
Коллектив ученых из Московского физико-технического института (МФТИ) разработал и теоретически обосновал два новых подхода к решению одной из фундаментальных проблем машинного обучения: определению достаточного размера выборки. Их работа, опубликованная в Computational Management Science, предлагает измерять, насколько «уверенность» модели в своих параметрах меняется при добавлении или удалении всего одного элемента данных, используя для этого два различных математических инструмента.
Машинное обучение и искусственный интеллект произвели революцию во многих сферах, от медицины до финансов и транспорта. В основе их успеха лежит способность обучаться на данных – чем больше качественных данных, тем, как правило, лучше работает модель. Однако сбор, разметка и обработка данных – это дорогостоящий и трудоемкий процесс. Кроме того, обучение сложных моделей на огромных массивах данных требует значительных вычислительных ресурсов.
Поэтому перед исследователями и инженерами всегда остро стоит вопрос: сколько данных достаточно. Слишком мало данных – и модель получится неточной, неспособной к обобщению на новые примеры (неадекватной). Слишком много – и мы потратим лишние время, деньги и вычислительные мощности без существенного улучшения результата. Найти ту «золотую середину», достаточный размер выборки, – критически важная задача при построении эффективной модели машинного обучения.
На протяжении десятилетий было предложено множество методов для оценки достаточного размера выборки. Несмотря на разнообразие подходов, многие существующие методы либо не имеют строгих доказательств своей корректности в общем случае, либо привязаны к специфическим статистическим гипотезам, либо сложны в применении. Оставалась потребность в методах, которые были бы одновременно теоретически обоснованы и практически применимы для оценки достаточности данных с точки зрения стабильности самой модели.
Исследователи из МФТИ Никита Киселев и Андрей Грабовой предложили взглянуть на проблему достаточности выборки под новым углом. Их ключевая идея проста и интуитивна: если данных уже достаточно, то добавление или удаление всего одного объекта не должно сильно менять «убеждения» модели о ее параметрах.
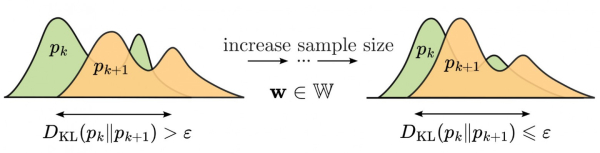
Математически эти «убеждения» выражаются через апостериорное распределение параметров – вероятностное описание того, какие значения параметров наиболее правдоподобны после анализа имеющихся данных. Задача свелась к тому, чтобы измерить, насколько близки апостериорные распределения, полученные на двух похожих подвыборках (например, на выборке из k объектов и на выборке из k+1 объектов). Если это различие (или, наоборот, сходство) достигает определенного порога и перестает существенно меняться с дальнейшим увеличением k, можно считать, что выборка стала достаточной.
Авторы предложили и исследовали два конкретных способа измерения близости апостериорных распределений pk(w) (на k объектах) и pk+1(w) (на k+1 объекте).
Первый из этих методов основан на расстоянии Кульбака-Лейблера. Это расстояние определяет величину расхождения между двумя распределениями, основываясь на теории информации. Оно равно величине потерь информации при замене первого из этих распределений на второе распределение при условии, что первое распределение мы считаем истинным, а второе предполагаемым (проверяемым).

Второй из этих методов основан на введенной в диссертации Александра Адуенко функции схожести s-score, которая оценивает близость двух распределений на основе степени их перекрытия друг к другу. Эта функция равна нулю, если они совсем не перекрываются, и стремится к единице, если распределения очень близки друг к другу.
Ключевой частью работы стало теоретическое обоснование двух новых методов. Ученые из МФТИ строго доказали, что если апостериорное распределение параметров модели является нормальным (гауссовым), то при увеличении размера выборки расстояние Кульбака-Лейблера действительно стремится к нулю, а s-score – к единице, при условии, что средние значения матрицы ковариации (Σk) этих распределений сходятся. Более того, для важного частного случая – линейной регрессии с нормальным априорным распределением (где апостериорное распределение как раз будет нормальным) – они доказали, что эти средние и ковариации действительно сходятся при довольно мягких условиях.
Для практической проверки теоретических выводов и сравнения методов были проведены обширные вычислительные эксперименты. На синтетических данных и реальном наборе данных было показано, что значения расстояния Кульбака-Лейблера действительно убывают к нулю, а s-score растут к единице с увеличением размера выборки k, как и предсказывает теория.


Оба метода были применены к нескольким реальным наборам данных для задачи регрессии (Boston, Diabetes, Forestfires, Servo) и сравнены с 9 другими существующими методами (статистическими, байесовскими, эвристическими). Для сравнения использовался порог ε = 0.05. Исследовалось, как рекомендуемый достаточный размер выборки m* меняется в зависимости от общего доступного размера выборки m для разных методов. Исследование принесло несколько важных результатов.
Сравнение методов между собой показало, что метод на основе расстояния Кульбака–Лейблера является более консервативным – он склонен требовать значительно больший размер выборки для достижения порога достаточности. Метод на основе s-score, напротив, оказался более оптимистичным, часто указывая на достаточность уже при небольших размерах выборки. Авторы исследования объясняют это тем, что s-score менее чувствителен к изменениям в «разбросе» (ковариации) распределения и был изначально разработан для сравнения моделей даже при неинформативных (широких) распределениях.
«Вопрос ‘Хватит ли данных?’ – один из самых насущных в современном машинном обучении, влияющий на стоимость и время разработки, – рассказал Андрей Грабовой, доцент кафедры интеллектуальных систем МФТИ. – Мы предложили смотреть на стабильность ‘знаний’ самой модели. Если добавление одного нового примера уже почти не меняет ее представлений о мире, возможно, пора остановиться. Наши методы дают два разных ‘измерителя’ этой стабильности. KL-дивергенция подскажет, когда модель станет очень ‘уверенной’ и стабильной, требуя больше данных, а s-score может сработать раньше, если мы готовы принять чуть большую неопределенность».
Никита Киселев, студент 5-го курса МФТИ, добавил: «Мы предложили и обосновали два новых способа оценки достаточности данных, основанных на фундаментальном принципе стабильности модели. Они дают практические инструменты для принятия решений о сборе данных, причем выбор между ними позволяет быть либо более осторожным, либо более оптимистичным в своей оценке»
Понимание того, когда данных достаточно, критически важно для разработки любых ИИ-систем. Оно дает экономию ресурсов на всех этапах – от сбора и разметки данных до вычислений при обучении. Методы могут использоваться как для планирования, так и для мониторинга в процессе сбора данных.
Источник: habr.com

























