
Хитрости NumPy, о необходимости которых вы даже не подозревали (до сих пор)
Делиться

Я изучаю аналитику данных уже год. Пока что могу считать себя уверенным в SQL и Power BI. Переход на Python оказался весьма интересным. Я познакомился с несколькими изящными и более продуманными подходами к анализу данных.
Освежив свои знания основ Python, идеальным следующим шагом было начать изучать библиотеки Python для анализа данных. NumPy — одна из них. Будучи любителем математики, я, конечно же, с удовольствием бы познакомился с этой библиотекой.
Эта библиотека предназначена для тех, кто хочет выполнять математические вычисления на Python, от элементарной математики и алгебры до сложных понятий, таких как исчисление. NumPy может практически всё.
В этой статье я хотел бы познакомить вас с некоторыми функциями NumPy, с которыми я экспериментировал. Независимо от того, являетесь ли вы специалистом по анализу данных, финансовым аналитиком или просто любителем исследований, эти функции будут вам очень полезны. Итак, без лишних слов, приступим к делу.
Образец набора данных (используется повсюду)
Прежде чем углубляться, я определю небольшой набор данных, который будет объединять все примеры:
импортировать numpy как np temps = np.array([30, 32, 29, 35, 36, 33, 31])
Используя этот небольшой набор данных о температуре, я поделюсь 7 функциями, которые упрощают операции с массивами.
1. np.where() — Векторизованный оператор If-Else
Прежде чем я объясню, что это за функция, вот краткий обзор функции.
arr = np.array([10, 15, 20, 25, 30]) indexs = np.where(arr > 20) print(indexes)
Вывод: (массив([3, 4]),)
np.where — функция, основанная на условии. При указании условия она выводит индекс(ы), для которых это условие выполняется.
Например, в приведенном выше примере указан массив, и я объявил функцию np.where, которая извлекает записи, в которых элемент массива больше 20. Выход — array([3, 4]), поскольку это местоположение/индексы, где это условие выполняется — это будут 25 и 30.
Условный выбор/замена
Это также полезно, когда вы пытаетесь определить пользовательские выходные данные для выходных данных, соответствующих вашему условию. Это часто используется в анализе данных. Например:
import numpy as np arr = np.array([1, 2, 3, 4, 5]) result = np.where(arr % 2 == 0, 'четное', 'нечетное') print(результат)
Вывод: ['нечетный' 'четный' 'нечетный' 'четный' 'нечетный']
В примере выше предпринимается попытка извлечь чётные числа. После извлечения вызывается функция выбора/замены условий, которая добавляет к нашим условиям пользовательское имя. Если условие истинно, оно заменяется на чётное, а если ложно, оно заменяется на нечётное.
Хорошо, давайте применим это к нашему небольшому набору данных.
Проблема: Заменить все температуры выше 35°C на 35 (ограничить крайние показания).
В реальных данных, особенно полученных от датчиков, метеостанций или вводимых пользователями данных, выбросы — довольно распространенное явление: внезапные скачки или нереалистичные значения, которые не соответствуют действительности.
Например, датчик температуры может на мгновение дать сбой и зафиксировать значение 42°C, хотя фактическая температура составляет 35°C.
Наличие таких аномалий в ваших данных может:
- Исказить средние значения — одно высокое значение может сместить среднее значение вверх.
- Искаженная визуализация — диаграммы могут растягиваться, чтобы вместить несколько крайних точек.
- Вводящие в заблуждение модели — алгоритмы машинного обучения чувствительны к неожиданным диапазонам.
Давайте это исправим.
скорректировано = np.where(temps > 35, 35, temps)
Вывод: массив([30, 32, 29, 35, 35, 33, 31])
Теперь всё выглядит гораздо лучше. Всего несколькими строками кода нам удалось исправить нереалистичные выбросы в нашем наборе данных.
2. np.clip() — Сохранение значений в диапазоне
Во многих практических наборах данных значения могут выходить за пределы ожидаемого диапазона, вероятно, из-за шума измерений, ошибок пользователя или несоответствий масштабирования.
Например:
- Датчик температуры может показывать -10°C, хотя минимально возможная температура составляет 0°C.
- Выходные данные модели могут предсказывать вероятности вроде 1,03 или −0,05 из-за округления.
- При нормализации значений пикселей изображения некоторые из них могут выходить за пределы 0–255.
Эти «выходящие за пределы» значения могут показаться незначительными, но они могут:
- Разбить вычисления по нисходящей (например, логарифмические или процентные вычисления).
- Приводить к появлению нереалистичных графиков или артефактов (особенно при обработке сигналов/изображений).
- Нарушить нормализацию и сделать метрики ненадежными.
np.clip() изящно решает эту проблему, ограничивая все элементы массива заданным минимальным и максимальным диапазоном. Это похоже на установку границ в вашем наборе данных.
Пример:
Проблема: убедиться, что все показания находятся в диапазоне [28, 35].
обрезанный = np.clip(temps, 28, 35) обрезанный
Вывод: массив([30, 32, 29, 35, 35, 33, 31])
Вот что он делает:
- Любое значение ниже 28 становится 28.
- Любое значение выше 35 становится 35.
- Все остальное остается прежним.
Конечно, это также можно сделать с помощью np.where(), например так:
temps = np.where(temps < 28, 28, np.where(temps > 35, 35, temps))
Но я бы предпочел использовать np.clip(), потому что это намного чище и быстрее.
3. np.ptp() — Найдите диапазон данных в одной строке
np.ptp() (от пика до пика) по сути показывает разницу между максимальным и минимальным элементами.
В основном это:
np.ptp(a) == np.max(a) — np.min(a)
Но в одной чистой, выразительной функции.
Вот как это работает
arr = np.array([[1, 5, 2], [8, 3, 7]]) # Вычислить размах всего массива range_all = np.ptp(arr) print(f»Размах всего массива: {range_all}»)
Итак, это будет наше максимальное значение (8) — минимальное значение (1)
Выход: Диапазон амплитуды всего массива: 7
Итак, почему это полезно? Как и в случае со средними значениями, понимание того, насколько сильно варьируются ваши данные, часто бывает не менее важно. Например, в метеорологических данных это показывает, насколько стабильными или изменчивыми были условия.
Вместо того, чтобы по отдельности вызывать max() и min() или вычитать вручную, np.ptp() делает его кратким, читабельным и векторизованным, что особенно полезно при вычислении диапазонов по нескольким строкам или столбцам.
Теперь применим это к нашему набору данных.
Проблема: Насколько сильно колебалась температура на этой неделе?
temps = np.array([30, 32, 29, 35, 36, 33, 31]) np.ptp(temps)
Вывод: np.int64(7)
Это говорит нам о том, что за этот период температура колебалась на 7°C, от 29°C до 36°C.
4. np.diff() — обнаружение ежедневных изменений
Функция np.diff() — самый быстрый способ измерить динамику, рост или спад во времени. По сути, она вычисляет разницу между элементами массива.
Чтобы представить себе картину: если бы ваш набор данных был путешествием, функция np.ptp() сообщала бы вам, какое расстояние вы проехали в целом, а функция np.diff() — какое расстояние вы прошли между каждой остановкой.
По сути:
np.diff([a1, a2, a3, …]) = [a2 — a1, a3 — a2, …]
Давайте применим это к нашему набору данных.
Давайте еще раз посмотрим на наши данные по температуре:
temps = np.array([30, 32, 29, 35, 36, 33, 31]) daily_change = np.diff(temps) print(daily_change)
Выход: [ 2 -3 6 1 -3 -2]
В реальном мире np.diff() используется для
- Анализ временных рядов — отслеживайте ежедневные изменения температуры, продаж или цен на акции.
- Обработка сигналов — выявление всплесков и внезапных падений данных датчиков.
- Проверка данных — обнаружение скачков или несоответствий между последовательными измерениями.
5. np.gradient() — захват плавных трендов и наклонов
Честно говоря, когда я впервые столкнулся с этим, мне было сложно это понять. Но, по сути, np.gradient() вычисляет числовой градиент (плавную оценку изменения или наклона) по вашим данным. Это похоже на np.diff(), однако np.gradient() работает даже если значения x расположены неравномерно (например, нерегулярные временные метки). Он обеспечивает более плавный сигнал, что упрощает визуальную интерпретацию трендов.
Например:
время = np.массив([0, 1, 2, 4, 7]) температура = np.массив([30, 32, 34, 35, 36]) np.градиент(температура, время)
Вывод: массив([2. , 2. , 1.5 , 0.43333333, 0.33333333])
Давайте немного разберемся.
Обычно np.gradient() предполагает, что значения x (позиции индекса) равномерно распределены — например, 0, 1, 2, 3, 4 и т. д. Но в приведенном выше примере массив времени распределен неравномерно: обратите внимание, что скачки — это 1, 1, 2, 3. Это означает, что показания температуры не снимались каждый час.
Передавая время в качестве второго аргумента, мы по сути говорим NumPy использовать фактические временные интервалы при расчете скорости изменения температуры.
Поясним вышеприведённый результат. Он показывает, что в период от 0 до 2 часов температура росла быстро (примерно на 2°C в час), а в период от 2 до 7 часов рост замедлялся до примерно 0,3–1°C в час.
Давайте применим это к нашему набору данных.
Задача: Оценить скорость изменения температуры (например, наклон).
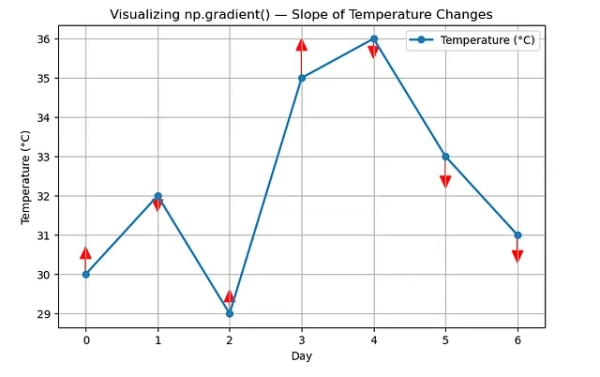
temps = np.array([30, 32, 29, 35, 36, 33, 31]) grad = np.gradient(temps) np.round(grad, 2)
Вывод: массив([ 2. , -0.5, 1.5, 3.5, -1. , -2.5, -2. ])
Вы можете прочитать это так:
- +2 → температура быстро повышается (ранний разогрев)
- -0,5 → небольшое падение (незначительное охлаждение)
- +1,5, +3,5 → сильный подъем (большой скачок температуры)
- -1, -2,5, -2 → устойчивая тенденция к похолоданию
Итак, это история температуры за неделю. Давайте быстро визуализируем это с помощью matplotlib.
Обратите внимание, насколько легко интерпретировать визуализацию. Именно это делает np.gradient() таким полезным.

6. np.percentile() – Выделение выбросов или пороговых значений
Это одна из моих любимых функций. np.percentile() помогает извлекать фрагменты или срезы данных. В Numpy это реализовано очень хорошо.
numpy.percentile вычисляет q-й процентиль данных по указанной оси , где q — процент от 0 до 100.
В np.percentile() обычно есть пороговое значение (100%). Затем можно вернуться назад и проверить процент записей, которые ниже этого порога.
Давайте попробуем это с записями о продажах.
Предположим, ваш ежемесячный план продаж составляет 60 000 долларов.
Вы можете использовать np.percentile(), чтобы понять, как часто и насколько сильно вы достигаете или не достигаете этой цели.
импорт numpy как np продажи = np.массив([45, 50, 52, 48, 60, 62, 58, 70, 72, 66, 63, 80]) np.процентиль(продажи, [25, 50, 75, 90])
Выход: [51,0 61,0 67,5 73,0]
Если разобрать это подробнее:
- 25-й процентиль = 51 тыс. долл. США → 25% ваших месяцев принесли доход ниже 51 тыс. ₦ (низкие показатели)
- 50-й процентиль = 61 тыс. долл. США → половина ваших месяцев была ниже 61 тыс. ₦ (около вашей цели)
- 75-й процентиль = 67,5 тыс. долл. США → самые результативные месяцы значительно превышают целевой показатель
- 90-й процентиль = 73 тыс. долларов США → ваши лучшие месяцы приносят 73 тыс. фунтов стерлингов или больше
Итак, теперь вы можете сказать:
«Мы достигли или превысили нашу цель в 60 тысяч долларов примерно в половине всех месяцев».
Это также можно визуализировать с помощью карты ключевых показателей эффективности (KPI). Это очень эффективный инструмент.
Это повествование о KPI с использованием данных.
Давайте применим это к нашему набору данных о температуре.
импортировать numpy как np temps = np.array([30, 32, 29, 35, 36, 33, 31]) np.percentile(temps, [25, 50, 75])
Выход: [30,5 32. 34,5]
Вот что это значит:
- 25% показаний ниже 30,5°C
- 50% (медиана) имеют температуру ниже 32°C
- 75% — ниже 34,5°C
7. np.unique() — Быстрое нахождение уникальных значений и их количества
Эта функция идеально подходит для очистки, суммирования и категоризации данных. np.unique() находит все уникальные элементы в массиве. Она также может проверить частоту их появления в массиве.
Например, предположим, у вас есть список категорий товаров из вашего магазина:
import numpy as np products = np.array([ 'Обувь', 'Сумки', 'Сумки', 'Шляпы', 'Обувь', 'Обувь', 'Ремни', 'Шляпы' ]) np.unique(products)
Вывод: array(['Сумки', 'Ремни', 'Головные уборы', 'Обувь'], dtype='
Вы можете пойти дальше и подсчитать количество их появлений, используя свойство return_counts:
np.unique(products, return_counts=True)
Вывод: (array(['Сумки', 'Ремни', 'Головные уборы', 'Обувь'], dtype='
Давайте применим это к моему набору данных о температуре. В настоящее время дубликатов нет, поэтому мы просто получим те же входные данные.
импортировать numpy как np temps = np.array([30, 32, 29, 35, 36, 33, 31]) np.unique(temps)
Вывод: массив([29, 30, 31, 32, 33, 35, 36])
Обратите внимание, что цифры также организованы соответствующим образом — в порядке возрастания.
Вы также можете попросить NumPy подсчитать, сколько раз встречается каждое значение:
np.unique(temps, return_counts=True)
Вывод: (массив([29, 30, 31, 32, 33, 35, 36]), массив([1, 1, 1, 1, 1, 1, 1]))
Подведение итогов
Вот те функции, на которые я наткнулся на данный момент. И я считаю их весьма полезными для анализа данных. Прелесть NumPy в том, что чем больше вы с ним экспериментируете, тем больше находите этих крошечных однострочных функций, заменяющих страницы кода. Так что в следующий раз, когда будете обрабатывать данные или отлаживать запутанный набор данных, откажитесь от Pandas и попробуйте использовать одну из этих функций. Спасибо за чтение!
Источник: towardsdatascience.com

























