

Мы представляем «спекулятивные каскады» — новый подход, который повышает эффективность LLM и снижает вычислительные затраты за счет сочетания спекулятивного декодирования со стандартными каскадами.
Быстрые ссылки
- Бумага
- Делиться
Модели с линейной архитектурой (LLM) изменили наше взаимодействие с технологиями, обеспечивая работу всего, от расширенных возможностей поиска до креативных помощников в программировании. Но эта мощь имеет свою цену: вывод (процесс генерации ответа) может быть медленным и ресурсоемким с точки зрения вычислений. По мере того, как мы внедряем эти модели для все большего числа пользователей, сделать их быстрее и дешевле без ущерба для качества становится критически важной задачей.
Один из способов достижения этой цели — использование каскадов, которые направлены на оптимизацию эффективности LLM за счет стратегического использования меньших и более быстрых моделей перед запуском более крупной и дорогостоящей LLM. Этот подход предполагает правило отсрочки, согласно которому меньшая модель решает, может ли она обработать запрос или ей необходимо передать задачу более мощной, но более дорогой, большой модели. Цель состоит в том, чтобы обрабатывать как можно больше данных дешево и быстро, неся высокие затраты на большую LLM только для сложных задач, которые действительно требуют ее расширенных возможностей, что потенциально может обеспечить выгодный компромисс между стоимостью и качеством. Каскады отдают приоритет снижению вычислительных затрат и эффективному распределению ресурсов, допуская при этом некоторую вариативность качества.
Другой подход, спекулятивное декодирование, оптимизирует задержку и пропускную способность LLM без изменения конечного результата . Это достигается за счет использования меньшей и более быстрой модели «черновика» для прогнозирования последовательности будущих токенов. Затем эти предполагаемые токены быстро проверяются параллельно большей моделью «цели». Если черновик принят, большая модель фактически генерирует несколько токенов за один шаг, значительно ускоряя процесс и гарантируя, что конечный результат будет идентичен тому, что большая модель сгенерировала бы самостоятельно. Этот подход отдает приоритет снижению скорости и задержки, потенциально за счет увеличения использования памяти и меньшей экономии вычислительных ресурсов, поскольку большая модель все еще выполняет значительную работу.
В статье «Ускорение каскадирования с помощью спекулятивного декодирования» мы представляем «спекулятивное каскадирование» — новый подход, сочетающий в себе лучшие качества каскадирования и спекулятивного декодирования. Он обеспечивает лучшее качество выходных данных LLM при меньших вычислительных затратах, чем любой из этих методов по отдельности, иногда отдавая предпочтение меньшему значению LLM в целях повышения эффективности. Мы протестировали новые методы спекулятивного каскадирования по сравнению со стандартными базовыми методами каскадирования и спекулятивного декодирования, используя модели Gemma и T5, на различных языковых задачах, включая суммаризацию, перевод, рассуждения, кодирование и ответы на вопросы. Результаты показывают, что предложенные методы спекулятивного каскадирования обеспечивают лучшее соотношение затрат и качества, часто демонстрируя более высокое ускорение и лучшие показатели качества по сравнению с базовыми методами.
Более подробный анализ
Чтобы полностью понять и оценить подход спекулятивных каскадов, сначала сравним каскады и спекулятивное декодирование на простом примере. Представьте, что вы задаете магистру права простой вопрос:
Задание: » Кто такой Базз Олдрин? «
Допустим, у нас есть две модели, способные ответить на этот вопрос: небольшая, быстрая модель «проектировщика» и большая, мощная модель «эксперта».
Вот как они могут отреагировать:
- Маленькая модель: Базз Олдрин — американский бывший астронавт, инженер и летчик-истребитель, наиболее известный как второй человек, ступивший на Луну.
- Большая модель: Эдвин «Базз» Олдрин, ключевая фигура в истории освоения космоса, — американский бывший астронавт, инженер и летчик-истребитель, наиболее известный как второй человек, ступивший на Луну.
Обе модели предоставляют отличные, фактически верные ответы, но они несколько по-разному интерпретируют намерения пользователя. Маленькая модель дает краткое, фактическое резюме, в то время как большая модель предлагает более формальный, энциклопедический стиль изложения. В зависимости от потребностей пользователя — будь то быстрый факт или подробный обзор — любой из вариантов ответа может считаться идеальным. Ключевым моментом является то, что они представляют собой два различных, одинаково допустимых стиля.
Теперь давайте посмотрим, как два основных метода ускорения справляются с этой задачей.
При каскадном подходе небольшая модель «черчения» получает запрос первой. Если она уверена в своем ответе, она отвечает. В противном случае она передает всю задачу большой модели «эксперта».
В нашем примере:
- Небольшая модель выдает краткий и правильный ответ.
- Система проверяет уровень своей уверенности и, обнаружив его высоким, отправляет ответ пользователю.
Это работает! Мы быстро получаем отличный ответ. Но процесс последовательный. Если бы небольшая модель не была уверенной в своих результатах, мы бы потратили время на ожидание ее завершения, а затем начали бы создавать большую модель с нуля. Такой последовательный подход «подождем и посмотрим» является фундаментальным узким местом.
При спекулятивном декодировании небольшая модель быстро формирует первые несколько токенов ответа, а большая модель параллельно проверяет их, исправляя первую обнаруженную ошибку.
В нашем примере:
- Небольшая модель начинает свой ответ: [ Buzz , Aldrin , is , an , …]
- Крупная модель подтверждает этот черновик. Ее предпочтительный первый токен — Эдвин .
- Поскольку Базз ≠ Эдвин , первый же токен представляет собой несоответствие.
- Весь черновик отклоняется , и первый токен заменяется на Эдвина . Затем процесс повторяется с этой исправленной точки для генерации остальной части ответа, но первоначальное преимущество в скорости теряется.
Несмотря на то, что небольшая модель дала хороший результат, требование сопоставления с большой моделью по токенам приводит к её отклонению. Мы теряем преимущество в скорости и в итоге получаем ответ, который не обязательно является лучшим. Хотя в приведенном выше примере используется простое правило отклонения при сопоставлении токенов, в полной версии статьи мы также рассматриваем возможность «вероятностного сопоставления», которое обеспечивает большую гибкость при пошаговом сравнении токенов.
Разные цели, разные компромиссы.
Пример с » Баззом Олдрином » демонстрирует принципиальное различие между этими двумя методами, которое суммировано ниже:


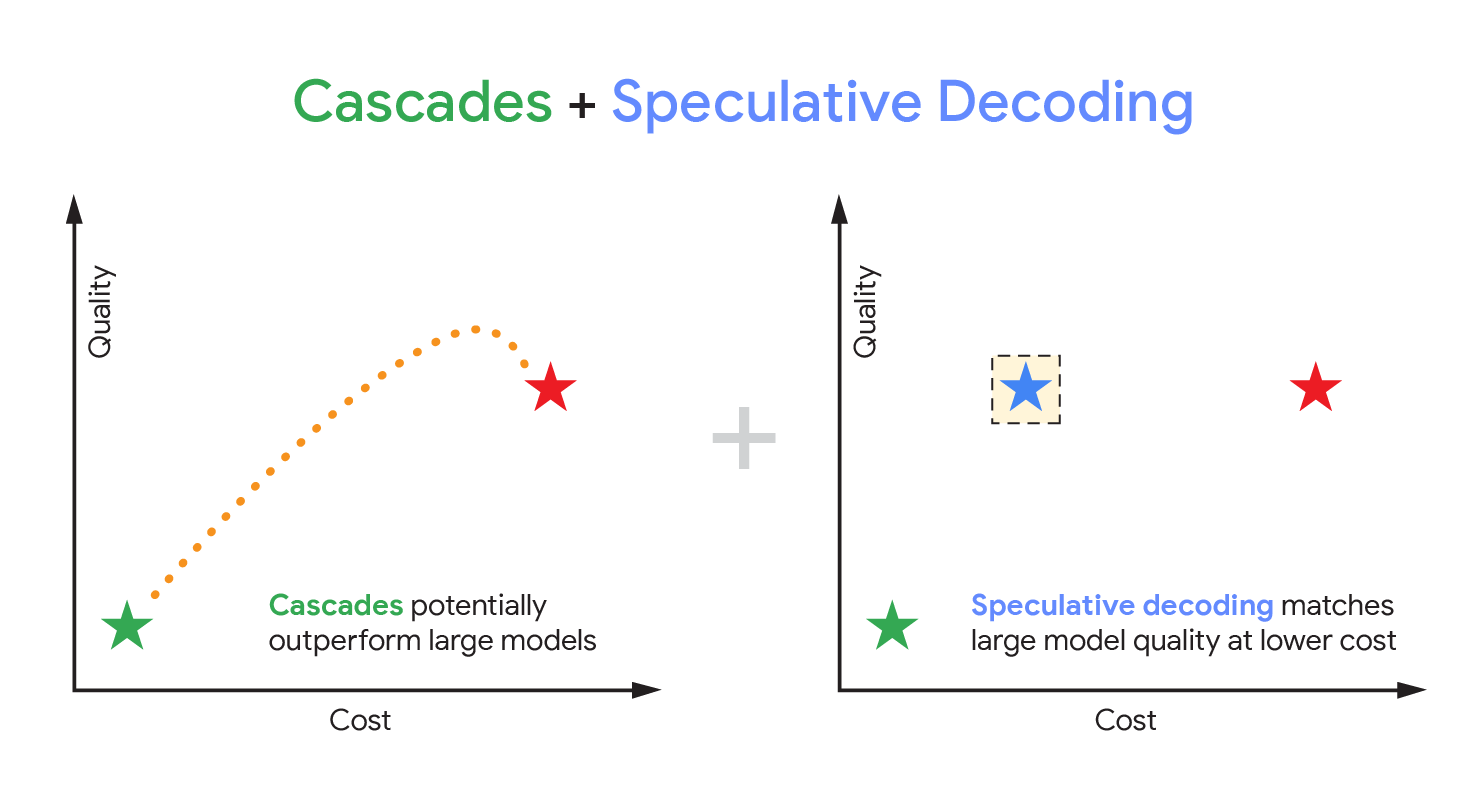
Визуальное представление компромиссов, предлагаемых стандартными каскадами ( слева ) и спекулятивным декодированием ( справа ). На обоих графиках зеленая звезда обозначает небольшую, быструю модель (низкая стоимость, более низкое качество), а красная звезда — большую, медленную модель (высокая стоимость, более высокое качество). Точки на левом графике представляют различные компромиссы, предлагаемые каскадами при изменении порога достоверности; синяя звезда на правом графике представляет компромисс, предлагаемый спекулятивным декодированием.
Спекулятивные каскады: лучшее из двух миров
Спекулятивные каскады сочетают в себе идею многоуровневой обработки из стандартных каскадов с механизмом ускорения спекулятивного декодирования. Они включают в себя создание меньшей моделью «чернового» результата, который затем быстро проверяется параллельно большей моделью. Ключевое нововведение заключается в замене строгой проверки спекулятивного декодирования гибким «правилом отсрочки» . Это правило динамически, для каждого токена отдельно, решает, принимать ли черновой вариант от малой модели или передать его большой модели. Это позволяет избежать последовательного узкого места стандартных каскадов, позволяя системе принимать хороший ответ от малой модели, даже если он не совсем совпадает с предпочтительным результатом большой модели.
В нашем примере:
- Небольшая модель начинает свой ответ: [ Buzz , Aldrin , is , an , …]
- Одновременно с этим, крупная модель оценивает черновик, выдавая собственные баллы.
- Ключевой шаг: гибкое правило отсрочки учитывает оба результата и решает, оправдана ли отсрочка.
- Если система решает не откладывать , она принимает черновые токены небольшой модели. Затем процесс эффективно повторяется с этой новой точки, составляя и проверяя следующий фрагмент текста до тех пор, пока ответ не будет полным.
Преимущество этого метода заключается в его гибкости, поскольку правило отсрочки может быть адаптировано к различным потребностям.
Например, мы могли бы указать системе отложить действие на основе следующих факторов:
- Простая проверка достоверности : откладывайте проверку только в том случае, если небольшая модель не очень уверена в собственном прогнозе.
- Сравнительная проверка : следует отложить проверку, если большая модель демонстрирует значительно большую уверенность, чем малая модель.
- Анализ затрат и выгод : Откладывайте только в том случае, если повышение уверенности в результатах, полученное с помощью большой модели, перевешивает «издержки» отклонения проекта малой модели.
- Проверка на соответствие токену : имея «одобренный список» лучших следующих слов согласно большой модели (ее токены с наивысшим рейтингом), мы откладываем выбор, если выбранный токен малой модели отсутствует в этом списке.
Именно эта способность подключать различные логики принятия решений обеспечивает спекулятивным каскадам уникальное сочетание скорости, качества и адаптивности.

Блок-схема, иллюстрирующая спекулятивный каскад между малой и большой моделями. Как и в стандартном спекулятивном декодировании, процесс составления включает авторегрессивную выборку из малой модели-составителя. Однако процесс проверки отличается: он учитывает объединенное распределение выходных данных как малой, так и большой моделей с помощью правила отсрочки, а не полагается исключительно на выходные данные большой модели.
Ниже мы визуализируем поведение спекулятивного каскадирования и спекулятивного декодирования на примере запроса из набора данных GSM8K. Запрос звучит так: «У Мэри 30 овец. Она получает 1 кг молока от половины из них и 2 кг молока от другой половины каждый день. Сколько молока она собирает каждый день?» Тщательно используя выходные данные небольшой модели на определенных токенах, спекулятивное каскадирование может быстрее получить правильное решение, чем обычное спекулятивное декодирование.

Сравнение спекулятивных каскадов и спекулятивного декодирования на примере задачи по математике для начальной школы из набора данных GSM8K . Черновые варианты ответов показаны желтым цветом, а проверенные — красным. Подход с использованием спекулятивных каскадов генерирует правильный ответ, причем быстрее, чем спекулятивное декодирование.
Эксперименты
Мы протестировали спекулятивные каскады на ряде бенчмарков, включая суммирование, рассуждения и кодирование. Результаты показывают явное преимущество перед спекулятивным декодированием. На стандартном графике «качество против эффективности» спекулятивные каскады неизменно обеспечивают лучшие компромиссы. Это означает, что при том же уровне качества, что и спекулятивное декодирование, наш метод быстрее, то есть генерирует больше токенов за один вызов к более крупной модели.

Варианты спекулятивного каскадного декодирования (синий и оранжевый) обеспечивают лучший компромисс между качеством и задержкой по сравнению со стандартным спекулятивным декодированием (зеленая звезда) в задачах математического рассуждения и суммирования. Подробности см. в статье .
На пути к более быстрому и интеллектуальному искусственному интеллекту с использованием спекулятивных каскадов.
По мере того, как LLM-ы все больше интегрируются в повседневные приложения, оптимизация их производительности становится не просто технической целью, а практической необходимостью. Переосмысление взаимодействия каскадов и спекулятивного декодирования позволяет использовать спекулятивные каскады в качестве более мощного и гибкого инструмента для разработчиков. Этот гибридный подход обеспечивает точный контроль над балансом затрат и качества, открывая путь к созданию более интеллектуальных и быстрых приложений.
Благодарности
Эта работа — результат совместной работы Виттавата Джиткриттума, Анкита Сингха Равата, Сынён Ким, Нехи Гупты и Санджива Кумара. Мы благодарны Ананде Тиртхе Сурешу и Зитенгу Сану за их содержательные дискуссии, а также Йелю Конгу, Марку Симборгу и Кимберли Шведе за помощь в создании этого блога.
Источник: research.google





















