Это первая статья из серии «Строим корпоративную GenAI-платформу: от концепции до ROI». В этой серии я расскажу, как компаниям подойти к внедрению генеративного ИИ (GenAI) системно, чтобы получить пользу и избежать подводных камней.
Кому будет полезно. В первую очередь ИТ-архитекторам, инженерам по ИИ и руководителям в технологиях. Я разберу путь от первых концепций до измеримых результатов (ROI) и постараюсь дать практические рекомендации на каждом этапе.
О серии статей. Каждая статья посвящена ключевому этапу или аспекту корпоративной GenAI-платформы. Ниже представлен план всей серии статей и их краткое описание.
Зачем GenAI нужна особая архитектура. Вводная статья (вы читаете ее сейчас): разбираемся, чем генеративный ИИ отличается от привычных ИИ и корпоративного ПО, почему недостаточно «просто прикрутить GPT к чату», с какими сложностями и рисками столкнется бизнес и почему нужен архитектурный подход, а не только тонкая настройка промтов.
Архитектура корпоративной GenAI-платформы: ключевые компоненты. Рассматриваем референсную архитектуру GenAI-решения для предприятия: какие модули входят (от retrieval-сервисов до guardrails), как данные и модели взаимодействуют, где хранится знание и как обеспечиваются безопасность и масштабирование (будут схема и примеры).
Интеграция знаний: Retrieval-Augmented Generation (RAG) на службе GenAI. Погружаемся в подход RAG (генерация с дополнением из базы знаний): как связать GPT-модель с вашими корпоративными данными. Обсудим организацию retrieval-слоя (поиска по внутренним данным), векторные базы данных, обновление контекста и кейсы, где RAG решает проблему устаревших знаний и галлюцинаций.
Безопасность и ограничения (guardrails): обуздать галлюцинации и защитить данные. Отдельно про риски и меры безопасности. Расскажем о «галлюцинациях» моделей и методах борьбы с ними, о prompt guardrails (правилах и фильтрах для ввода-вывода), предотвращении утечек конфиденциальной информации, контроле качества ответов и соответствия регуляторным требованиям в высокорегулируемых отраслях.
От пилота до ROI: внедрение GenAI и измерение эффекта. Завершающая статья о том, как запустить GenAI-решение в компаниях: выбор сценариев с максимальной отдачей, запуск пилотных проектов, обучение пользователей, масштабирование успешных кейсов. Отдельно поговорим, как считать ROI: какие метрики применять и как доказать бизнес-ценность внедрения Generative AI.
Об авторе. Меня зовут Денис Прилепский. Уже 15 лет работаю в технологическом консалтинге. Моя специализация — архитектура ИТ-систем и трансформация ИТ-ландшафта. За последние пару лет участвовал во внедрении GenAI-решений в высокорегулируемых отраслях (финансы, телеком, здоровье), где особенно важно обеспечить безопасность данных и соответствие требованиям регуляторов. Буду рад поделиться накопленным опытом и наблюдениями.
Чем Generative AI отличается от «обычного» ИИ и корпоративного софта
Сегодня генеративный ИИ (Generative AI, GenAI) у всех на слуху, но что делает его особенным по сравнению с «классическим» искусственным интеллектом и традиционными enterprise-системами?
Критерий | Классический AI/ML | Generative AI (GenAI) | Традиционное ПО |
Цель | Анализ, классификация, прогноз | Генерация нового контента | Строго заданные действия |
Знания | Зашиты в модели | Комбинация модели и внешнего контекста | Заложены разработчиками вручную |
Поведение при неопределенности | Возвращает ошибку или «не знаю» | Генерирует наиболее вероятный ответ | Ограничен возможными сценариями |
Гибкость | Средняя (нужна дообучаемость) | Высокая, работает с произвольными задачами | Низкая, нужно переписывать код |
Риск галлюцинаций | Минимальный | Высокий без дополнительных мер | Исключен |
Ключевое отличие в том, что именно он умеет делать.
Если традиционные AI/ML-системы обычно занимаются анализом данных, классификацией, предсказаниями (по сути, распознают шаблоны и отвечают в рамках заранее обученных категорий), то GenAI способен создавать новый контент на основе обучающих данных. Другими словами, обычный узкоспециализированный ИИ прекрасно распознает и прогнозирует, а генеративный — генерирует: пишет текст, сочиняет изображения, код и т. д., выходя за рамки четко запрограммированных ответов.
Такой творческий потенциал достигается благодаря большим языковым моделям (LLM) и другим deep learning-моделям, обученным на огромных объемах данных. У них нет жестко прописанных правил поведения; вместо этого модель сама выявляет сложные закономерности и учится воспроизводить стиль и содержание, присущие человеческому творчеству. В итоге GenAI-система может вести диалог «человеческим» языком, писать осмысленные статьи или программный код по простому описанию. Это разительно отличается от типичного enterprise-софта, где каждая функция продумана и закодирована инженерами заранее.
Однако такая гибкость GenAI — палка о двух концах. Модель не опирается на фиксированный набор правил или базу знаний, а предсказывает наиболее вероятный продолженный текст, исходя из паттернов в данных. Поэтому внутри нее нет гарантий истинности или корректности ответа. Если традиционное приложение или ML-модель в тех же условиях просто скажет «не знаю» или вернет ошибку, то генеративная модель всегда что-нибудь да сгенерирует — иногда совершенно неправдоподобное. Эта особенность рождает и уникальные проблемы (о них ниже), и требует нового подхода к архитектуре подобных решений.
Почему «встроить GPT в чат» — еще не внедрить GenAI-решение
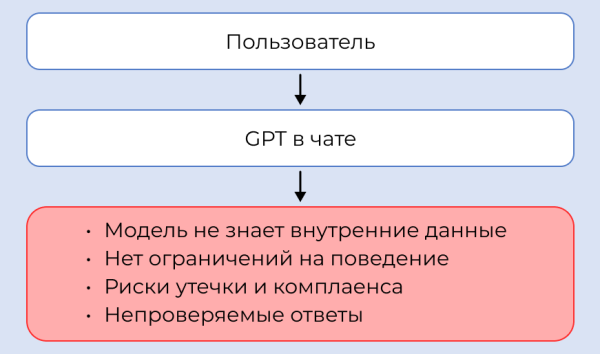
Многие компании, впечатлившись возможностями ChatGPT, начинают с простого: интегрируют крупную языковую модель в чат-бота или внутренний ассистент — мол, пусть отвечают на вопросы пользователей. На пилотном демо это выглядит магически: задаешь вопрос — получаешь развернутый ответ. Но попытка ограничиться лишь этим зачастую терпит фиаско, потому что полноценное корпоративное GenAI-решение — это гораздо больше, чем вызов внешнего API с моделью.
Представьте, вы просто подключили GPT-4 к интерфейсу чата для сотрудников. Сперва все отлично: модель отвечает на общие вопросы. Но очень скоро всплывут проблемы:
Контекст и данные. Пользователи хотят получать ответы на базе внутренней информации компании: документов, базы знаний, политики фирмы. Модель же из коробки знает только то, чему обучена (к тому же на данных ограниченной давности). Без специального механизма retrieval (поиска релевантных данных) и обновления контекста модель начнет либо отвечать общими фразами, либо придумывать факты. Простое «подключение к чату» этого не дает.
Настройка под бизнес-логику. У каждого предприятия свои процессы и требования. Нужна интеграция с существующими системами: CRM, базы клиентов, каталоги товаров и т. п. Также нужны ограничения: например, чтобы бот не выдавал финансовые прогнозы, не согласованные с отделом рисков, или не разглашал конфиденциальные сведения. Без архитектуры, задающей эти правила (guardrails, «ограничители» поведения), GPT-модель может ответить лишнее или действовать не в интересах бизнеса.
Безопасность и приватность. При прямом использовании облачного API встает вопрос: а куда уходят вводимые пользователями данные? Не отправляем ли мы внутренние секреты в сторонний облачный сервис? Многие компании (особенно в Европе под GDPR, да и у нас) просто запрещают сотрудникам использовать публичные инструменты вроде ChatGPT именно из-за риска утечки. Внедряя GenAI, нужно учесть размещение модели (в облаке или on-premises), шифрование данных, контроль доступа — иначе интеграция не пройдет проверку службы безопасности.

Таким образом, получить от GenAI реальную пользу в корпоративной среде можно только при комплексном подходе. Необходимо спроектировать решение так, чтобы модель была лишь одним из компонентов, а вокруг нее работала инфраструктура для доставки нужного контекста, фильтрации и постобработки ответов, аудита действий и т. д. Просто «прикрутить GPT к чату» все равно что посадить сверхумного стажера на линию поддержки без инструкций и без доступа к базам знаний: эффектно, но непредсказуемо и рискованно.

Например, Microsoft при внедрении Copilot в продукты не просто вставила вызов GPT-4, а переосмыслила пользовательский сценарий целиком: добавила уровень размышления над текстом, подключила специфические знания, ввела ограничения по стилю ответов. Правильная архитектура GenAI-платформы именно этим и занимается: связывает модель с данными компании, обвешивает проверками и балансирует нагрузки. Далее мы подробнее рассмотрим, какие сложности приходится решать такой архитектуре.

Основные сложности внедрения GenAI в компании
Когда начинаешь использовать генеративный ИИ в реальных корпоративных кейсах, быстро выявляется набор специфических проблем и ограничений. Рассмотрим главные из них и почему без их решения GenAI не полетит.
Галлюцинации (hallucinations). Модель может с уверенным видом выдавать неправду — придумывать несуществующие факты, ссылки на несуществующие документы, «галлюцинировать» фрагменты кода. Для бизнеса такие выдумки не безобидны: они ведут к ошибочным решениям, нарушению регламентов, потере доверия. В мире ИИ это просто баг модели, а в корпоративной среде — прямой риск комплаенса и репутации.
Представьте, если аналитический GenAI-бот «случайно» вставит лишний ноль в финансовый отчет или добавит юридически некорректное условие в договор. Без дополнительных мер контроля качества ответы модели нельзя пускать в свободное плавание. Позже в серии мы обсудим механизмы, как снизить галлюцинации (например, через RAG и валидацию ответов), но проблема остается фундаментальной: LLM не знает, что истинно, а что нет.
Утечки данных и конфиденциальность. GenAI-модели склонны болтать лишнее, если их не оградить. С одной стороны, внешние модели (типа GPT) могут хранить и использовать переданную им информацию, что опасно, если туда попадают внутренние данные. С другой стороны, сами ответы модели могут выдать конфиденциальные сведения. Например, атаки через промты (prompts) позволяют злоумышленнику обмануть бота и вытянуть секреты компании.
Обратная ситуация: сотрудники могут нечаянно «слить» информацию, вводя рабочие данные в публичные инструменты. Известен случай, когда инженеры Samsung загрузили в ChatGPT конфиденциальный исходный код. В результате компания срочно запретила использование внешних GenAI-сервисов сотрудниками.
Информационная безопасность — один из главных блокеров для корпоративного GenAI, и архитектура решения обязана предусмотреть защиту: шифрование, on-prem развертывание моделей, контроль прав доступа, удаление чувствительных данных из промта и ответов и т. д.
Лимиты контекста и токенов. Современные LLM имеют фиксированное ограниченное «контекстное окно» — максимум токенов, которые модель обрабатывает за один запрос. Например, базовый GPT-3.5 принимает около 4096 токенов (~3 страницы текста), GPT-4 — 8192 токена (до ~5–6 страниц) в стандартной версии. Если вы хотите, чтобы ассистент прочитал и проанализировал документ на 50 страниц, он просто не влезет в промпт без специальной обработки. Нужно делить текст на части, резать историю диалога, использовать техники вроде retrieval (поиск по базе с выборкой только релевантных абзацев).
Помимо объема, есть лимиты и на скорость генерации: модель выдает текст токен за токеном, и длинный ответ может технически прерваться, достигнув максимума. Архитектура GenAI-решения вынужденно включает менеджмент контекста: отслеживать, сколько токенов занято вопросом и предыдущей историей, уметь сбрасывать или ужимать контекст, суммировать содержимое. Это добавляет сложности в разработке, но без этого никак, если не хотите, чтобы ответы обрывались или игнорировали половину входных данных.
Latency (задержки отклика). Запрос к большой модели — не мгновенная операция. Если небольшая ML-модель отработает за доли секунды, то генеративная модель типа GPT-4 может думать несколько секунд или даже минуту, особенно при сложном запросе. В онлайновых сценариях (чат с клиентом, поддержка) такие задержки критичны: пользователь не будет ждать 60 секунд ответа. Кроме того, типичная архитектура GenAI часто многошаговая: сначала мы ищем информацию (RAG запросы в базу знаний), потом формируем промпт, потом вызываем LLM, потом еще фильтруем и форматируем ответ. Каждый шаг добавляет пару сотен миллисекунд или больше. В сумме легко получить секунды. Поэтому нужно оптимизировать каждый компонент: и модель (выбирать поменьше, где допустимо), и окружение (кешировать результаты, параллелить запросы). Latency — частый враг UX, и архитектура должна его побеждать.
Постоянное обновление знаний. Модели вроде GPT-3.5 или GPT-4 обучены на статичных датасетах, актуальных на определенную дату. В мире же информация меняется каждый день: появляются новые продукты, правила, события. Корпоративный ИИ-помощник без обновлений быстро устареет, например, он не будет знать о новых ценах, свежих регуляторных требованиях или последних инцидентах в компании.
Переобучать большую модель — дорого и долго, а иногда вообще невозможно (если используем закрытый API). Поэтому архитектуру строят так, чтобы отделить знания от модели. Используют базы знаний, подключение к источникам данных в реальном времени, все тот же подход RAG (когда модель дополняет свой ответ найденными актуальными фактами).
Иначе говоря, знания в GenAI-решении — динамический компонент: нужна система, которая их хранит, обновляет и подкладывает модели на лету. Без этого ценность решения снижается с каждым днем после его запуска, ведь вокруг все меняется, а «мозги» остаются на уровне момента тренировки.
Как видим, сложности масштабируются: от качества генерации (галлюцинации) и безопасности информации до технических ограничений инфраструктуры (токены, скорость, актуальность данных). Каждая из этих проблем управляется не только настройкой самой модели, но и внешними по отношению к модели инструментами. Например, чтобы модель не галлюцинировала, ей дают проверенный контекст (через поисковый модуль) и внедряют постфактум проверку ответов; чтобы защититься от утечек, ставят фильтры и маркируют конфиденциальные части, обучают модель отказывать на опасные запросы.
Возникает вопрос: а какие риски несет каждая из этих проблем для бизнеса, и как их классифицировать, чтобы не упустить ничего при проектировании?
Виды рисков при внедрении GenAI
При планировании корпоративной платформы генеративного ИИ стоит заранее оценить риски — и технологические, и организационные. На базе своего опыта я разделяю риски на четыре большие группы: регуляторные, информационные, пользовательские и архитектурно-технологические.
Регуляторные риски. Все, что связано с соответствием законам, нормам и требованиям отрасли. GenAI может непреднамеренно нарушить правила — выдать совет, противоречащий, например, требованиям ЦБ или GDPR, или сгенерировать текст, нарушающий права автора. Если система предоставляет юридическую или финансовую информацию, высок риск, что «галлюцинация» приведет к несоблюдению нормативов. Комплаенс-отдел будет строго следить, чтобы ИИ-ассистент не увел компанию в штрафы и суды. Отсюда требование: прозрачность и контроль. Нужно логировать и отслеживать ответы, вводить ограничения на темы, где модель может ошибиться, и вовремя обновлять ее в соответствии с новыми законами. В ряде отраслей (медицина, финансы) регуляторно скорее вообще запретят автономные решения без human-in-the-loop. Это тоже надо учитывать в архитектуре (предусмотреть подтверждение критичных ответов человеком-экспертом).
Информационные риски. Это риски, связанные с данными и знаниями: утечка конфиденциальной информации, нарушение тайны, искажение данных. Примеры мы уже привели: модель может выдать внутреннюю информацию посторонним (если ее взломать через промты), или сотрудники могут загрузить данные, которые «утекут» наружу. Сюда же относятся вопросы авторского права: генерируемый контент может основываться на чьих-то защищенных данных (код, тексты) — кто будет владеть результатом? Не получит ли компания иск за плагиат? Кроме того, информационный риск — это и ложная информация: если ИИ выдает клиенту неточные данные о продукте, пострадает репутация. Исследования показывают, что галлюцинации LLM могут серьезно дезинформировать пользователей и приводить к реальным последствиям — от вреда для здоровья до финансовых потерь. Поэтому информация, которая выходит из модели, должна проверяться и фильтроваться. Нужно продумывать политику использования: какие данные можно скармливать модели, а какие — никогда. Часто приходится внедрять on-prem версии моделей, чтобы гарантировать, что данные никуда не уходят, а также инструменты DLP (pre-prompt и post-prompt фильтры), которые вычищают конфиденциальные детали из запросов и ответов.
Пользовательские риски. Здесь речь о том, как GenAI влияет на пользователей — будь то сотрудники компании или клиенты. Во-первых, риск того, что пользователь получит нежелательный или вредный контент: оскорбительный, предвзятый, неправильный. С нейросетями уже были инциденты, когда чат-бот начинал токсично общаться или выдавал откровенно фейковую информацию с уверенным видом. Это бьет по доверию: внутренние пользователи перестанут доверять инструменту (и вернутся к старым методам), а внешние клиенты перестанут доверять бренду компании. Во-вторых, этические аспекты: генеративный ИИ может случайно нарушить этические нормы компании, например, дав завуалированный дискриминационный совет. Или, наоборот, пользователи могут начать слишком полагаться на ИИ там, где нужна экспертиза человека (риск ошибок из-за overreliance). Отдельно стоит упомянуть, что если GenAI-решение сделано плохо (тормозит, часто ошибается), это испортит пользовательский опыт и восприятие всей цифровой трансформации. В итоге пользовательские риски требуют внедрения guardrails на уровне интерфейса: контент-фильтры, ограничения на некоторые ответы, понятные пользователю индикаторы достоверности (AI-модель может ошибаться) и механизмы обратной связи, чтобы люди могли сообщить о неправильном ответе.
Архитектурно-технологические риски. Последняя группа — внутренние риски самого решения как части ИТ-ландшафта. Сюда относятся вопросы надежности, масштабируемости, стоимости владения и интеграции. Пример: если сделать GenAI-сервис обособленно, в виде отдельного чат-бота, не подумав об интеграции, есть риск получить набор разрозненных тулов, не встраивающихся в процессы. Уже сейчас в некоторых компаниях десятки команд пилотно прикручивают GPT к своим задачам. Если не подумать архитектурно, разрастется зоопарк несвязанных решений.
Другой риск — масштабирование и нагрузка: модель может работать нормально на десятке запросов, но что если их станет тысяча в минуту? Непроработанная архитектура ляжет или начнет выдавать ошибки. Также важен vendor lock: построив всю логику только под одну платформу (например, OpenAI API), компания рискует зависеть от нее по цене и доступности.
Не менее значим риск стоимости: генеративные модели недешевы в эксплуатации, и без оптимизаций бюджеты на запросы к API могут неожиданно взлететь. Архитектурные решения здесь — кеширование результатов, подбор оптимальных моделей (где-то достаточно более простой и дешевой), мониторинг использования.
Ну и, разумеется, безотказность и поддержка: GenAI-платформа должна вписаться в существующий ландшафт с точки зрения резервирования, мониторинга, быстрого восстановления при сбоях. Если не заложить это, любое падение внешнего сервиса приведет к простоям бизнес-процессов.
Как видно из описания выше, эти группы рисков частично пересекаются (например, утечка данных — это и информационный риск, и нарушение регуляций одновременно), но в целом дают четкую рамку для анализа. При старте проекта внедрения генеративного ИИ в корпорации стоит пройтись по каждой группе рисков и задать вопрос: что мы делаем, чтобы этот риск снизить? Такой подход поможет не увлечься только технологиями, но и закрыть организационные и юридические аспекты.
Вывод: нужна продуманная архитектура, а не только промты
Подведем итог. Генеративный ИИ открывает потрясающие возможности — от автоматизации рутины до новых инсайтов — и явно станет неотъемлемой частью корпоративных ИТ в ближайшие годы. Однако, как мы разобрали, особенности GenAI требуют особого подхода. Это не просто еще один софтверный модуль, который можно подключить по API и забыть. Напротив, чтобы GenAI работал надежно и безопасно, его нужно встроить в корпоративный контур с умом: обеспечить поступление актуальных знаний (через RAG-слой), оградить от нежелательного поведения (через guardrails и модерацию), вписать в существующие системы и процессы.
Главная мысль, которую я хочу донести: внедрение GenAI — это, прежде всего, архитектурная задача. Нельзя свести ее лишь к мастерству в составлении промтов. Да, prompt engineering важен, но без системного фундамента он не даст устойчивого результата. Эксперты справедливо советуют подходить к Generative AI платформенно: не плодить неконтролируемый скоуп из пилотов-однодневок, а изначально строить решение как часть цифровой экосистемы компании. Это включает интеграцию с данными и сервисами, учет требований безопасности, возможность масштабирования и обновления. Только при таком подходе инвестиции в GenAI смогут перейти из стадии экспериментов к реальному эффекту на бизнес и принести тот самый ROI, ради которого все затевалось.

В следующих статьях серии мы детально рассмотрим, как именно спроектировать такую архитектуру GenAI-платформы и реализовать все необходимые компоненты. Поговорим про конкретные технологии и принципы: что включает слой знаний и векторное хранилище данных, как реализовать поиск и ранжирование документов для модели (retrieval), как работать с разными LLM (от GPT-4 до локальных open-source моделей) и какой выбрать стек. Отдельно уделим внимание теме безопасности: механизмам контент-фильтрации, контролю запросов (чтобы не было injection-атак) и мониторингу качества ответов.
Надеюсь, вводная часть была полезной и задала общий вектор. Дальше будет еще интереснее: разберем GenAI «под капотом» и шаг за шагом построим корпоративную платформу, которая превращает хайп вокруг ИИ в реальные результаты для компании.
Автор: Денис Прилепский — специалист по архитектуре ИТ-систем и трансформации ИТ-ландшафта, приглашенный эксперт онлайн-магистратур Центра «Пуск» МФТИ.
Источник: habr.com