
Мы предлагаем новую модель дифференциальной конфиденциальности, которая учитывает различные предположения о доверии между пользователями, и разрабатываем несколько алгоритмов и нижних границ для этой модели.
Быстрые ссылки
- Бумага
- Делиться
Дифференцированная конфиденциальность (ДП) — это математически строгая и широко изучаемая концепция конфиденциальности, которая гарантирует, что выходные данные рандомизированного алгоритма остаются статистически неразличимыми, даже если данные одного пользователя изменяются. Эта концепция широко изучалась как в теории, так и на практике, и имеет множество применений в аналитике и машинном обучении (например, 1, 2, 3, 4, 5, 6, 7).
Существуют две основные модели дифференциальной приватности (DP): центральная и локальная . В центральной модели доверенный куратор имеет доступ к исходным данным и отвечает за создание выходных данных, обладающих дифференциальной приватностью. Локальная модель требует, чтобы все сообщения, отправляемые с устройства пользователя, сами по себе обладали дифференциальной приватностью, что устраняет необходимость в доверенном кураторе. Хотя локальная модель привлекательна благодаря минимальным требованиям к доверию, она часто приводит к значительно большему снижению полезности по сравнению с центральной моделью.
В реальных сценариях обмена данными пользователи часто проявляют разный уровень доверия к другим, в зависимости от их взаимоотношений. Например, кто-то может чувствовать себя комфортно, делясь данными о своем местоположении с семьей или близкими друзьями, но будет колебаться, прежде чем разрешить незнакомцам доступ к той же информации. Эта асимметрия согласуется с философскими взглядами на конфиденциальность как контроль над личной информацией, где люди указывают, с кем они готовы делиться своими данными. Такие тонкие нюансы в предпочтениях в отношении конфиденциальности подчеркивают необходимость в концепциях, выходящих за рамки бинарных предположений о доверии существующих моделей с дифференциальной конфиденциальностью, и учитывающих более реалистичную динамику доверия в системах, обеспечивающих конфиденциальность.
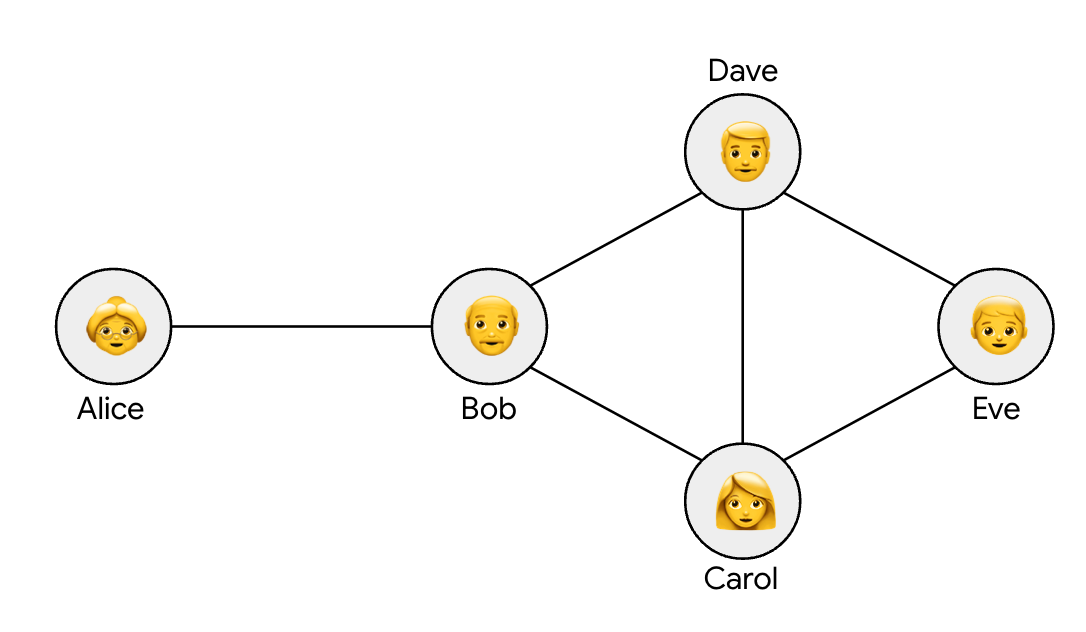
В статье «Дифференциальная конфиденциальность на графах доверия», опубликованной на конференции «Инновации в теоретической информатике» (ITCS 2025) , мы используем граф доверия для моделирования взаимоотношений, где вершины представляют пользователей, а связанные вершины доверяют друг другу (см. ниже). Мы исследуем, как применять дифференциальную конфиденциальность к этим графам доверия, обеспечивая, чтобы гарантия конфиденциальности распространялась на сообщения, которыми обмениваются пользователь (или его доверенные соседи) и все остальные, кому он не доверяет. В частности, распределение сообщений, которыми обменивается каждый пользователь u или один из его соседей с любым другим пользователем, которому u не доверяет, должно быть статистически неразличимым, если входные данные, хранящиеся у u, изменяются, что мы называем дифференциальной конфиденциальностью на графах доверия (TGDP).

Пример графа доверия с обменом данными о местоположении. Алиса делится своим местоположением с Бобом, который делится своим местоположением с Кэрол и Дэйвом. Кэрол и Дэйв делятся своим местоположением с Евой. Согласно введённому нами определению графа доверия DP, требуется, чтобы Кэрол, Дэйв и Ева не могли идентифицировать информацию об Алисе, даже если они объединят все свои данные и любые данные, которыми с ними поделились.
Граф доверия DP
TGDP естественным образом интерполирует между центральной и локальной моделями. Центральная модель эквивалентна TGDP для звездообразного графа, где доверенный центральный куратор данных находится в центре и связан со всеми остальными пользователями (верхний рисунок, ниже). Локальная модель, с другой стороны, эквивалентна TGDP для полностью несвязанного графа, в котором ни один пользователь не доверяет другим пользователям (нижний рисунок, ниже).

Слева : Пример графа доверия в виде «звезды», соответствующего центральной модели DP, в которой все пользователи доверяют центральному куратору. Справа : Пример полностью несвязанного графа доверия, соответствующего локальной модели DP, в которой ни один пользователь не доверяет другим пользователям.
Известно, что алгоритмы, которые должны удовлетворять центральному доверительному соглашению (DP), могут быть точнее , чем алгоритмы, которые должны удовлетворять локальному доверительному соглашению, поскольку при центральном доверительном соглашении обеспечивается большая гибкость в обмене данными. С помощью TGDP мы можем количественно оценить точность алгоритмов в условиях более общих доверительных отношений между ними.
Мы количественно оцениваем точность с помощью простой задачи агрегирования , которая является базовым элементом для более сложных задач машинного обучения. Предположим , что каждый пользователь имеет личное значение данных, xᵢ , которое представляет собой действительное число , ограниченное некоторым диапазоном. Цель задачи агрегирования — разработать алгоритм, который может оценить сумму значений всех пользователей, Σᵢxᵢ , с минимальной погрешностью (измеряемой как среднеквадратичная ошибка).
В следующих разделах мы приводим как верхнюю, так и нижнюю границы погрешности алгоритмов агрегирования, удовлетворяющих условию TGDP. Эти границы количественно определяют пределы возможностей алгоритмов TGDP: один из них может показать результаты как минимум не хуже верхней границы, и ни один алгоритм TGDP не может показать результаты лучше нижней границы.
Алгоритм, основанный на доминирующем множестве
Мы предлагаем алгоритм агрегирования, удовлетворяющий условию TGDP. И алгоритм, и верхняя граница основаны на доминирующем множестве графа доверия.
Доминирующее множество T — это подмножество вершин графа, такое что каждая вершина, не входящая в T , смежна по крайней мере с одной вершиной из T. Например, на рисунке ниже доминирующее множество показано синим цветом.

Иллюстрация доминирующего множества в графе доверия. Алиса и Ева, выделенные синим цветом, являются частью доминирующего множества T.
По определению доминирующего множества, каждый пользователь доверяет как минимум одному пользователю из этого множества. Это позволяет нам построить алгоритм, в котором каждый пользователь отправляет свои необработанные данные своему доверенному соседу в этом множестве, после чего доверенный сосед может агрегировать все полученные данные и добавить соответствующий шум для достижения дифференциальной конфиденциальности. Более конкретно, наш алгоритм доминирующего множества работает следующим образом :
- Найдите доминирующее множество T графа доверия.
- Каждый пользователь отправляет свои данные соседу из доминирующего множества T.
- Каждый пользователь из доминирующего множества T передает сумму всех полученных им чисел плюс шум Лапласа.
- Оценка представляет собой сумму всех шумовых трансляций.
Ошибка этого алгоритма не превышает функцию размера доминирующего множества T. Эта ошибка минимизируется для наименьшего возможного доминирующего множества, или минимального доминирующего множества. Размер минимального доминирующего множества в графе G называется его числом доминирования .
Таким образом, если на шаге 1 выше нам удастся найти минимальное доминирующее множество, то алгоритм определения доминирующего множества может иметь ошибку, не превышающую константу, умноженную на число доминирования.
Естественно возникает вопрос, является ли алгоритм доминирующего множества лучшим алгоритмом. Оказывается, что на самом деле можно добиться лучших результатов, используя линейное программирование, и в статье мы приводим лучший алгоритм и верхнюю границу.
Нижняя граница через число упаковки
В более общем случае нам нужна нижняя граница, чтобы охарактеризовать, какой может быть наилучшая возможная ошибка. Оказывается, существует довольно интуитивно понятная нижняя граница, которая зависит от числа упаковки графа: максимального размера множества вершин, не имеющих общих соседей.
Например, для графа на первом рисунке число упаковки равно 2, поскольку Алиса и Ева не имеют общих соседей. Для звездообразного графа число упаковки равно 1.
В то время как ошибка алгоритма доминирующего множества, описанного в предыдущем разделе, была ограничена сверху числом доминирования, в данной статье мы доказываем, что ни один алгоритм не может иметь ошибку меньше некоторой константы, умноженной на число упаковки.
В общем случае число доминирования всегда больше или равно числу упаковки (см., например, эту статью), но может быть разрыв. Например, ниже приведен граф с числом доминирования 4 и числом упаковки 1.

График с разрывом между числом доминирования (4) и числом упаковки (1).
Разница между числом доминирования и числом упаковки подразумевает наличие разницы между верхней и нижней границами ошибки, которую мы здесь показали (в полной версии статьи мы приводим еще лучшую верхнюю границу, используя алгоритм на основе линейного программирования, но разница все еще существует). Устранение этой разницы между верхней и нижней границами является открытой проблемой в теории алгоритмов TGDP.
Машинное обучение с графом доверия DP
Описанный выше протокол доминирующего множества легко адаптируется для агрегирования векторов вместо действительных чисел. Агрегирование векторов — ключевая задача в федеративной аналитике и федеративном обучении; для приложений машинного обучения агрегирование векторов может использоваться для вычисления агрегированных градиентов на разных устройствах. При выполнении этого шага с дифференциальной конфиденциальностью мы также получаем, что итоговая модель удовлетворяет дифференциальной конфиденциальности. Это была основная парадигма для достижения дифференциальной конфиденциальности в федеративном обучении. Наш подход естественным образом вписывается в эту структуру: используя агрегирование векторов с TGDP, мы сразу получаем, что итоговая модель машинного обучения удовлетворяет TGDP.
Заключение
В данной работе мы представляем модель распределенного динамического программирования на основе графа доверия (TGDP), которая позволяет более точно контролировать предположения о доверии каждого участника. Наша модель TGDP интерполирует между центральным и локальным динамическим программированием, что позволяет нам более общим образом рассуждать о том, как отношения доверия связаны с точностью алгоритмов в динамическом программировании. Мы предложили алгоритм и нижнюю границу для задачи агрегирования. Как упоминалось выше, интересным открытым теоретическим вопросом является устранение разрыва между нашими верхней и нижней границами. Наше определение может представлять практический интерес, поскольку платформы переходят к различным моделям доверия, от инициатив по обмену данными в здравоохранении до индивидуального выбора обмена данными на социальных платформах.
Благодарности
Данная статья основана на совместной работе с Бадихом Гази и Рави Кумаром. Мы также благодарим их за полезные отзывы, предоставленные в процессе подготовки этой статьи.
Источник: research.google