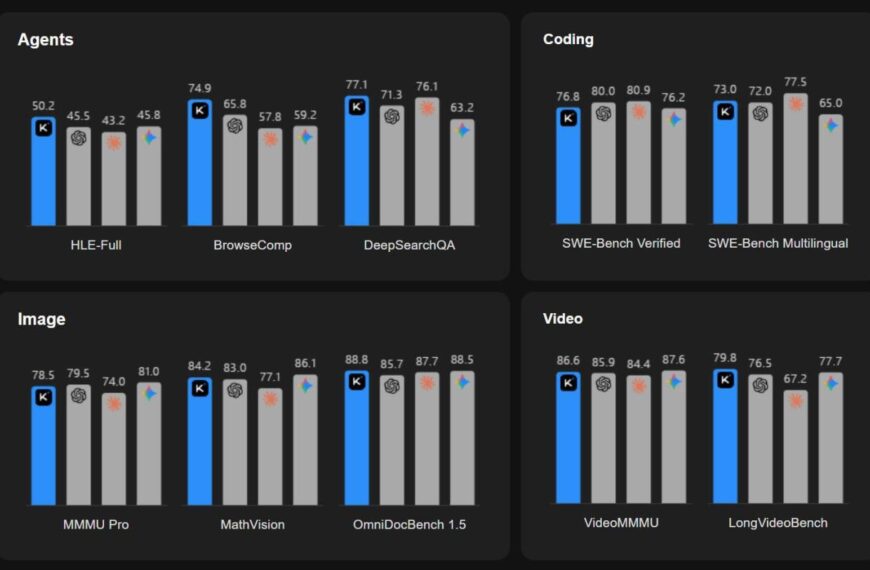
Эксперты добились прогресса в области безопасности LLM. Но некоторые сомневаются в готовности ИИ-помощников к широкому применению.

Работа с ИИ-агентами сопряжена с большими рисками. Даже находясь в окне чата, LLM-ы будут совершать ошибки и вести себя некорректно. Как только у них появятся инструменты для взаимодействия с внешним миром, такие как веб-браузеры и адреса электронной почты, последствия этих ошибок станут гораздо серьезнее.
Возможно, это объясняет, почему первый прорыв в области создания персональных помощников для студентов магистратуры появился не в одной из крупнейших лабораторий искусственного интеллекта, которым приходится беспокоиться о репутации и ответственности, а у независимого инженера-программиста Питера Штайнбергера. В ноябре 2025 года Штайнбергер загрузил свой инструмент, теперь называемый OpenClaw, на GitHub, и в конце января проект стал вирусным.
OpenClaw использует существующие программы магистратуры в области права, позволяя пользователям создавать собственных персонализированных помощников. Для некоторых пользователей это означает передачу огромного количества личных данных, от многолетней переписки по электронной почте до содержимого жесткого диска. Это вызывает серьезную обеспокоенность у экспертов по безопасности. Риски, связанные с OpenClaw, настолько велики, что, вероятно, кому-то потребовалась бы целая неделя, чтобы прочитать все публикации в блогах по безопасности, появившиеся за последние несколько недель. Правительство Китая предприняло шаг, выпустив публичное предупреждение об уязвимостях безопасности OpenClaw.
В ответ на эти опасения Штейнбергер написал на X, что нетехническим людям не следует использовать это программное обеспечение. (Он не ответил на запрос о комментарии для этой статьи.) Но есть явный интерес к тому, что предлагает OpenClaw, и он не ограничивается теми, кто может самостоятельно проводить аудит безопасности программного обеспечения. Любым компаниям, занимающимся искусственным интеллектом и надеющимся выйти на рынок персональных помощников, необходимо будет понять, как создать систему, которая обеспечит безопасность и сохранность данных пользователей. Для этого им потребуется заимствовать подходы из передовых исследований в области безопасности агентов.
Управление рисками
OpenClaw — это, по сути, механический костюм для магистров права. Пользователи могут выбрать любого магистра права в качестве пилота; этот магистр получает доступ к улучшенным возможностям памяти и способности задавать себе задачи, которые он будет повторять с регулярной периодичностью. В отличие от агентских решений крупных компаний, занимающихся ИИ, агенты OpenClaw предназначены для круглосуточной работы, и пользователи могут общаться с ними через WhatsApp или другие мессенджеры. Это означает, что они могут действовать как сверхмощный личный помощник, который каждое утро будит вас персонализированным списком дел, планирует отпуск, пока вы работаете, и запускает новые приложения в свободное время.
Но вся эта власть имеет последствия. Если вы хотите, чтобы ваш персональный ИИ-помощник управлял вашей электронной почтой, вам нужно предоставить ему доступ к вашей почте — и всей содержащейся в ней конфиденциальной информации. Если вы хотите, чтобы он совершал покупки от вашего имени, вам нужно предоставить ему данные вашей кредитной карты. А если вы хотите, чтобы он выполнял задачи на вашем компьютере, например, писал код, ему необходим доступ к вашим локальным файлам.
Связанная статья
Существует несколько способов, которыми это может пойти не так. Во-первых, ИИ-помощник может допустить ошибку, как это произошло, когда, по сообщениям, агент Google Antigravity стер весь жесткий диск пользователя. Во-вторых, кто-то может получить доступ к агенту с помощью обычных хакерских инструментов и использовать его для извлечения конфиденциальных данных или запуска вредоносного кода. За несколько недель с момента появления OpenClaw в сети исследователи безопасности продемонстрировали множество подобных уязвимостей, которые ставят под угрозу безопасность пользователей, не разбирающихся в вопросах безопасности.
Обе эти опасности можно предотвратить: некоторые пользователи предпочитают запускать агенты OpenClaw на отдельных компьютерах или в облаке, что защищает данные на их жестких дисках от удаления, а другие уязвимости можно устранить с помощью проверенных методов обеспечения безопасности.
Однако эксперты, с которыми я беседовал для этой статьи, сосредоточились на гораздо более коварной угрозе безопасности, известной как внедрение вредоносного кода. Внедрение вредоносного кода — это, по сути, захват доступа пользователей с ограниченными правами: просто разместив вредоносный текст или изображения на веб-сайте, который может просматривать пользователь с ограниченными правами, или отправив их в почтовый ящик, который он читает, злоумышленники могут изменить их по своему усмотрению.
И если такая компания, предоставляющая услуги в области права, получит доступ к личной информации своих пользователей, последствия могут быть ужасными. «Использование чего-то вроде OpenClaw — это как отдать свой кошелек незнакомцу на улице», — говорит Николас Паперно, профессор электротехники и вычислительной техники в Университете Торонто. Возможность крупных компаний, занимающихся разработкой ИИ, предлагать услуги персональных помощников может зависеть от качества защиты, которую они смогут обеспечить от подобных атак.
Важно отметить, что внедрение уязвимости с помощью команды prompt пока не привело ни к каким катастрофам, по крайней мере, о них не сообщалось публично. Но теперь, когда в интернете, вероятно, циркулируют сотни тысяч агентов OpenClaw, внедрение уязвимости с помощью команды prompt может начать выглядеть гораздо более привлекательной стратегией для киберпреступников. «Подобные инструменты стимулируют злоумышленников атаковать гораздо более широкую аудиторию», — говорит Папернот.
Строительство ограждений
Термин «внедрение подсказок» был придуман популярным блогером, пишущим о LLM, Саймоном Уиллисоном в 2022 году, за пару месяцев до выхода ChatGPT. Уже тогда можно было предвидеть, что LLM внесут совершенно новый тип уязвимости в систему безопасности, как только получат широкое распространение. LLM не могут отличить инструкции, которые они получают от пользователей, от данных, которые они используют для выполнения этих инструкций, таких как электронные письма и результаты веб-поиска — для LLM это просто текст. Поэтому, если злоумышленник внедрит несколько предложений в электронное письмо, и LLM примет их за инструкцию от пользователя, злоумышленник сможет заставить LLM сделать все, что захочет.
Внедрение вредоносного ПО без предупреждения — сложная проблема, и, похоже, она никуда не денется в ближайшее время. «У нас пока нет универсального решения», — говорит Доун Сонг, профессор компьютерных наук в Калифорнийском университете в Беркли. Но над этой проблемой работает активное академическое сообщество, и они разработали стратегии, которые в конечном итоге могут сделать персональных помощников на основе ИИ безопасными.
С технической точки зрения, сегодня можно использовать OpenClaw, не рискуя внедрением подсказок: просто не подключайте его к интернету. Но ограничение доступа OpenClaw к чтению вашей электронной почты, управлению календарем и онлайн-исследованиям сводит на нет большую часть смысла использования ИИ-помощника. Секрет защиты от внедрения подсказок заключается в том, чтобы предотвратить реакцию LLM на попытки взлома, но при этом оставить ему пространство для выполнения своей работы.
Одна из стратегий заключается в обучении модели LLM игнорировать подсказки. Важная часть процесса разработки LLM, называемая постобучением, включает в себя превращение модели, умеющей создавать реалистичный текст, в полезного помощника путем «вознаграждения» за правильные ответы на вопросы и «наказания» за ошибки. Эти вознаграждения и наказания носят метафорический характер, но LLM учится на них, как животное. Используя этот процесс, можно обучить LLM не реагировать на конкретные примеры подсказок.
Но здесь важен баланс: если обучить LLM слишком решительно отклонять внедренные команды, он может начать отклонять и законные запросы от пользователя. А поскольку в поведении LLM присутствует элемент случайности, даже LLM, эффективно обученный противостоять внедрению команд, все равно будет время от времени давать сбои.
Другой подход заключается в предотвращении атаки с внедрением мгновенных данных до того, как она достигнет LLM. Обычно это предполагает использование специализированного детектора LLM для определения того, содержат ли данные, отправляемые в исходный LLM, какие-либо внедрения мгновенных данных. Однако в недавнем исследовании даже самый эффективный детектор полностью не смог обнаружить определенные категории атак с внедрением мгновенных данных.
Третья стратегия сложнее. Вместо того чтобы контролировать входные данные в LLM путем определения наличия или отсутствия внедрения подсказки, цель состоит в разработке политики, которая направляет выходные данные LLM — то есть его поведение — и предотвращает совершение каких-либо вредоносных действий. Некоторые меры защиты в этом направлении довольно просты: например, если LLM разрешено отправлять электронные письма только на несколько предварительно одобренных адресов, то он определенно не будет отправлять информацию о кредитной карте пользователя злоумышленнику. Но такая политика помешала бы LLM выполнять многие полезные задачи, такие как поиск и установление контактов с потенциальными профессиональными партнерами от имени пользователя.
«Задача состоит в том, как точно определить эти политики, — говорит Нил Гонг, профессор электротехники и вычислительной техники в Университете Дьюка. — Это компромисс между полезностью и безопасностью».
В более широком смысле, весь мир агентских технологий борется с этим компромиссом: когда агенты станут достаточно защищенными, чтобы быть полезными? Эксперты расходятся во мнениях. Сонг, чей стартап Virtue AI разрабатывает платформу безопасности для агентов, говорит, что, по ее мнению, безопасное развертывание персонального помощника на основе ИИ возможно уже сейчас. Но Гонг говорит: «Мы еще не достигли этого».
Даже если агентов ИИ пока нельзя полностью защитить от мгновенного внедрения вредоносного кода, безусловно, существуют способы снизить риски. И вполне возможно, что некоторые из этих методов можно было бы реализовать в OpenClaw. На прошлой неделе на первом мероприятии ClawCon в Сан-Франциско Штейнбергер объявил, что привлек специалиста по безопасности для работы над этим инструментом.
На данный момент OpenClaw остается уязвимым, хотя это не отпугивает множество его преданных пользователей. Джордж Пикетт, волонтер, поддерживающий репозиторий OpenGlaw на GitHub и поклонник этого инструмента, говорит, что принял ряд мер безопасности, чтобы обезопасить себя при его использовании: он запускает его в облаке, чтобы не беспокоиться о случайном удалении данных с жесткого диска, и внедрил механизмы, гарантирующие, что никто другой не сможет подключиться к его ассистенту.
Но он не предпринял никаких конкретных действий для предотвращения мгновенной инъекции. Он осознает риск, но говорит, что пока не видел никаких сообщений о подобных случаях с OpenClaw. «Возможно, моя точка зрения несколько нелепа, но вряд ли я стану первым, кого взломают», — говорит он.
Источник: www.technologyreview.com