От пиков плотности до разреженных функций принятия решений
Делиться

После вчерашней статьи об SVM следующим логичным шагом станет Kernel SVM.
На первый взгляд, это выглядит как совершенно другая модель. Обучение происходит в двойственной форме, мы перестаём говорить о наклоне и точке пересечения, и внезапно всё сводится к «ядру».
В сегодняшней статье я научу понятие «ядро» наглядным образом, показав, что оно на самом деле делает.
Существует множество хороших способов представить Kernel SVM. Если вы читали мои предыдущие статьи, вы знаете, что я предпочитаю начинать с чего-то простого, что вам уже известно.
Классический способ представить SVM с ядром выглядит так: SVM — это линейная модель. Если связь между признаками и целевой переменной нелинейна, прямая линия не сможет хорошо разделить классы. Поэтому мы создаём новые признаки. Полиномиальная регрессия — это тоже линейная модель, мы просто добавляем полиномиальные признаки (x, x², x³, …). С этой точки зрения, полиномиальное ядро неявно выполняет полиномиальную регрессию, а ядро RBF можно рассматривать как использующее бесконечный ряд полиномиальных признаков…
Возможно, в другой раз мы пойдем этим путем, но сегодня мы выберем другой: начнем с KDE .
Да, оценка плотности ядра .
Давайте начнём.
1. KDE как сумма индивидуальных плотностей
Я уже упоминал KDE в статье о LDA и QDA, и тогда сказал, что мы будем использовать его позже. Сейчас самое время.
Мы видим слово «kernel» в KDE, и мы также видим его в Kernel SVM . Это не совпадение, существует реальная связь.
Идея KDE проста:
Вокруг каждой точки данных мы размещаем небольшое распределение (ядро).
Затем мы суммируем все эти индивидуальные плотности , чтобы получить глобальное распределение.
Запомните эту идею. Она станет ключом к пониманию Kernel SVM.

Мы также можем настроить один параметр, чтобы контролировать степень сглаживания глобальной плотности, от очень локального до очень сглаженного, как показано на GIF-анимации ниже.

Как вы знаете, KDE — это модель, основанная на расстоянии или плотности, поэтому здесь мы собираемся установить связь между двумя моделями из двух разных семейств.
2. Превращение KDE в модель
Теперь мы используем ту же самую идею для построения функции вокруг каждой точки, и затем эту функцию можно использовать для классификации.
Помните, что задача классификации с использованием моделей, основанных на весах, сначала является задачей регрессии, поскольку значение y всегда рассматривается как непрерывная величина? Классификацию мы выполняем только после получения функции принятия решения, или f(x).
2.1. (По-прежнему) с использованием простого набора данных
Однажды меня спросили, почему я всегда использую около 10 точек данных для объяснения машинного обучения, на что я ответил, что это бессмысленно.
Я категорически не согласен.
Если кто-то не может объяснить, как работает модель машинного обучения, используя 10 точек (или меньше) и одну единственную характеристику, значит, он на самом деле не понимает, как работает эта модель.
Так что для вас это не станет сюрпризом. Да, я по-прежнему буду использовать этот очень простой набор данных, который я уже использовал для логистической регрессии и SVM. Я знаю, что этот набор данных линейно разделим, но интересно сравнить результаты моделей.
А еще я создал еще один набор данных с точками, которые не являются линейно разделимыми, и визуализировал работу модели на основе ядра.

2.2. Ядро RBF, центрированное на точках
Теперь применим идею KDE к нашему набору данных.
Для каждой точки данных мы строим колоколообразную кривую с центром в точке, соответствующей её значению x. На данном этапе нас пока не интересует классификация. Мы делаем только одну простую вещь: создаём локальную колоколообразную кривую вокруг каждой точки.
Этот колокол имеет гауссову форму, но здесь он обозначен специальным названием: RBF , что означает радиальная базисная функция.
На этом рисунке мы видим ядро радиальной базисной функции (гауссово ядро), центрированное в точке x₇.

Название звучит технически, но на самом деле идея очень проста.
Как только вы начинаете воспринимать RBF как «колокола, основанные на расстоянии», это название перестаёт быть загадочным.
Как это прочитать интуитивно
- x — это любая точка на оси x.
- x₇ — это центр колокола (седьмая точка).
- γ (гамма) регулирует ширину колокола.
Таким образом, колокол достигает своего максимума точно в этой точке.
По мере удаления x от x₇ значение плавно уменьшается до 0.
Роль γ (гамма)
- Малый γ означает широкую колоколообразную форму (плавное, глобальное влияние).
- Большое значение γ означает узкий колокол (очень локальное влияние).
Таким образом, γ играет ту же роль, что и ширина полосы пропускания в KDE.
На данном этапе ничего еще не объединено. Мы просто строим элементарные блоки.
2.3. Сочетание звонков с обозначениями классов.
На приведенных ниже рисунках вы сначала видите отдельные колокола, каждый из которых центрирован на определенной точке данных.
Как только это станет ясно, мы перейдем к следующему шагу: соединению колокольчиков .
На этот раз каждый колокольчик умножается на соответствующее ему обозначение yi.
В результате одни колокола добавляются, а другие убираются, создавая воздействия в двух противоположных направлениях.
Это первый шаг к созданию функции классификации.

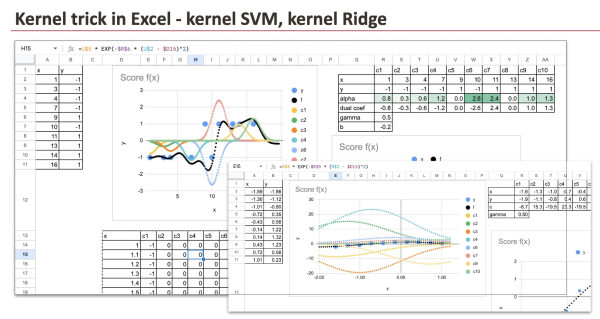
И мы можем увидеть все компоненты каждой точки данных, которые суммируются в Excel для получения итогового результата.

Это уже очень похоже на KDE.
Но мы еще не закончили.
2.4. От колоколов одинакового веса к колоколам утяжеленного веса
Ранее мы говорили, что SVM относится к семейству моделей, основанных на весах . Поэтому следующим естественным шагом является введение весов .
В моделях, основанных на расстоянии, одним из главных ограничений является то, что при вычислении расстояний все признаки рассматриваются как одинаково важные. Конечно, мы можем масштабировать признаки, но это часто делается вручную и является несовершенным решением.
Здесь мы используем другой подход.
Вместо того чтобы просто суммировать все звонки, мы присваиваем каждой точке данных вес и умножаем каждый звонок на этот вес.

На данном этапе модель по-прежнему линейна , но линейна в пространстве ядер , а не в исходном пространстве входных данных.
Чтобы сделать это более наглядным, мы можем предположить, что коэффициенты αi уже известны, и сразу же построить график полученной функции в Excel. Каждая точка данных вносит свой собственный взвешенный вклад, и итоговый результат представляет собой просто сумму всех этих вкладов.

Если мы применим это к набору данных с нелинейно разделимой границей, мы ясно увидим, что делает Kernel SVM: он подгоняет данные, комбинируя локальные факторы, вместо того чтобы пытаться нарисовать одну прямую линию.

3. Функция потерь: с чего на самом деле начинается работа SVM.
До сих пор мы говорили только о базовой части модели. Мы построили колоколообразные структуры, присвоили им веса и объединили их.
Но наша модель называется Kernel SVM , а не просто «ядерная модель».
Часть, относящаяся к методу SVM, формируется на основе функции потерь .
Как вы, возможно, уже знаете, SVM определяется функцией потерь Hinge Loss .
3.1 Потери шарнира и опорные векторы
Потери в шарнире обладают очень важным свойством.
Если точка:
- правильно классифицированы и
- достаточно далеко от границы принятия решения,
тогда его потери равны нулю .
В результате этого его коэффициент αi становится равным нулю .
Осталось активными лишь несколько точек данных.
Эти точки называются опорными векторами .
Таким образом, несмотря на то, что изначально на каждую точку данных приходился один колокол , в финальной модели сохранилось лишь несколько колоколов .
В приведенном ниже примере видно, что для некоторых точек (например, точек 5 и 8) коэффициент αi равен нулю. Эти точки не являются опорными векторами и не вносят вклад в функцию принятия решения.
В зависимости от того, насколько строго мы наказываем нарушения (с помощью параметра C), количество опорных векторов может увеличиваться или уменьшаться.
Это является важнейшим практическим преимуществом метода опорных векторов (SVM).
Когда набор данных большой, хранение одного параметра на каждую точку данных может быть дорогостоящим. Благодаря функции потерь Hinge Loss, SVM создает разреженную модель , в которой сохраняется лишь небольшое подмножество точек.

3.2 Регрессия с использованием ядра: одинаковые ядра, разные функции потерь
Если мы сохраним те же ядра, но заменим функцию потерь типа «шарнир» на квадратичную функцию потерь, мы получим регрессию с гребнем на основе ядра :
Те же самые ядра.
Те же самые колокола.
Другая потеря.
Это приводит к очень важному выводу:
Ядра определяют представление.
Функция потерь определяет модель.
При использовании метода регрессии с ядром модель должна хранить все точки обучающих данных .
Поскольку квадратичная функция потерь не обнуляет ни один коэффициент, каждая точка данных сохраняет ненулевой вес и вносит свой вклад в прогнозирование.
В отличие от этого, метод Kernel SVM создает разреженное решение: сохраняются только опорные векторы, все остальные точки исчезают из модели.

3.3 Быстрая связь с LASSO
Здесь прослеживается интересная параллель с LASSO .
В линейной регрессии LASSO использует L1-штраф для исходных коэффициентов. Этот штраф способствует разреженности, и некоторые коэффициенты становятся равными нулю.
В методе опорных векторов (SVM) функция потерь «шарнир» играет аналогичную роль, но в другой области.
- LASSO создает разреженность в исходных коэффициентах.
- Метод опорных векторов (SVM) создает разреженность в двойственных коэффициентах αi.
Разные механизмы, один и тот же эффект: сохраняются только важные параметры .
Заключение
Kernel SVM — это не только ядро операционной системы.
- Ядра создают богатое нелинейное представление.
- Функция потерь шарнира выбирает только необходимые точки данных.
В результате получается модель, которая одновременно является гибкой и разреженной , поэтому SVM остается мощным и элегантным инструментом.
Завтра мы рассмотрим ещё одну модель, учитывающую нелинейность. Следите за обновлениями.
Источник: towardsdatascience.com