sourceType»:»files»,»sourceName»:»company-culture.md»,»id»:»b96cd133b0df26e64b95acdad75c87dd»,»metadata»:[]} {«embedding»:[-0.018617272,0.00053190015,0.095444225,…],»content»:»## Benefitsnn### …»,»sourceType»:»files»,»sourceName»:»company-culture.md»,»id»:»42041e1af0580a58ae07d6523649b1a9″,»metadata»:[]} {«embedding»:[-0.04209091,-0.006933485,0.03687242,…],»content»:»# Linx Team — Company …»,»sourceType»:»files»,»sourceName»:»company-overview.md»,»id»:»8622e016e3fbeccc8dc10bf9a3a851a6″,»metadata»:[]} {«embedding»:[-0.026189856,-0.0032917524,0.05449412,…],»content»:»# Linx Team — Services …»,»sourceType»:»files»,»sourceName»:»services-portfolio.md»,»id»:»acc30742cf9f55588db5275c4feba183″,»metadata»:[]} {«embedding»:[0.0018354928,-0.009989895,0.04954025,…],»content»:»### DevOps & …»,»sourceType»:»files»,»sourceName»:»services-portfolio.md»,»id»:»d32de0136fdd56991a8ab738c49558a2″,»metadata»:[]} {«embedding»:[-0.06210507,-0.015794381,0.038876604,…],»content»:»# Linx Team — …»,»sourceType»:»files»,»sourceName»:»technical-expertise.md»,»id»:»dff18ab4ded5f65154cdd6e81c49318c»,»metadata»:[]} {«embedding»:[-0.02210143,0.016823476,0.038901344,…],»content»:»js** — React framework …»,»sourceType»:»files»,»sourceName»:»technical-expertise.md»,»id»:»a167473a1d4eeac021fbe9bf2ccd0726″,»metadata»:[]}
Каждая строчка здесь это json в формате
{ «embedding»:[…], «content»:»», «sourceType»:»files», «sourceName»:»company-culture.md», «id»:»28b40662dad319d6f5718881af03283b», «metadata»:[] }
где в embedding находится векторное представление нашего файла, в content — его оригинальный текст и т.д.
Хм… почему же из 4-х документов было создано 8 строк?
Дело в том, документы режутся на чанки (фрагменты) перед эмбеддингом. Вектор хранится не для всего файла целиком, а для каждого фрагмента текста, чтобы поиск был точнее. У нас было 4 исходных файла, но после разбиения получилось 8 фрагментов — значит, каждый файл дал 1–3 чанка (по заголовкам/секциям или по длине).
Почему так делают
LLM и эмбеддинги работают лучше, когда им дают короткие, цельные куски (параграф/секция), а не километр полотна.
У моделей есть лимиты по токенам; большой документ нельзя нормально “векторизовать” одним кусом.
При запросе RAG ищет только релевантные куски, а не весь файл — меньше шума, выше точность.
Почему используем «dimension»: 1536? Тут всё просто — мы в примере используем модель text-embedding-3-small от OpenAI, а она всегда выдаёт векторы длиной 1536. Это зашито в саму модель. В других моделях могут быть другие значения.
4.6. Создание ChatBot
Теперь создадим самого агента — src/Commands/ChatBot.php:
ChatBot.php<?php namespace AppdemosrcCommands; require_once __DIR__ . ‘/../../../../vendor/autoload.php’; use NeuronAIProvidersAIProviderInterface; use NeuronAIProvidersOpenAIOpenAI; use NeuronAIRAGEmbeddingsEmbeddingsProviderInterface; use NeuronAIRAGEmbeddingsOpenAIEmbeddingsProvider; use NeuronAIRAGRAG; use NeuronAIRAGVectorStoreFileVectorStore; use NeuronAIRAGVectorStoreVectorStoreInterface; class ChatBot extends RAG { private string $apiKey ='<your-OPENAI_API_KEY-here>’; private string $model = ‘gpt-4o-mini’; protected function provider(): AIProviderInterface { if (!$this->apiKey) { throw new Exception(‘OPENAI_API_KEY environment variable is not set’); } return new OpenAI( $this->apiKey, $this->model, ); } protected function embeddings(): EmbeddingsProviderInterface { if (!$this->apiKey) { throw new Exception(‘OPENAI_API_KEY environment variable is not set’); } return new OpenAIEmbeddingsProvider( key: $this->apiKey, model: ‘text-embedding-3-small’, dimensions: 1536 ); } protected function vectorStore(): VectorStoreInterface { $vectorDir = __DIR__ . ‘/../../store’; // Ensure the vectors directory exists if (!is_dir($vectorDir)) { mkdir($vectorDir, 0755, true); } // Ensure the store file exists with at least one empty line to prevent parsing errors $storeFile = $vectorDir . ‘/demo.store’; if (!file_exists($storeFile) || filesize($storeFile) === 0) { // Create an empty store file — FileVectorStore will populate it when documents are added file_put_contents($storeFile, »); } return new FileVectorStore( directory: $vectorDir, name: ‘demo’, topK: 3 ); } }
Переделаем немного наш index.php файл.
<?php use AppdemosrcClassesPopulateVectorStore; use AppdemosrcCommandsChatBot; use NeuronAIChatMessagesUserMessage; require_once __DIR__ . ‘/../../vendor/autoload.php’; // Populate the vector store if it doesn’t exist $storeFile = __DIR__ . ‘/store/demo.store’; if (!file_exists($storeFile) || filesize($storeFile) === 0) { PopulateVectorStore::populate(); echo «Vector store populated successfully.n»; } else { echo «Vector store found, start handling…n»; } $chatBot = ChatBot::make(); $response = $chatBot->chat( new UserMessage(‘How many employees and managers does the company have?’) ); echo «n» . $response->getContent() . «n»;
Если всё прошло успешно — бот ответит примерно так:
Vector store found, start handling…
The company has over 27 employees and 2 managers, making a total of more than 29 team members.
Ну как? Неплохо, да? Наш чат-бот не только нашёл соответствующие документы, передал их в LLM, но вернул правильный ответ, подсчитав сколько всего работников в нашей компании.
Важный момент.
Обратите внимание на аргумент topK: 3 — при вызове FileVectorStore
Параметр topK (или иногда пишут top_k) — это просто число, которое определяет, сколько наиболее похожих (релевантных) документов нужно вернуть из векторного стора при поиске. Это означает, что при каждом запросе к векторной базе (similaritySearch() или retrieve()), система выберет 3 ближайших вектора (по косинусному сходству или другому методу) и вернёт их как контекст для LLM.
Итак, после всего окончательная структура проекта выглядит вот так:
/demo/ ├── store/ │ ├── docs/ │ │ ├── company-culture.md │ │ ├── company-overview.md │ │ ├── services-portfolio.md │ │ ├── technical-expertise.md │ ├── demo.meta.json │ ├── demo.store ├── src/ │ ├── Commands/ │ │ ├── ChatBot.php │ ├── Classes/ │ │ ├── PopulateVectorStore.php └── index.php
5. Что можно улучшить
Это, как вы понимаете, был всего лишь базовый пример. Теперь рассмотрим, что можно улучшить.
Хранение данных — вместо файлов можно подключить PostgreSQL, Pinecone или Qdrant.
Автоматическое обновление базы — пусть скрипт сам находит и индексирует новые страницы из нашей Wiki или Confluence.
Кэширование — чтобы часто задаваемые вопросы не пересчитывались заново.
Логирование запросов — полезно для отладки и аналитики.
6. Продвинутая версия: добавляем re-ranking
Если хочется, чтобы бот выбирал ответы точнее, можно добавить re-ranking — пересортировку найденных документов по релевантности.
Neuron AI это позволяет: просто используйте модуль Reranker с моделью типа bge-reranker-base.
И вы удивитесь, насколько “умнее” станет ваш бот.
7. Модульная архитектура: когда и зачем
Если RAG — это просто вспомогательная фича, не нужно плодить модули.
Но если проект растёт, стоит вынести:
VectorStoreService
EmbeddingPipeline
RAGPipeline
ChatController
Так вы сможете менять компоненты по отдельности: например, перейти с OpenAI на Ollama или с файлового хранилища на Qdrant — без боли.
8. Итоги
RAG — это не магия, а вполне конкретный паттерн.
Neuron AI даёт PHP-разработчикам возможность наконец-то “поиграть” с нейросетями без пересадки на Python и делает это довольно просто — без серверов, без Docker, без танцев с бубнами.
Да, FileVectorStore — это игрушка, но для локальной демки и старта этого хватает.
Главное — понять принцип, а дальше уже можно внедрить эту идею в вашем любимом фреймворке и двигаться к чему-то более серьёзному.
Источник: habr.com



















