Понимание многоклассовой классификации с использованием Softmax
Делиться

С помощью логистической регрессии мы научились классифицировать объекты на два класса.
А что произойдет, если классов будет больше двух?
Регрессия Softmax — это просто многоклассовое расширение этой идеи. И мы обсудим эту модель в 14-й день моего «Рождественского календаря» по машинному обучению (перейдите по этой ссылке, чтобы получить всю информацию о подходе и используемых файлах).
Вместо одного показателя мы теперь создаём один показатель для каждого класса. Вместо одной вероятности мы применяем функцию Softmax для получения вероятностей, сумма которых равна 1.
Понимание модели Softmax
Прежде чем обучать модель, давайте сначала разберемся, что это за модель .
Регрессия Softmax пока не связана с оптимизацией.
В первую очередь речь идет о том, как вычисляются прогнозы .
Небольшой набор данных, содержащий 3 класса.
Рассмотрим небольшой набор данных с одним признаком x и тремя классами.
Как мы уже говорили, целевую переменную y не следует рассматривать как числовую.
Это представляет собой категории, а не количества.
Распространенный способ представления этого — однократное кодирование (one-hot encoding) , где каждый класс представлен своим собственным индикатором.
С этой точки зрения, регрессию Softmax можно рассматривать как три логистические регрессии, работающие параллельно , по одной на каждый класс.
Небольшие наборы данных идеально подходят для обучения.
Вы можете увидеть каждую формулу, каждое значение и то, как каждая часть модели влияет на конечный результат.

Описание модели
Так что же это за модель, собственно?
Оценка за класс
В логистической регрессии оценка модели представляет собой простое линейное выражение: оценка = a * x + b.
Функция Softmax Regression делает то же самое, но для каждого класса используется один показатель:
score_0 = a0 * x + b0
score_1 = a1 * x + b1
score_2 = a2 * x + b2
На данном этапе эти баллы представляют собой просто реальные числа.
Это ещё не вероятности.
Преобразование оценок в вероятности: шаг Softmax
Функция Softmax преобразует три значения в три вероятности. Каждая вероятность положительна, и сумма всех трех равна 1.
Вычисления выполняются напрямую:
- Возведите каждое значение в степень.
- Вычислите сумму всех экспоненциальных функций.
- Разделите каждую экспоненту на эту сумму.
Это даёт нам значения p0, p1 и p2 для каждой строки.
Эти значения отражают степень достоверности модели для каждого класса.
На данном этапе модель полностью определена.
Обучение модели будет заключаться в простой корректировке коэффициентов ak и bk таким образом, чтобы эти вероятности максимально соответствовали наблюдаемым классам.

Визуализация модели Softmax
На данном этапе модель полностью определена.
У нас есть:
- один линейный балл на класс
- Шаг Softmax, который преобразует эти оценки в вероятности.
Обучение модели заключается в простой корректировке коэффициентов aka_kak и bkb_kbk таким образом, чтобы эти вероятности максимально соответствовали наблюдаемым классам.
После того как коэффициенты будут найдены, мы можем визуализировать поведение модели .
Для этого мы берем диапазон входных значений, например, x от 0 до 7, и вычисляем: score0, score1, score2 и соответствующие вероятности p0, p1, p2.
Построение графика этих вероятностей дает три плавные кривые, по одной для каждого класса.

Результат очень наглядный.
При малых значениях x вероятность попадания в класс 0 высока.
По мере увеличения x эта вероятность уменьшается, в то время как вероятность принадлежности к классу 1 возрастает.
При больших значениях x вероятность принадлежности к классу 2 становится доминирующей.
При каждом значении x сумма трех вероятностей равна 1.
Модель не принимает поспешных решений; вместо этого она выражает степень своей уверенности в каждом классе.
Этот график позволяет легко понять поведение алгоритма Softmax-регрессии.
- Вы можете увидеть, как модель плавно переходит из одного класса в другой.
- Границы принятия решений соответствуют точкам пересечения кривых вероятности.
- Логика модели становится видимой, а не абстрактной.
Это одно из ключевых преимуществ построения модели в Excel:
Вы не просто вычисляете прогнозы, вы можете увидеть, как работает модель .
Кросс-энтропийная потеря и градиентный спуск
Теперь, когда модель определена, нам нужен способ оценить её качество и метод улучшения её коэффициентов .
На обоих этапах используются идеи, которые мы уже рассматривали в контексте логистической регрессии.
Оценка модели: функция потерь кросс-энтропии.
В алгоритме Softmax Regression используется та же функция потерь , что и в логистической регрессии.
Для каждой точки данных мы смотрим на вероятность, присвоенную правильному классу , и берем отрицательный логарифм:
потеря = – log (p истинного класса)
Если модель присваивает правильным классам высокую вероятность, то потери невелики.
Если присваивается низкая вероятность, потери становятся значительными.
В Excel это очень просто реализовать.
Мы выбираем правильную вероятность на основе значения y и применяем логарифм:
loss = -LN( CHOOSE(y + 1, p0, p1, p2) )
Наконец, мы вычисляем средний убыток по всем строкам.
Именно этот средний размер убытка мы хотим минимизировать.

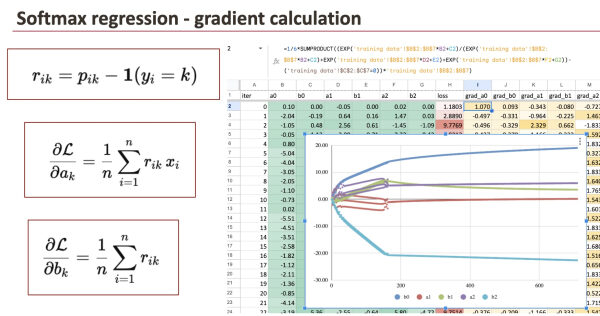
Вычисление остатков
Для обновления коэффициентов мы начинаем с вычисления остатков , по одному для каждого класса.
Для каждой строки:
- residual_0 = p0 минус 1, если y равно 0, в противном случае — 0.
- residual_1 = p1 минус 1, если y равно 1, в противном случае — 0.
- residual_2 = p2 минус 1, если y равно 2, в противном случае — 0.
Другими словами, чтобы получить правильный результат, мы вычитаем 1.
Для остальных классов мы вычитаем 0.
Эти остатки показывают, насколько предсказанные вероятности отличаются от ожидаемых.
Вычисление градиентов
Градиенты получаются путем объединения остатков со значениями признаков.
Для каждого класса k:
- Градиент функции ak равен среднему значению остатка k * x.
- Градиент bk равен среднему значению residual_k.
В Excel это реализуется с помощью простых формул, таких как SUMPRODUCT и AVERAGE.
На данном этапе все предельно ясно:
Вы видите остатки, градиенты и вклад каждой точки данных.

Обновление коэффициентов
После того как градиенты известны, мы обновляем коэффициенты, используя градиентный спуск.
Этот шаг идентичен тому, что мы видели ранее, для логистической или линейной регрессии.
Единственное отличие заключается в том, что теперь мы обновляем шесть коэффициентов вместо двух .
Для визуализации процесса обучения мы создаём второй лист, на каждой итерации которого отображается одна строка:
- текущий номер итерации
- шесть коэффициентов (a0, b0, a1, b1, a2, b2)
- потеря
- градиенты
Вторая строка соответствует нулевой итерации с начальными коэффициентами.
В строке 3 вычисляются обновленные коэффициенты с использованием градиентов из строки 2.
Протягивая формулы вниз на сотни строк, мы имитируем градиентный спуск на протяжении множества итераций.
Тогда вы сможете ясно увидеть:
- коэффициенты постепенно стабилизируются
- итерация за итерацией приводит к уменьшению потерь
Это делает процесс обучения осязаемым.
Вместо того чтобы представлять себе оптимизатор, вы можете наблюдать за процессом обучения модели .

Логистическая регрессия как частный случай регрессии Softmax
Логистическая регрессия и регрессия Softmax часто представляются как разные модели.
В действительности, это одна и та же идея, но в разных масштабах.
Функция Softmax Regression вычисляет один линейный показатель для каждого класса и преобразует эти показатели в вероятности путем их сравнения.
Когда имеется только два класса, это сравнение зависит только от разницы между двумя показателями .
Эта разница является линейной функцией входных данных, и применение функции Softmax в данном случае приводит к получению в точности логистической (сигмоидной) функции.
Иными словами, логистическая регрессия — это просто регрессия Softmax, примененная к двум классам, с удалением избыточных параметров.
Как только это будет понято, переход от бинарной к многоклассовой классификации станет естественным продолжением, а не концептуальным скачком.

Заключение
Метод Softmax-регрессии не предлагает нового способа мышления.
Это просто показывает, что логистическая регрессия уже содержала все необходимое .
Дублируя линейную оценку один раз для каждого класса и нормализуя их с помощью Softmax, мы переходим от бинарных решений к многоклассовым вероятностям, не меняя при этом базовую логику.
Суть проигрыша та же.
Градиенты имеют одинаковую структуру.
Оптимизация осуществляется с помощью того же градиентного спуска, который нам уже известен.
Меняется только количество параллельных оценок .
Ещё один способ обработки многоклассовой классификации?
Функция Softmax — не единственный способ решения задач многоклассовой классификации в моделях, основанных на весах.
Существует и другой подход, менее изящный с концептуальной точки зрения, но очень распространенный на практике:
Классификация «один против всех» или «один против одного» .
Вместо создания единой многоклассовой модели мы обучаем несколько бинарных моделей и объединяем их результаты.
Эта стратегия широко используется в методе опорных векторов (SVM) .
Завтра мы рассмотрим метод опорных векторов (SVM).
И вы увидите, что это можно объяснить довольно необычным способом… и, как обычно, прямо в Excel.
Источник: towardsdatascience.com