
От статических векторных представлений к контекстному значению
Делиться

Сегодня последний день моего адвент-календаря по машинному обучению.
Прежде чем завершить эту серию статей, я хотел бы искренне поблагодарить всех, кто следил за ней, оставлял отзывы и поддерживал её, в частности команду Towards Data Science.
Завершение этого календаря темой трансформеров не случайно. Трансформер — это не просто красивое название. Это основа современных больших языковых моделей.
О рекуррентных нейронных сетях (RNN), сетях LSTM и сетях GRU можно много чего сказать. Они сыграли ключевую историческую роль в моделировании последовательностей. Но сегодня современные линейные модели поведения (LLM) в подавляющем большинстве основаны на трансформерах.
Само название «Трансформер» (Transformer) знаменует собой разрыв. С точки зрения именования, авторы могли бы выбрать что-то вроде «нейронные сети с механизмом внимания» (Attention Neural Networks), в соответствии с рекуррентными нейронными сетями или сверточными нейронными сетями. Как человек с картезианским мышлением, я бы оценил более последовательную структуру именования. Но, если отбросить вопрос именования, концептуальный сдвиг, внесенный трансформерами, полностью оправдывает это различие.
Трансформеры могут использоваться по-разному. Архитектуры кодировщиков обычно используются для классификации. Архитектуры декодеров используются для предсказания следующего токена, то есть для генерации текста.
В этой статье мы сосредоточимся только на одной ключевой идее: как матрица внимания преобразует входные векторные представления в нечто более осмысленное.
В предыдущей статье мы представили одномерные сверточные нейронные сети для обработки текста. Мы увидели, что сверточная нейронная сеть сканирует предложение, используя небольшие окна, и реагирует, когда распознает локальные закономерности. Этот подход уже очень эффективен, но у него есть явное ограничение: сверточная нейронная сеть анализирует только локальные данные.
Сегодня мы делаем еще один шаг вперед.
Трансформатор отвечает на принципиально иной вопрос.
А что, если бы каждое слово могло одновременно «смотреть» на все остальные слова?
1. Одно и то же слово в двух разных контекстах.
Чтобы понять, почему необходимо уделять внимание, начнём с простой идеи.
Мы будем использовать два разных входных предложения , в обоих содержится слово «мышь», но в разных контекстах.
В первом варианте ввода слово «мышь» встречается в предложении со словом «кот». Во втором варианте ввода слово «мышь» встречается в предложении со словом «клавиатура».

На входном уровне мы намеренно используем одно и то же векторное представление для слова «мышь» в обоих случаях . Это важно. На данном этапе модель не знает, какое именно значение подразумевается.
Встраивание объекта mouse содержит оба компонента:
- сильный животный компонент
- сильная технологическая составляющая
Эта двусмысленность преднамеренна. Без контекста слово «мышь» может относиться как к животному, так и к компьютерному устройству.
Все остальные слова дают более четкие сигналы. «Кот» — это слово, обозначающее животное. «Клавиатура» — это слово, обозначающее технологию. Слова типа «и» или «или» в основном несут грамматическую информацию. Слова типа «друзья» и «полезный» сами по себе малоинформативны.
На данном этапе ничто во входных эмбеддингах не позволяет модели определить, какое значение слова «мышь» является правильным.
В следующей главе мы шаг за шагом рассмотрим, как матрица внимания выполняет это преобразование.
2. Самовнимание: как контекст вводится в эмбеддинги.
2.1 Самовнимание, а не просто внимание
Для начала уточним, какой именно тип внимания мы здесь используем. Эта глава посвящена самовниманию .
Самовнимание означает, что каждое слово «смотрит» на другие слова той же входной последовательности .
В этом упрощенном примере мы делаем дополнительный педагогический выбор. Мы предполагаем, что запросы и ключи напрямую равны входным эмбеддингам . Другими словами, в этой главе нет обучаемых матриц весов для Q и K.
Это преднамеренное упрощение. Оно позволяет нам полностью сосредоточиться на механизме внимания, не вводя дополнительных параметров. Сходство между словами вычисляется непосредственно на основе их векторных представлений.
В концептуальном плане это означает:
Q = Вход
K = Вход
Для передачи информации на выход используются только векторы значений.
В реальных моделях Transformer параметры Q, K и V получаются посредством обученных линейных проекций. Эти проекции добавляют гибкости, но не меняют саму логику механизма внимания. Упрощенная версия, представленная здесь, отражает основную идею.
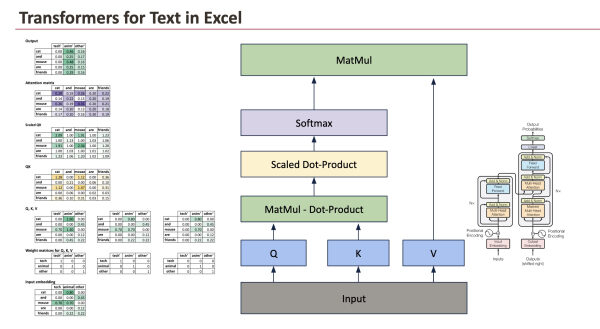
Вот полная картина, которую мы будем анализировать.

2.2 От входных эмбеддингов к исходным показателям внимания
Мы начинаем с входной матрицы векторного представления, где каждая строка соответствует слову, а каждый столбец — семантическому измерению.
Первая операция заключается в сравнении каждого слова с каждым другим словом. Это делается путем вычисления скалярного произведения между запросами и ключами.
Поскольку в этом примере запросы и ключи равны входным векторным представлениям, этот шаг сводится к вычислению скалярного произведения между входными векторами.
Все скалярные произведения вычисляются одновременно с помощью матричного умножения:
Оценка = Входные данные × Входные данныеᵀ
Каждая ячейка этой матрицы отвечает на простой вопрос: насколько похожи эти два слова, учитывая их векторные представления?
На данном этапе значения представляют собой исходные баллы. Это не вероятности, и они пока не имеют прямой интерпретации в качестве весовых коэффициентов.

2.3 Масштабирование и нормализация
Исходные скалярные произведения могут становиться большими по мере увеличения размерности встраивания. Для поддержания значений в стабильном диапазоне оценки масштабируются с помощью квадратного корня из размерности встраивания.
ScaledScores = Баллы / √d
Этот этап масштабирования не является концептуально сложным, но имеет важное практическое значение. Он предотвращает слишком резкое изменение параметров на следующем этапе, при использовании функции softmax.

После масштабирования построчно применяется функция softmax. Это преобразует исходные значения в положительные величины, сумма которых равна единице.
В результате получается матрица внимания .
И вам нужно лишь внимание.
Каждая строка этой матрицы описывает, насколько внимательно данное слово относится к каждому второму слову в предложении.

2.4 Интерпретация матрицы внимания
Матрица внимания является центральным объектом самовнимания.
Для заданного слова его строка в матрице внимания отвечает на вопрос: при обновлении этого слова, какие другие слова имеют значение и в какой степени?
Например, строка, соответствующая слову «мышь», присваивает больший вес словам, семантически связанным в текущем контексте. В предложении со словом «кот и друзья» слово «мышь» больше обращает внимание на слова, связанные с животными. В предложении со словами «клавиатура» и «полезный» оно больше обращает внимание на технические термины.
В обоих случаях механизм идентичен. Только окружающие слова меняют результат.
2.5 От весовых коэффициентов внимания к выходным векторным представлениям
Сама матрица внимания не является конечным результатом. Это набор весов.
Для получения выходных векторных представлений мы объединяем эти веса с векторами значений.
Выход = Внимание × V
В этом упрощенном примере векторы значений берутся непосредственно из входных эмбеддингов. Таким образом, каждый выходной вектор слова представляет собой взвешенное среднее входных векторов, причем веса задаются соответствующей строкой матрицы внимания.
Для такого слова, как «мышь», это означает, что его окончательное представление представляет собой смесь следующих элементов:
- собственное встраивание
- встраивания слов, на которые оно обращает наибольшее внимание
Именно в этот момент в представление вводится контекст.

По завершении механизма самовнимания векторные представления перестают быть неоднозначными.
Слово «мышь» в обоих предложениях имеет разное значение. Его выходной вектор отражает контекст. В одном случае оно ведет себя как животное, в другом — как технический объект.
В таблице встраивания ничего не изменилось. Изменился лишь способ объединения информации между словами.
Это основная идея самовнимания и фундамент, на котором строятся модели Transformer.
Если теперь сравнить два примера: кошку и мышь слева и клавиатуру и мышь справа, эффект самовнимания станет очевидным.
В обоих случаях входное векторное представление слова «мышь» идентично. Однако итоговое представление различается. В предложении со словом «кот» выходное векторное представление слова «мышь» в основном определяется животным аспектом. В предложении со словом «клавиатура» технический аспект становится более выраженным. В таблице векторных представлений ничего не изменилось. Разница обусловлена исключительно тем, как механизм внимания перераспределял веса между словами перед смешиванием значений.
Это сравнение подчеркивает роль самовнимания: оно не изменяет слова изолированно, а перестраивает их представления, учитывая полный контекст.

3. Умение сочетать информацию.

3.1 Введение обученных весов для Q, K и V
До сих пор мы сосредотачивались на механизмах самого самовнимания. Теперь мы вводим важный элемент: выученные веса .
В настоящем трансформере запросы, ключи и значения не берутся непосредственно из входных эмбеддингов. Вместо этого они формируются с помощью обученных линейных преобразований.
Для каждого векторного представления слова модель вычисляет:
Q = Вход × W_Q
K = Вход × W_K
V = Вход × W_V
Эти весовые коэффициенты усваиваются в процессе тренировок.
На этом этапе мы обычно сохраняем ту же размерность. Входные эмбеддинги Q, K, V и выходные эмбеддинги имеют одинаковое количество измерений. Это упрощает понимание роли механизма внимания: он изменяет представления, не меняя пространство, в котором они находятся.
В концептуальном плане эти веса позволяют модели принимать решения:
- Какие аспекты слова важны для сравнения (вопрос и ответ)?
- Какие аспекты слова следует передавать другим (V)

3.2 Чему на самом деле учится модель
Сам механизм внимания фиксирован. Скалярное произведение, масштабирование, функция softmax и умножение матриц всегда работают одинаково. Модель фактически изучает проекции.
Регулируя веса Q и K, модель учится измерять взаимосвязи между словами для заданной задачи. Регулируя веса V, она учится определять, какая информация должна передаваться при высоком уровне внимания. Структура определяет, как передается информация, а веса определяют, какая информация передается.
Поскольку матрица внимания зависит от Q и K, она частично поддается интерпретации. Мы можем исследовать, какие слова привлекают внимание к каким другим, и наблюдать закономерности, которые часто совпадают с синтаксисом или семантикой.
Это становится очевидным при сравнении одного и того же слова в двух разных контекстах. В обоих примерах слово mouse начинается с абсолютно одинакового входного векторного представления, содержащего как компонент животного, так и компонент технологии. Само по себе оно неоднозначно.
Меняется не само слово, а внимание, которое ему уделяется. В предложении со словами «кот и друзья» внимание акцентируется на словах, связанных с животными. В предложении со словами «клавиатура» и «полезный» внимание смещается к техническим словам. Механизм и веса в обоих случаях идентичны, однако выходные векторные представления различаются. Разница заключается исключительно в том, как изученные проекции взаимодействуют с окружающим контекстом.
Именно поэтому матрица внимания поддается интерпретации: она показывает, какие связи модель научилась считать значимыми для данной задачи.

3.3 Намеренное изменение размерности
Однако ничто не обязывает Q, K и V иметь ту же размерность, что и входные данные.
В частности, проекция Value может отображать векторные представления в пространство другого размера. В этом случае выходные векторные представления наследуют размерность векторов Value.
Это не теоретическая диковинка. Это в точности то, что происходит в реальных моделях, особенно в многоголовочных механизмах внимания. Каждая голова работает в своем собственном подпространстве, часто с меньшей размерностью, а результаты впоследствии объединяются в более крупное представление.
Таким образом, внимание может выполнять две функции:
- смешивать информацию между словами
- изменить пространство, в котором хранится эта информация.
Это объясняет, почему трансформеры так хорошо масштабируются.
Они не полагаются на фиксированные характеристики. Они учатся:
- как сравнивать слова
- как маршрутизировать информацию
- как проецировать смысл в различные пространства

Матрица внимания контролирует направление потока информации.
Выученные проекции определяют, какая информация поступает и как она представляется.
Вместе они образуют основной механизм, лежащий в основе современных языковых моделей.
Заключение
Этот адвент-календарь создан на основе простой идеи: понять модели машинного обучения, изучив, как они на самом деле преобразуют данные в электронных таблицах.
Трансформеры — это естественный способ завершить этот путь. Они не полагаются на фиксированные правила или локальные шаблоны, а на изученные взаимосвязи между всеми элементами последовательности. С помощью механизма внимания они преобразуют статические векторные представления в контекстные, что является основой современных языковых моделей.
Трансформеры можно использовать с кодировщиком для задач классификации, а с декодером — для прогнозирования следующего токена и генерации текста. Я начну новую серию, чтобы шаг за шагом объяснить глубокое обучение. Если у вас есть какие-либо пожелания или темы, которые вы хотели бы увидеть, не стесняйтесь связаться со мной.
Еще раз спасибо всем, кто следил за этой серией, оставлял отзывы и поддерживал ее, особенно команде Towards Data Science.
Счастливого Рождества 🎄
Источник: towardsdatascience.com

























