Руководство по пониманию дисперсии выборки и генеральной совокупности в Python и R.
Делиться

Представьте, что вы анализируете небольшой набор данных:
[X = [15, 8, 13, 7, 7, 12, 15, 6, 8, 9]]
Вам нужно вычислить некоторые сводные статистические показатели, чтобы получить представление о распределении этих данных, поэтому вы используете numpy для вычисления среднего значения и дисперсии.
import numpy as np X = [15, 8, 13, 7, 7, 12, 15, 6, 8, 9] mean = np.mean(X) var = np.var(X) print(f"Mean={mean:.2f}, Variance={var:.2f}")Результат выглядит следующим образом:
Mean=10.00, Variance=10.60Отлично! Теперь у вас есть представление о распределении ваших данных. Однако ваш коллега сообщает, что он также рассчитал некоторые сводные статистические данные по этому же набору данных, используя следующий код:
import pandas as pd X = pd.Series([15, 8, 13, 7, 7, 12, 15, 6, 8, 9]) mean = X.mean() var = X.var() print(f"Mean={mean:.2f}, Variance={var:.2f}")Результат их работы выглядит следующим образом:
Mean=10.00, Variance=11.78Средние значения одинаковы, но дисперсии разные! В чём причина?
Это расхождение возникает из-за того, что библиотеки numpy и pandas используют разные формулы по умолчанию для вычисления дисперсии массива. В этой статье будет дано математическое определение двух дисперсий, объяснено, почему они различаются, и показано, как использовать любую из этих формул в различных численных библиотеках.
Два определения
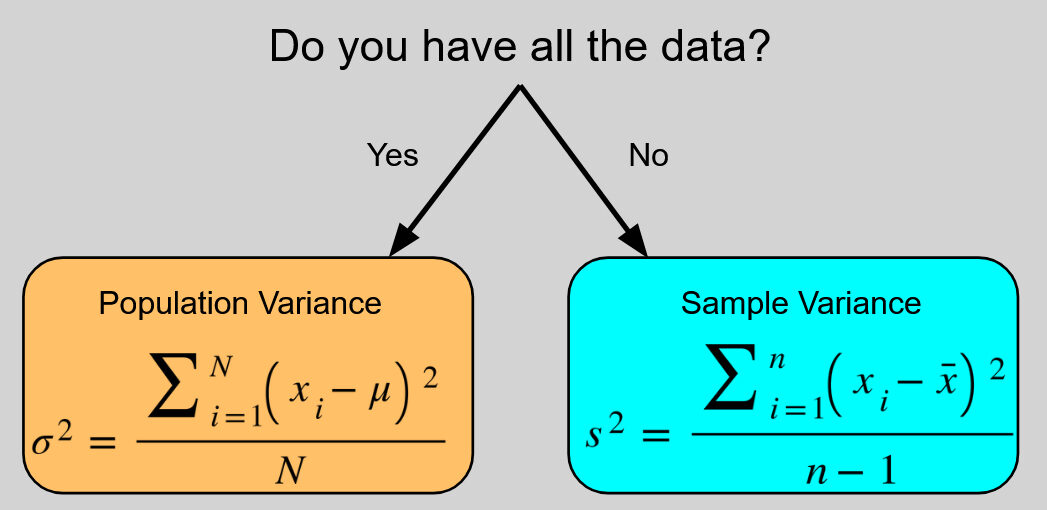
Существует два стандартных способа вычисления дисперсии, каждый из которых предназначен для разных целей. Суть в том, вычисляете ли вы дисперсию всей популяции (всей изучаемой группы) или только выборки (меньшего подмножества этой популяции, для которого у вас есть данные).
Дисперсия генеральной совокупности σ²σ² определяется следующим образом:
[sigma^2 = frac{sum_{i=1}^N(x_i-mu)^2}{N}]
При этом выборочная дисперсия s2s^2 определяется следующим образом:
[s^2 = frac{sum_{i=1}^n(x_i-bar x)^2}{n-1}]
(Примечание: xix_i представляет собой каждую отдельную точку данных в вашем наборе данных. NN представляет общее количество точек данных в популяции, nn представляет общее количество точек данных в выборке, а x‾bar x — выборочное среднее).
Обратите внимание на два ключевых различия между этими уравнениями:
- В сумме числителей σ²σ² вычисляется с использованием среднего значения генеральной совокупности μμ, а s²s² вычисляется с использованием среднего значения выборки x‾∘x.
- В знаменателе σ²σ² делится на общий размер популяции NN, а s²s² делится на размер выборки минус один, n−1n-1.
Следует отметить, что различие между этими двумя определениями наиболее важно для небольших размеров выборки. По мере роста nn различие между nn и n−1n-1 становится все менее и менее значимым.
Почему они разные?
При вычислении дисперсии генеральной совокупности предполагается, что у вас есть все данные. Вам известен точный центр (среднее значение генеральной совокупности μmu) и точное расстояние каждой точки от этого центра. Деление на общее количество точек данных NN дает истинное, точное среднее значение этих квадратов разностей.
Однако при вычислении выборочной дисперсии не предполагается наличие всех данных, поэтому истинное среднее значение генеральной совокупности μmu отсутствует. Вместо этого имеется лишь оценка μmu, которая представляет собой выборочное среднее x‾bar x. Тем не менее, оказывается, что использование выборочного среднего вместо истинного среднего значения генеральной совокупности в среднем приводит к недооценке истинной дисперсии генеральной совокупности.
Это происходит потому, что выборочное среднее вычисляется непосредственно из выборочных данных, то есть оно находится точно в математическом центре конкретной выборки. В результате точки данных в вашей выборке всегда будут ближе к своему собственному выборочному среднему, чем к истинному среднему значению генеральной совокупности, что приводит к искусственно заниженной сумме квадратов разностей.
Для исправления этой недооценки мы применяем так называемую поправку Бесселя (названную в честь немецкого математика Фридриха Вильгельма Бесселя), при которой мы делим не на nn, а на немного меньшее n−1n-1, чтобы скорректировать это смещение, поскольку деление на меньшее число немного увеличивает итоговую дисперсию.
Степени свободы
Так почему же деление происходит на n−1n-1, а не на n−2n-2, n−3n-3 или любую другую поправку, которая также увеличивает конечную дисперсию? Это сводится к концепции, называемой степенями свободы .
Степени свободы — это количество независимых значений в вычислении, которые могут свободно изменяться. Например, представьте, что у вас есть набор из 3 чисел (x1, x2, x3)(x1, x2, x3). Вы не знаете их значений, но знаете, что их выборочное среднее x‾=10bar x = 10.
- Первое число x1x_1 может быть любым (например, 8).
- Второе число x2x_2 также может быть любым (например, 15).
- Поскольку среднее арифметическое должно быть равно 10, x3x_3 не может свободно изменяться и должно быть единственным числом таким, что x‾=10bar x = 10, что в данном случае равно 7.
В этом примере, несмотря на наличие трех чисел, существует только две степени свободы, поскольку установление выборочного среднего исключает возможность свободного изменения одного из них.
В контексте дисперсии, прежде чем приступать к вычислениям, мы начинаем с nn степеней свободы (соответствующих нашим nn точкам данных). Вычисление выборочного среднего x‾bar x по сути использует одну степень свободы, поэтому к моменту вычисления выборочной дисперсии остается n−1n-1 степеней свободы, с которыми можно работать, именно поэтому в знаменателе появляется n−1n-1.
Настройки библиотеки по умолчанию и способы их выравнивания
Теперь, когда мы разобрались с математикой, мы наконец-то можем разгадать загадку из начала статьи! numpy и pandas дали разные результаты, потому что по умолчанию используют разные формулы дисперсии.
Во многих численных библиотеках это контролируется с помощью параметра ddof , что означает «дельта-степени свободы» . Он представляет собой значение, вычитаемое из общего числа наблюдений в знаменателе.
- Установка
ddof=0делит уравнение на nn, вычисляя дисперсию генеральной совокупности . - Установка
ddof=1делит уравнение на n−1n-1, вычисляя выборочную дисперсию .
Эти методы также можно применять при вычислении стандартного отклонения, которое представляет собой квадратный корень из дисперсии.
Ниже приведено описание того, как различные популярные библиотеки обрабатывают эти значения по умолчанию и как вы можете их переопределить:
numpy
По умолчанию numpy предполагает, что вы вычисляете дисперсию генеральной совокупности ( ddof=0 ). Если вы работаете с выборкой и вам необходимо применить поправку Бесселя, вы должны явно передать ddof=1 .
import numpy as np X = [15, 8, 13, 7, 7, 12, 15, 6, 8, 9] # Sample variance and standard deviation np.var(X, ddof=1) np.std(X, ddof=1) # Population variance and standard deviation (Default) np.var(X) np.std(X)панды
По умолчанию pandas использует противоположный подход. Он предполагает, что ваши данные являются выборкой, и вычисляет выборочную дисперсию ( ddof=1 ). Чтобы вычислить дисперсию генеральной совокупности, необходимо передать ddof=0 .
import pandas as pd X = pd.Series([15, 8, 13, 7, 7, 12, 15, 6, 8, 9]) # Sample variance and standard deviation (Default) X.var() X.std() # Population variance and standard deviation X.var(ddof=0) X.std(ddof=0) Встроенный модуль statistics Python
Стандартная библиотека Python не использует параметр ddof . Вместо этого она предоставляет функции с явно указанными именами, чтобы не возникало двусмысленности относительно того, какая формула используется.
import statistics X = [15, 8, 13, 7, 7, 12, 15, 6, 8, 9] # Sample variance and standard deviation statistics.variance(X) statistics.stdev(X) # Population variance and standard deviation statistics.pvariance(X) statistics.pstdev(X)Р
В R стандартные функции var() и sd() по умолчанию вычисляют выборочную дисперсию и выборочное стандартное отклонение. В отличие от библиотек Python, в R нет встроенного аргумента для удобного переключения на формулу генеральной совокупности. Для вычисления дисперсии генеральной совокупности необходимо вручную умножить выборочную дисперсию на n−1nfrac{n-1}{n}.
X <- c(15, 8, 13, 7, 7, 12, 15, 6, 8, 9) n <- length(X) # Sample variance and standard deviation (Default) var(X) sd(X) # Population variance and standard deviation var(X) * ((n - 1) / n) sd(X) * sqrt((n - 1) / n)Заключение
В этой статье рассматривается досадная, но часто незаметная особенность различных языков и библиотек статистического программирования — они выбирают разные определения дисперсии и стандартного отклонения по умолчанию. Приводится пример, когда для одного и того же входного массива numpy и pandas по умолчанию возвращают разные значения дисперсии.
В итоге всё свелось к различию в способах расчета дисперсии для всей изучаемой статистической совокупности и для выборки из этой совокупности, причём разные библиотеки выбирали разные значения по умолчанию. В конце концов было показано, что, хотя каждая библиотека имеет свои значения по умолчанию, все они могут использоваться для расчета обоих типов дисперсии с помощью аргумента ddof , немного отличающейся функции или простого математического преобразования.
Спасибо за прочтение!
Кеннет Маккарти. Все работы Кеннета Маккарти.
Источник: towardsdatascience.com