

Внезапные наводнения — одни из самых смертоносных погодных явлений в мире, ежегодно уносящие жизни более 5000 человек. Их также сложнее всего предсказать. Но Google считает, что нашел решение этой проблемы неожиданным способом — читая новости.
Хотя человечество собрало много данных о погоде, внезапные наводнения слишком кратковременны и локализованы, чтобы их можно было всесторонне измерить, как, например, температуру или даже уровень воды в реках. Этот пробел в данных означает, что модели глубокого обучения, которые все чаще способны прогнозировать погоду, не могут предсказывать внезапные наводнения.
Для решения этой проблемы исследователи Google использовали Gemini — большую языковую модель Google — для обработки 5 миллионов новостных статей со всего мира, выделив сообщения о 2,6 миллионах различных наводнений и преобразовав эти сообщения в геотегированный временной ряд под названием «Groundsource». По словам Гилы Лойке, менеджера по продуктам Google Research, это первый случай использования компанией языковых моделей для подобной работы. Результаты исследования и набор данных были опубликованы в четверг утром.
Используя Groundsource в качестве реального базового показателя, исследователи обучили модель, построенную на основе нейронной сети с долговременной кратковременной памятью (LSTM), для обработки глобальных прогнозов погоды и генерации вероятности внезапных наводнений в данном районе.
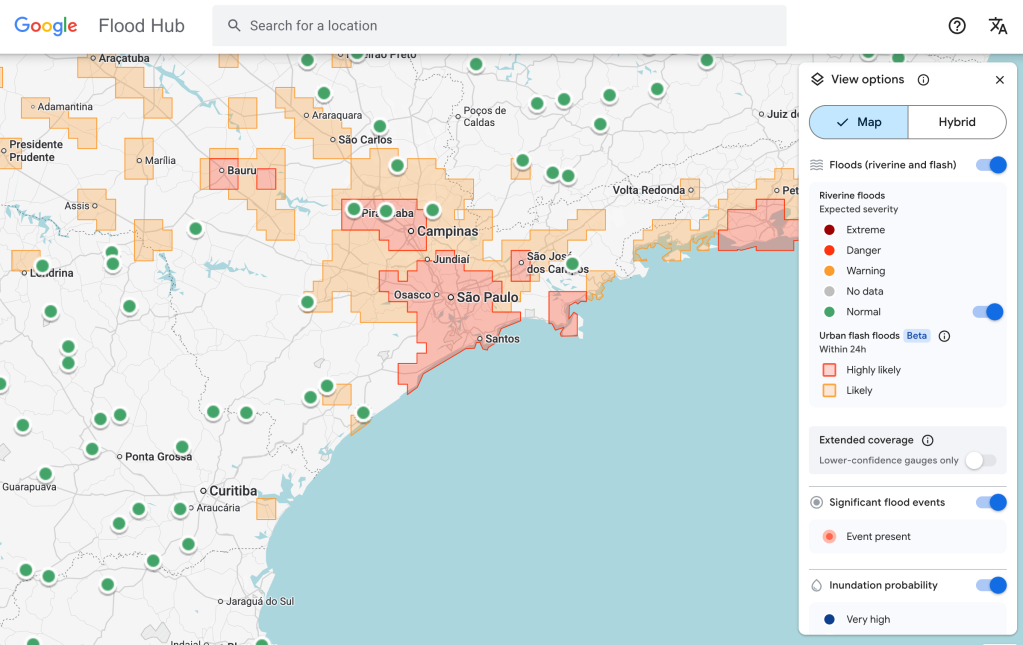
Модель прогнозирования внезапных наводнений от Google теперь выявляет риски для городских районов в 150 странах на платформе Flood Hub компании и делится своими данными с агентствами по реагированию на чрезвычайные ситуации по всему миру. Антонио Хосе Белеза, сотрудник по реагированию на чрезвычайные ситуации в Сообществе развития Южной Африки, который тестировал модель прогнозирования совместно с Google, сказал, что она помогла его организации быстрее реагировать на наводнения.
У этой модели всё ещё есть ограничения. Во-первых, она имеет довольно низкое разрешение, определяя риск на территориях площадью 20 квадратных километров. И она не так точна, как система оповещения о наводнениях Национальной метеорологической службы США, отчасти потому, что модель Google не учитывает данные местных радаров, которые позволяют отслеживать осадки в режиме реального времени.
Однако отчасти дело в том, что проект был разработан для работы в местах, где местные органы власти не могут позволить себе инвестировать в дорогостоящую инфраструктуру для мониторинга погоды или не располагают обширными массивами метеорологических данных.
Мероприятие Techcrunch
Disrupt 2026: Технологическая экосистема в одном месте
Ваш следующий раунд финансирования. Ваш следующий сотрудник. Ваша следующая возможность прорыва. Найдите это на TechCrunch Disrupt 2026, где более 10 000 основателей, инвесторов и лидеров технологической отрасли соберутся на три дня, чтобы принять участие в более чем 250 практических сессиях, установить полезные контакты и познакомиться с инновациями, определяющими рынок. Зарегистрируйтесь сейчас и сэкономьте до 400 долларов.
Сэкономьте до 300 долларов или 30% на посещении TechCrunch Founder Summit.
Более 1000 основателей и инвесторов соберутся на TechCrunch Founder Summit 2026 на целый день, посвященный росту, реализации и масштабированию в реальных условиях. Учитесь у основателей и инвесторов, которые сформировали отрасль. Общайтесь с коллегами, проходящими аналогичные этапы роста. Получите тактические приемы, которые можно применить немедленно.
Предложение действительно до 13 марта.
Сан-Франциско, Калифорния | 13-15 октября 2026 г. ЗАРЕГИСТРИРУЙТЕСЬ СЕЙЧАС
«Поскольку мы объединяем миллионы отчетов, набор данных Groundsource фактически помогает сбалансировать карту», — заявила на этой неделе журналистам Джульет Ротенберг, руководитель программы в команде Google Resilience. «Это позволяет нам экстраполировать данные на другие регионы, где информации не так много».
Ротенберг сказал, что команда надеется, что использование LLM для разработки количественных наборов данных на основе письменных качественных источников может быть применено к усилиям по созданию наборов данных о других мимолетных, но важных для прогнозирования явлениях, таких как волны жары и оползни.
Маршалл Мутенот, генеральный директор Upstream Tech, компании, использующей аналогичные модели глубокого обучения для прогнозирования речных потоков для таких клиентов, как гидроэнергетические компании, заявил, что вклад Google является частью растущих усилий по сбору данных для моделей прогнозирования погоды на основе глубокого обучения. Мутенот является соучредителем dynamical.org, группы, которая собирает коллекцию готовых к использованию в машинном обучении данных о погоде для исследователей и стартапов.
«Дефицит данных — одна из самых сложных проблем в геофизике, — сказал Мутенот. — В то же время, данных о Земле слишком много, а когда нужно провести сравнительную оценку, их недостаточно. Это был действительно креативный подход к получению этих данных».
Источник: techcrunch.com



















