Почему регуляризация — это не изменение модели, а выбор более подходящих коэффициентов?
Делиться

Однажды специалист по анализу данных сказал, что гребневая регрессия — сложная модель. Потому что он увидел, что формула обучения в ней очень сложная.
Именно в этом и заключается цель моего «Рождественского календаря» по машинному обучению — прояснить этот сложный вопрос.
Итак, в сегодняшней статье мы поговорим о версиях линейной регрессии с регуляризацией.
- Сначала мы рассмотрим, почему необходима регуляризация или штрафование, и посмотрим, как модифицируется модель.
- Затем мы рассмотрим различные типы регуляризации и их влияние.
- Мы также обучим модель с использованием регуляризации и протестируем различные гиперпараметры.
- Мы также зададим ещё один вопрос о том, как взвешивать веса в штрафном члене. (Запутались? Вы сейчас всё поймёте.)
Линейная регрессия и её «условия»
Когда мы говорим о линейной регрессии, часто упоминают, что должны быть соблюдены определенные условия.
Возможно, вы слышали подобные высказывания:
- Остатки должны иметь гауссово распределение (иногда это путают с гауссовым распределением целевой функции, что неверно).
- Объясняющие переменные не должны быть коллинеарными.
В классической статистике эти условия необходимы для вывода заключений. В машинном обучении основное внимание уделяется прогнозированию, поэтому эти предположения менее важны, но основные проблемы всё ещё существуют.
Здесь мы рассмотрим пример коллинеарности двух признаков, и давайте сделаем их полностью равными.
И мы получаем соотношение: y = x1 + x2, и x1 = x2
Я знаю, что если они совершенно равны, мы можем просто сделать: y = 2 * x1. Но идея в том, чтобы сказать, что они могут быть очень похожи, и мы всегда можем построить модель, используя их, верно?
В чём же проблема?
Когда признаки идеально коллинеарны, решение не является единственным. Вот пример на скриншоте ниже.
y = 10000*x1 – 9998*x2

И мы можем заметить, что норма коэффициентов огромна.
Таким образом, идея заключается в ограничении нормы коэффициентов.
И после применения регуляризации концептуальная модель остаётся той же!
Верно. Параметры линейной регрессии изменены. Но модель осталась той же.
Различные варианты регуляризации
Таким образом, идея заключается в объединении среднеквадратичной ошибки (MSE) и нормы коэффициентов.
Вместо того чтобы просто минимизировать среднеквадратичную ошибку, мы пытаемся минимизировать сумму двух слагаемых.
Какую норму выбрать? Мы можем использовать норму L1, L2 или даже объединить их.
Существует три классических способа сделать это, а также соответствующие названия моделей.
Гребневая регрессия (штраф L2)
Гребневая регрессия добавляет штраф к квадратам значений коэффициентов.
Интуитивно понятно:
- Большие коэффициенты сильно наказываются (из-за квадрата).
- Коэффициенты стремятся к нулю
- но они никогда не достигают нуля
Эффект:
- Все характеристики сохранены в модели.
- Коэффициенты более плавные и стабильные.
- очень эффективен против коллинеарности
Гребень сужается , но не выбирает объект.

Регрессия Lasso (штраф L1)
В методе Lasso используется другой штрафной коэффициент: абсолютное значение коэффициентов.
Это небольшое изменение имеет большие последствия.
С помощью лассо:
- некоторые коэффициенты могут стать равными нулю.
- модель автоматически игнорирует некоторые характеристики
Именно поэтому LASSO так и называется, поскольку это аббревиатура от Least Absolute Shrinkage and Selection Operator (оператор наименьшего абсолютного сжатия и отбора) .
- Оператор : это оператор регуляризации, добавляемый к функции потерь.
- Метод наименьших квадратов: он выводится на основе метода наименьших квадратов.
- Абсолютный : используется абсолютное значение коэффициентов (норма L1).
- Сжатие : оно уменьшает коэффициенты, стремясь к нулю.
- Выборка : она может установить некоторые коэффициенты точно равными нулю, выполняя выборку признаков.
Важный нюанс:
- Можно сказать, что модель по-прежнему имеет то же количество коэффициентов.
- но некоторые из них принудительно обнуляются во время тренировки.
Форма модели остается неизменной, но функция Lasso эффективно удаляет элементы, обнуляя коэффициенты.

3. Эластичная сетка (L1 + L2)
Elastic Net — это комбинация Ridge и Lasso.
В нём используется:
- Штраф L1 (как в случае с «Лассо»)
- и штраф L2 (как у Риджа)
Зачем их объединять?
Потому что:
- Метод Lasso может быть нестабильным, когда признаки сильно коррелированы.
- Ridge хорошо справляется с коллинеарностью, но не выбирает объекты.
Elastic Net обеспечивает баланс между:
- стабильность
- усадка
- разреженность
В реальных наборах данных это зачастую наиболее практичный выбор.
Что действительно меняется: модель, обучение, настройка.
Рассмотрим это с точки зрения машинного обучения.
Модель, по сути, не меняется.
Для данной модели , для всех регуляризованных версий, мы по-прежнему пишем:
y = ax + b.
- Одинаковое количество коэффициентов
- Та же формула прогнозирования
- Но коэффициенты будут другими.
С определённой точки зрения, Ridge, Lasso и Elastic Net — это не разные модели .
Принцип тренировки также тот же.
Мы по-прежнему:
- определить функцию потерь
- минимизировать его
- вычислить градиенты
- обновить коэффициенты
Единственное отличие заключается в следующем:
- Функция потерь теперь включает штрафной член.
Вот и всё.
Гиперпараметры добавляются (в этом и заключается основное различие).
В случае линейной регрессии мы не можем контролировать «сложность» модели.
- Стандартная линейная регрессия: без гиперпараметров
- Гребень: один гиперпараметр (лямбда)
- Lasso: один гиперпараметр (лямбда)
- Эластичная сеть: два гиперпараметра
- один для общей силы регуляризации
- один для баланса L1 против L2
Так:
- Стандартная линейная регрессия не требует настройки.
- регрессии с штрафными санкциями
Именно поэтому стандартная линейная регрессия часто воспринимается как «не совсем машинное обучение», в то время как регуляризованные версии явно таковыми являются.
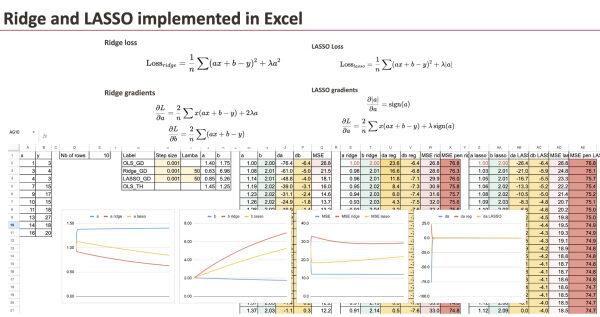
Реализация регуляризованных градиентов
В качестве эталона мы используем градиентный спуск регрессии методом наименьших квадратов, а для гребневой регрессии нам нужно лишь добавить член регуляризации для коэффициента.
Мы будем использовать простой набор данных, который я сгенерировал (тот же самый, который мы уже использовали для линейной регрессии).
Мы видим, что три «модели» различаются по коэффициентам. Цель этой главы — построить градиент для всех моделей и сравнить их.

Гребень с штрафным уклоном
Во-первых, мы можем сделать это для хребта, и нам нужно будет только изменить градиент a.
Однако это не означает, что значение b не изменяется, поскольку градиент b на каждом шаге также зависит от a.

LASSO с регуляризованным градиентом
Тогда мы сможем сделать то же самое для LASSO.
Единственное различие заключается также в градиенте a.
Для каждой модели мы также можем рассчитать среднеквадратичную ошибку (MSE) и регуляризованную среднеквадратичную ошибку (MSE). Довольно приятно видеть, как они уменьшаются с каждой итерацией.

Сравнение коэффициентов
Теперь мы можем визуализировать коэффициент a для всех трех моделей. Чтобы увидеть различия, мы вводим очень большие значения лямбда.

Влияние лямбда
При больших значениях лямбда мы увидим, что коэффициент а становится малым.
А если значение лямбда LASSO станет чрезвычайно большим, то теоретически мы получим значение 0 для параметра a. В численном плане нам необходимо улучшить градиентный спуск.

Регуляризованная логистическая регрессия?
Вчера мы рассматривали логистическую регрессию, и один из вопросов, который мы можем задать, — можно ли её также регуляризовать. Если да, то как это называется?
Ответ, безусловно, да, логистическую регрессию можно регуляризовать.
Здесь действует тот же принцип.
Логистическая регрессия также может быть:
- L1 штраф
- L2 штраф
- Elastic Net наложил штраф
В обиходе нет специальных названий , таких как «гребенчатая логистическая регрессия».
Почему?
Потому что эта концепция уже не нова.
На практике такие библиотеки, как scikit-learn, позволяют просто указать:
- функция потерь
- тип штрафа
- сила регуляризации
Название имело значение, когда идея была новой.
Теперь легализация — это просто стандартный вариант.
Другие вопросы, которые мы можем задать:
- Всегда ли регуляризация полезна?
- Как масштабирование признаков влияет на эффективность регуляризованной линейной регрессии?
Заключение
Методы Ridge и Lasso не изменяют саму линейную модель, они меняют способ обучения коэффициентов. Добавляя штраф, регуляризация способствует получению стабильных и осмысленных решений, особенно когда признаки коррелированы. Пошаговое наблюдение за этим процессом в Excel ясно показывает, что эти методы не сложнее, а просто более контролируемы.
Источник: towardsdatascience.com