Повысьте эффективность своих скриптов для обработки данных, рассматривая структуры данных как шаблоны, а не просто словари.
Делиться

Введение
Если вы работаете в области анализа данных, инженерии данных или являетесь фронтенд/бэкенд-разработчиком, вы имеете дело с JSON. Для профессионалов это, по сути, только смерть, налоги и парсинг JSON, которые неизбежны. Проблема в том, что парсинг JSON часто представляет собой серьезную головную боль.
Независимо от того, получаете ли вы данные из REST API, анализируете логи или читаете конфигурационные файлы, в конечном итоге вы получаете вложенный словарь, который необходимо расшифровать. И давайте будем честны: код, который мы пишем для обработки этих словарей, зачастую… мягко говоря, некрасивый.
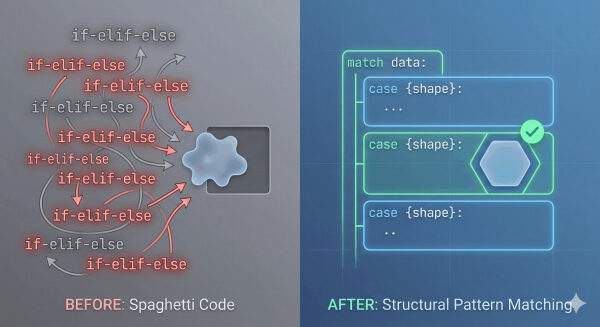
Все мы писали «спагетти-парсер». Вы знаете, о каком я говорю. Он начинается с простого оператора if, но затем нужно проверить, существует ли ключ. Затем нужно проверить, пуст ли список внутри этого ключа. И, наконец, нужно обработать ошибку.
Не успеешь оглянуться, как перед тобой вырастет 40-строчная башня из операторов if-elif-else, которую трудно читать и ещё труднее поддерживать. Конвейеры обработки данных в итоге сломаются из-за каких-нибудь непредвиденных обстоятельств. В общем, плохие предчувствия!
В Python 3.10, вышедшем несколько лет назад, была представлена функция, которую многие специалисты по анализу данных до сих пор не освоили: сопоставление структурных шаблонов с помощью операторов match и case. Её часто ошибочно принимают за простой оператор switch (как в C или Java), но она гораздо мощнее. Она позволяет проверять форму и структуру данных, а не только их значение.
В этой статье мы рассмотрим, как заменить ненадежные проверки словаря элегантными и читаемыми шаблонами, используя операторы match и case. Я сосредоточусь на конкретном примере использования, знакомом многим из нас, вместо того, чтобы пытаться дать исчерпывающий обзор того, как можно работать с match и case.
Источник: towardsdatascience.com