
Команда AI for Devs подготовила перевод статьи о том, в каком формате лучше всего передавать таблицы LLM. Исследование охватило 11 популярных форматов — от CSV и JSON до YAML и Markdown. Результаты неожиданны: разница в точности достигает 16 процентных пунктов, а выбор формата напрямую влияет на стоимость инференса и стабильность RAG-пайплайнов.
Когда речь заходит о надежности систем на базе ИИ, один простой момент часто остается без должного внимания: в каком формате лучше всего передавать таблицы с данными в LLM? Стоит ли использовать таблицы в Markdown или CSV? JSON или YAML? Или какой-то другой формат работает лучше всех?
Почему этот вопрос важен?
RAG-пайплайны: многие RAG-пайплайны включают загрузку документов с таблицами и передачу этой табличной информации в LLM.
Точность системы: если вы оформляете табличные данные неудобным для LLM образом, то вполне возможно, что вы зря снижаете точность всей системы.
Затраты на токены: одни форматы могут расходовать в разы больше токенов, чем другие, для представления одних и тех же данных. Если вы платите за количество обрабатываемых токенов, выбор формата напрямую влияет на стоимость инференса LLM.
Наша методология
Мы спроектировали контролируемый эксперимент, чтобы проверить, как форматирование набора данных влияет на то, насколько точно LLM может отвечать на вопросы по этим данным.
В наших тестах мы передавали модели 1 000 записей и просили ответить на вопрос на основе этих данных. Затем оценивали, дала ли она правильный ответ в каждом случае.
Мы повторили этот процесс для 1 000 вопросов, используя каждый из 11 разных форматов представления данных.
Dataset: 1 000 синтетических записей о сотрудниках по 8 атрибутов каждая (ID, имя, возраст, город, отдел, зарплата, стаж, число проектов)
Questions: 1 000 рандомизированных запросов о конкретных данных
Model: GPT-4.1-nano
Formats Tested: 11 разных форматов представления данных
Примеры пар вопрос–ответ
Q. «How many years of experience does Grace X413 have? (Return just the number, e.g. ’12’.)» A. «15»Q. «What is Alice W204’s salary? (Return just the number, e.g. ‘85200’.)» A. «131370»
Заметки по методологии
Мы решили передавать в LLM сравнительно большой объем записей, чтобы проверить ее пределы. На практике с крупными структурированными данными вы часто захотите бить их на чанки и/или выполнять запросы, чтобы извлечь только наиболее релевантные записи/сведения и передать модели уменьшенный контекст.
При использовании форматов вроде CSV, HTML-таблиц и таблиц в Markdown, где есть заголовки, имеет смысл периодически повторять эти заголовки (например, каждые 100 записей) для лучшего понимания. Для простоты мы этого здесь не делали.
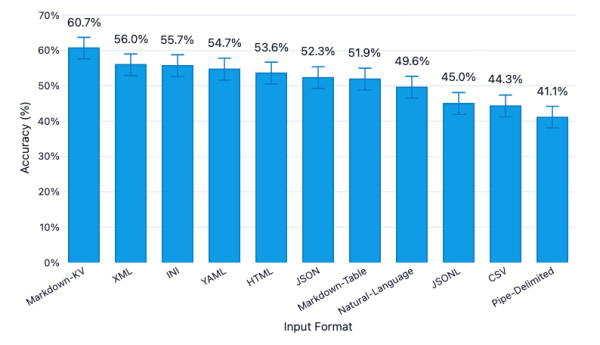
Насколько хорошо LLM поняла каждый формат?
 1")
Формат | Точность | Доверительный интервал 95% | Токены |
|---|---|---|---|
Markdown-KV | 60.7% | 57.6% – 63.7% | 52,104 |
XML | 56.0% | 52.9% – 59.0% | 76,114 |
INI | 55.7% | 52.6% – 58.8% | 48,100 |
YAML | 54.7% | 51.6% – 57.8% | 55,395 |
HTML | 53.6% | 50.5% – 56.7% | 75,204 |
JSON | 52.3% | 49.2% – 55.4% | 66,396 |
Markdown-Table | 51.9% | 48.8% – 55.0% | 25,140 |
Natural-Language | 49.6% | 46.5% – 52.7% | 43,411 |
JSONL | 45.0% | 41.9% – 48.1% | 54,407 |
CSV | 44.3% | 41.2% – 47.4% | 19,524 |
Pipe-Delimited | 41.1% | 38.1% – 44.2% | 43,098 |
Основные выводы
Формат важен: мы увидели заметные различия в понимании между разными форматами.
CSV и JSONL показали слабые результаты: если вы по умолчанию используете один из них, возможны быстрые улучшения.
Markdown-KV оказался лучшим с точностью 60.7% — примерно на 16 пунктов выше, чем у CSV. (Markdown-KV — наш термин для нестандартизованного формата с парами «key: value» в Markdown.)
Точность стоит токенов: лидирующий Markdown-KV израсходовал в 2.7 раза больше токенов, чем самый экономный по токенам формат — CSV.
Компромисс между точностью и стоимостью по токенам
Диаграмма ниже визуализирует связь между точностью и числом токенов (в логарифмическом масштабе). Это помогает показать компромиссы между двумя важными метриками:
 2")
Как видно, в целом большее число токенов коррелирует с большей точностью, но зависимость далека от линейной. Некоторые форматы показывают результат выше ожидаемого для своей «массы» (например, Markdown-KV), тогда как другие неэффективны по обоим параметрам (например, Pipe-Delimited).
Оцененные форматы данных
1. JSON
[ { «id»: 1, «name»: «Diana A0», «age»: 46, «city»: «London», «department»: «Engineering», «salary»: 141015, «years_experience»: 7, «project_count»: 17 }, { «id»: 2, «name»: «Grace B1», «age»: 59, «city»: «Berlin», «department»: «Engineering», «salary»: 100066, «years_experience»: 11, «project_count»: 32 }, { «id»: 3, «name»: «Grace C2», «age»: 64, «city»: «Dubai», «department»: «Engineering», «salary»: 91727, «years_experience»: 9, «project_count»: 49 } ]
2. CSV
id,name,age,city,department,salary,years_experience,project_count 1,Diana A0,46,London,Engineering,141015,7,17 2,Grace B1,59,Berlin,Engineering,100066,11,32 3,Grace C2,64,Dubai,Engineering,91727,9,49
3. XML
<?xml version=»1.0″ ?> <employees> <employee id=»1″> <name>Diana A0</name> <age>46</age> <city>London</city> <department>Engineering</department> <salary>141015</salary> <years_experience>7</years_experience> <project_count>17</project_count> </employee> <employee id=»2″> <name>Grace B1</name> <age>59</age> <city>Berlin</city> <department>Engineering</department> <salary>100066</salary> <years_experience>11</years_experience> <project_count>32</project_count> </employee> <employee id=»3″> <name>Grace C2</name> <age>64</age> <city>Dubai</city> <department>Engineering</department> <salary>91727</salary> <years_experience>9</years_experience> <project_count>49</project_count> </employee> </employees>
4. YAML
records: — id: 1 name: «Diana A0» age: 46 city: «London» department: «Engineering» salary: 141015 years_experience: 7 project_count: 17 — id: 2 name: «Grace B1» age: 59 city: «Berlin» department: «Engineering» salary: 100066 years_experience: 11 project_count: 32 — id: 3 name: «Grace C2» age: 64 city: «Dubai» department: «Engineering» salary: 91727 years_experience: 9 project_count: 49
5. HTML
<h1>Employee Records</h1> <table> <thead> <tr> <th>id</th> <th>name</th> <th>age</th> <th>city</th> <th>department</th> <th>salary</th> <th>years_experience</th> <th>project_count</th> </tr> </thead> <tbody> <tr> <td>1</td> <td>Diana A0</td> <td>46</td> <td>London</td> <td>Engineering</td> <td>141015</td> <td>7</td> <td>17</td> </tr> <tr> <td>2</td> <td>Grace B1</td> <td>59</td> <td>Berlin</td> <td>Engineering</td> <td>100066</td> <td>11</td> <td>32</td> </tr> <tr> <td>3</td> <td>Grace C2</td> <td>64</td> <td>Dubai</td> <td>Engineering</td> <td>91727</td> <td>9</td> <td>49</td> </tr> </tbody> </table>
6. Markdown Table
| id | name | age | city | department | salary | years_experience | project_count | | — | — | — | — | — | — | — | — | | 1 | Diana A0 | 46 | London | Engineering | 141015 | 7 | 17 | | 2 | Grace B1 | 59 | Berlin | Engineering | 100066 | 11 | 32 | | 3 | Grace C2 | 64 | Dubai | Engineering | 91727 | 9 | 49 |
7. Markdown KV
# Employee Database ## Record 1 «` id: 1 name: Charlie A0 age: 56 city: New York department: Operations salary: 67896 years_experience: 7 project_count: 1 «` ## Record 2 «` id: 2 name: Grace B1 age: 59 city: Mumbai department: Marketing salary: 47248 years_experience: 0 project_count: 43 «` ## Record 3 «` id: 3 name: Eve C2 age: 50 city: Singapore department: Sales salary: 102915 years_experience: 14 project_count: 11 «`
8. INI
[employee_1] id = 1 name = Diana A0 age = 46 city = London department = Engineering salary = 141015 years_experience = 7 project_count = 17 [employee_2] id = 2 name = Grace B1 age = 59 city = Berlin department = Engineering salary = 100066 years_experience = 11 project_count = 32 [employee_3] id = 3 name = Grace C2 age = 64 city = Dubai department = Engineering salary = 91727 years_experience = 9 project_count = 49
9. Pipe-Delimited
id: 1 | name: Diana A0 | age: 46 | city: London | department: Engineering | salary: 141015 | years_experience: 7 | project_count: 17 id: 2 | name: Grace B1 | age: 59 | city: Berlin | department: Engineering | salary: 100066 | years_experience: 11 | project_count: 32 id: 3 | name: Grace C2 | age: 64 | city: Dubai | department: Engineering | salary: 91727 | years_experience: 9 | project_count: 49
10. JSONL
{«id»: 1, «name»: «Diana A0», «age»: 46, «city»: «London», «department»: «Engineering», «salary»: 141015, «years_experience»: 7, «project_count»: 17} {«id»: 2, «name»: «Grace B1», «age»: 59, «city»: «Berlin», «department»: «Engineering», «salary»: 100066, «years_experience»: 11, «project_count»: 32} {«id»: 3, «name»: «Grace C2», «age»: 64, «city»: «Dubai», «department»: «Engineering», «salary»: 91727, «years_experience»: 9, «project_count»: 49}
11. Natural Language
Employee Records Summary: Diana A0 (ID: 1) is a 46-year-old employee working in the Engineering department in London. They earn $141,015 with 7 years of experience and have completed 17 projects. Grace B1 (ID: 2) is a 59-year-old employee working in the Engineering department in Berlin. They earn $100,066 with 11 years of experience and have completed 32 projects. Grace C2 (ID: 3) is a 64-year-old employee working in the Engineering department in Dubai. They earn $91,727 with 9 years of experience and have completed 49 projects.
Практические рекомендации
На основе результатов нашего эксперимента:
Если вы активно работаете с табличными данными, проверьте, даст ли преобразование этих данных в другой формат прирост точности.
Markdown-KV выглядит хорошим вариантом по умолчанию в ситуациях, где на первом месте точность.
Рассматривайте таблицы в Markdown, когда нужен баланс между читаемостью и стоимостью по токенам.
Осторожнее с CSV и JSONL по умолчанию — эти распространенные форматы могут снижать точность системы.
Ограничения и направления для дальнейшего изучения
Модели и провайдеры: мы тестировали только GPT-4.1 nano от OpenAI. Другие модели, особенно от других провайдеров, могут лучше работать с иными форматами данных (например, с тем, который чаще всего использовался при обучении этой модели).
Содержимое данных: мы проверяли только один тип набора данных. Результаты могут отличаться на других типах данных.
Структура данных: мы тестировали только простые табличные данные. Было бы интересно проверить вложенные данные, например JSON-конфигурации, а также таблицы со склеенными ячейками.
Размер таблиц и повтор заголовков: чтобы нагрузить модель, мы использовали сравнительно большую таблицу и не повторяли заголовки. Ожидаем, что меньшие таблицы и/или повтор заголовков дадут более высокую точность, особенно для CSV, HTML и таблиц в Markdown (форматов, где есть строки заголовков).
Тип вопросов: в наших тестах каждый вопрос сводился к извлечению значения поля конкретной записи. Было бы интересно проверить и другие типы вопросов.
Русскоязычное сообщество про AI в разработке
 3")
Друзья! Эту новость подготовила команда ТГК «AI for Devs» — канала, где мы рассказываем про AI-ассистентов, плагины для IDE, делимся практическими кейсами и свежими новостями из мира ИИ. Подписывайтесь, чтобы быть в курсе и ничего не упустить!
Заключительные мысли
Нас удивило, насколько сильно формат входных данных влияет на результат. Наши наблюдения показывают, что простые преобразования данных в некоторых случаях могут заметно повысить точность систем на базе LLM. Мы планируем продолжить изучение этой темы.
Источник: habr.com



















