
От случайных ансамблей к оптимизации: объяснение градиентного бустинга.
Делиться

В предыдущей статье мы представили ансамблевое обучение с использованием методов голосования, бэггинга и случайного леса.
Само по себе голосование — это лишь механизм агрегирования. Оно не создает разнообразия, а объединяет прогнозы, полученные с помощью уже различных моделей.
В свою очередь, метод бэггинга явно создает разнообразие за счет обучения одной и той же базовой модели на нескольких бутстрапированных версиях обучающего набора данных.
Алгоритм Random Forest расширяет возможности метода бэггинга, дополнительно ограничивая набор признаков, рассматриваемых при каждом разбиении.
С точки зрения статистики, идея проста и интуитивно понятна: разнообразие создается за счет случайности, без введения каких-либо принципиально новых концепций моделирования.
Но на этом обучение в ансамбле не заканчивается.
Существует ещё одно семейство ансамблевых методов, которое вообще не опирается на случайность, а на оптимизацию . К этому семейству относится градиентный бустинг. И чтобы по-настоящему его понять, начнём с намеренно необычной идеи:
Мы применим градиентный бустинг к линейной регрессии.
Да, я знаю. Вероятно, вы впервые слышите о применении градиентного бустинга в линейной регрессии.
(Завтра мы рассмотрим градиентные бустинговые деревья решений).
В этой статье изложен план:
- Для начала мы вернемся к трем фундаментальным этапам машинного обучения.
- Затем мы представим алгоритм градиентного бустинга.
- Далее мы применим градиентный бустинг к линейной регрессии.
- В заключение мы рассмотрим взаимосвязь между градиентным бустингом и градиентным спуском.
1. Машинное обучение в три этапа
Чтобы упростить изучение машинного обучения, я всегда разделяю его на три четких этапа. Давайте применим эту структуру к градиентному бустингу линейной регрессии.
Потому что, в отличие от упаковки, каждый шаг открывает что-то интересное.

1. Модель
Модель — это нечто, что принимает на вход признаки и выдает на выходе прогноз.
В данной статье в качестве базовой модели будет использоваться линейная регрессия .
1 бис. Модель ансамблевого метода
Градиентный бустинг сам по себе не является моделью. Это ансамблевый метод, который объединяет несколько базовых моделей в единую метамодель. Сам по себе он не сопоставляет входные данные с выходными. Его необходимо применять к базовой модели.
В данном случае для агрегирования моделей линейной регрессии будет использоваться градиентный бустинг.
2. Подгонка модели
Каждую базовую модель необходимо подогнать под обучающие данные.
В линейной регрессии подгонка означает оценку коэффициентов. Это можно сделать численно с помощью градиентного спуска, а также аналитически. В Google Sheets или Excel мы можем напрямую использовать функцию LINEST для оценки этих коэффициентов.
2 бис. Ансамблевое обучение моделей.
На первый взгляд, градиентный бустинг может показаться простым объединением моделей. Но это всё же процесс обучения. Как мы увидим, он основан на функции потерь, точно так же, как и классические модели, которые обучаются весам.
3. Настройка модели
Настройка модели заключается в оптимизации гиперпараметров.
В нашем случае базовая модель линейной регрессии сама по себе не имеет гиперпараметров (если только мы не используем регуляризованные варианты, такие как Ridge или Lasso).
Однако градиентный бустинг вводит два важных гиперпараметра: количество шагов бустинга и скорость обучения. Мы рассмотрим это в следующем разделе.
В двух словах, это машинное обучение, упрощенное до трех шагов!
2. Алгоритм градиентного бустинга с регрессором
2.1 Принцип работы алгоритма
Вот основные этапы алгоритма градиентного бустинга, применяемого к регрессии.
- Инициализация : Мы начинаем с очень простой модели. Для регрессии это обычно среднее значение целевой переменной.
- Расчет остаточных ошибок : Мы вычисляем остатки, определяемые как разница между фактическими значениями и текущими прогнозами.
- Применение линейной регрессии к остаткам : Мы применяем новую базовую модель (в данном случае, линейную регрессию) к этим остаткам.
- Обновление ансамбля : Мы добавляем эту новую модель в ансамбль, масштабированную с помощью скорости обучения (также называемой сжатием).
- Повторение процесса : Мы повторяем шаги со 2 по 4 до тех пор, пока не достигнем желаемого числа итераций бустинга или пока ошибка не сойдется.
Вот и всё! Это базовая процедура выполнения градиентного бустинга, применяемого к линейной регрессии.
2.2 Алгоритм, выраженный формулами
Теперь мы можем записать формулы в явном виде, это помогает сделать каждый шаг более наглядным.
Шаг 1 – Инициализация
Мы начинаем с постоянной модели, равной среднему значению целевой переменной:
f0 = average(y)
Шаг 2 – Вычисление остатка
Мы вычисляем остатки, определяемые как разница между фактическими значениями и текущими прогнозами:
r1 = y − f0
Шаг 3 – Подгонка базовой модели к остаткам.
Мы построили модель линейной регрессии для этих остатков:
r̂1 = a0 · x + b0
Шаг 4 – Обновление ансамбля
Мы обновляем модель, добавляя подобранную регрессию, масштабированную с учетом скорости обучения:
f1 = f0 − learning_rate · (a0 · x + b0)
Следующая итерация
Мы повторяем ту же процедуру:
r2 = y − f1
r̂2 = a1 · x + b1
f2 = f1 − learning_rate · (a1 · x + b1)
Раскрыв это выражение, получаем:
f2 = f0 − learning_rate · (a0 · x + b0) − learning_rate · (a1 · x + b1)
Тот же процесс повторяется на каждой итерации. Остатки пересчитываются, строится новая модель, и ансамбль обновляется путем добавления этой модели с заданным темпом обучения.
Эта формулировка ясно показывает, что градиентный бустинг строит итоговую модель как сумму последовательных корректирующих моделей.
3. Линейная регрессия с градиентным бустингом
3.1 Обучение базовой модели
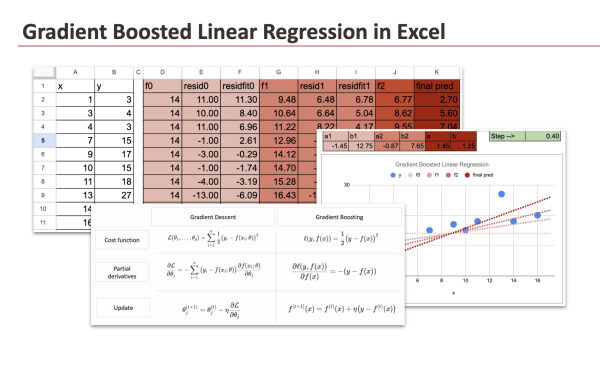
В качестве базовой модели мы используем простую линейную регрессию, опираясь на небольшой набор данных из десяти наблюдений, который я сгенерировал.
Для построения базовой модели мы будем использовать функцию LINEST из Google Таблиц (она также работает в Excel) для оценки коэффициентов линейной регрессии.

3.2 Алгоритм градиентного бустинга
Реализация этих формул не представляет сложности в Google Таблицах или Excel.
В таблице ниже представлен обучающий набор данных, а также различные этапы градиентного бустинга:

Для каждого этапа подгонки мы используем функцию LINEST в Excel:

Мы выполним только 2 итерации, а результаты последующих итераций можно предположить. Ниже представлен график, иллюстрирующий модели на каждой итерации. Различные оттенки красного цвета показывают сходимость модели, а также окончательную модель, полученную непосредственно с помощью градиентного спуска, примененного к переменной y.

3.3 Почему бустинг линейной регрессии носит исключительно педагогический характер
Если внимательно изучить алгоритм, то можно сделать два важных наблюдения.
Во-первых, на шаге 2 мы строим линейную регрессию по остаткам. Это потребует времени и алгоритмических шагов для выполнения этапов подгонки модели. Вместо того чтобы строить линейную регрессию по остаткам, мы можем напрямую построить линейную регрессию по фактическим значениям y, и уже тогда найдем оптимальную модель!
Во-вторых, при добавлении одной линейной регрессии к другой линейной регрессии, она по-прежнему остается линейной регрессией.
Например, мы можем переписать f2 следующим образом:
f2 = f0 — скорость обучения *(b0+b1) — скорость обучения * (a0+a1) x
Это по-прежнему линейная функция от x.
Это объясняет, почему градиентный бустинг-линейная регрессия не приносит никакой практической пользы. Его ценность носит чисто педагогический характер: он помогает нам понять, как работает алгоритм градиентного бустинга, но не улучшает точность прогнозирования.
На самом деле, этот метод даже менее полезен, чем метод бэггинга, применяемый к линейной регрессии. При использовании бэггинга изменчивость между бутстрапированными моделями позволяет оценить неопределенность прогноза и построить доверительные интервалы. Градиентный бустинг линейной регрессии, напротив, сводится к одной линейной модели и не предоставляет дополнительной информации о неопределенности.
Как мы увидим завтра, ситуация совершенно иная, когда базовой моделью является дерево решений.
3.4 Настройка гиперпараметров
Мы можем настроить два гиперпараметра: количество итераций и скорость обучения.
Что касается количества итераций, мы реализовали только две, но легко представить себе и большее число, и мы можем остановиться на рассмотрении величины остатков.
Что касается скорости обучения, мы можем изменить её в Google Таблице и посмотреть, что произойдёт. Когда скорость обучения мала, «процесс обучения» будет медленным. А если скорость обучения равна 1, мы увидим, что сходимость достигается на первой итерации.

А остатки первой итерации уже равны нулю.

Если скорость обучения превышает 1, то модель начнет расходиться.

4. Повышенная сложность как градиентный спуск в функциональном пространстве
4.1 Сравнение с алгоритмом градиентного спуска
На первый взгляд, роль скорости обучения и количества итераций в градиентном бустинге очень похожа на то, что мы видим в градиентном спуске. Это, естественно, приводит к путанице.
- Новички часто замечают, что оба алгоритма содержат слово «градиент» и следуют итеративной процедуре. Поэтому возникает соблазн предположить, что градиентный спуск и градиентный бустинг тесно связаны, не понимая при этом, почему.
- Опытные специалисты обычно реагируют иначе. С их точки зрения, эти два метода кажутся несвязанными. Градиентный спуск используется для подгонки моделей на основе весов путем оптимизации их параметров, в то время как градиентный бустинг — это ансамблевый метод, который объединяет несколько моделей, построенных с использованием остатков. Варианты применения, реализации и интуитивное понимание кажутся совершенно разными.
- Однако, если копнуть глубже , эксперты скажут, что эти два алгоритма, по сути, основаны на одной и той же идее оптимизации. Разница заключается не в правиле обучения, а в пространстве, где это правило применяется. Или, другими словами, переменная, представляющая интерес, различна.
Метод градиентного спуска выполняет обновления на основе градиента в пространстве параметров . Метод градиентного бустинга выполняет обновления на основе градиента в пространстве функций .
Это единственное различие в данной математической численной оптимизации. Рассмотрим уравнения в случае регрессии и в общем случае ниже.
4.2 Случай среднеквадратичной ошибки: тот же алгоритм, но разное пространство.
При использовании среднеквадратичной ошибки градиентный спуск и градиентный бустинг минимизируют одну и ту же целевую функцию и управляются одной и той же величиной: остатком.
В градиентном спуске остатки влияют на обновление параметров модели.
В градиентном бустинге остатки напрямую обновляют функцию прогнозирования.
В обоих случаях скорость обучения и количество итераций играют одинаковую роль. Разница заключается лишь в том, где применяется обновление: в пространстве параметров или в пространстве функций.
Как только это различие становится ясным, становится очевидно, что градиентный бустинг с MSE — это просто градиентный спуск, выраженный на уровне функций.

4.3 Градиентный бустинг с любой функцией потерь
Приведенное выше сравнение не ограничивается среднеквадратичной ошибкой. И градиентный спуск, и градиентный бустинг могут быть определены относительно различных функций потерь.
В градиентном спуске функция потерь определяется в пространстве параметров. Это требует, чтобы модель была дифференцируема по своим параметрам, что, естественно, ограничивает применение метода моделями, основанными на весах.
В градиентном бустинге функция потерь определяется в пространстве предсказаний. Только функция потерь должна быть дифференцируемой относительно предсказаний. Сама базовая модель не обязательно должна быть дифференцируемой и, конечно же, не обязательно должна иметь собственную функцию потерь.
Это объясняет, почему градиентный бустинг может комбинировать произвольные функции потерь с моделями, не основанными на весах, такими как деревья решений.

Заключение
Градиентный бустинг — это не просто наивный ансамблевый метод, а алгоритм оптимизации. Он следует той же логике обучения, что и градиентный спуск, отличаясь лишь пространством, в котором выполняется оптимизация: параметры против функций. Использование линейной регрессии позволило нам выделить этот механизм в его простейшей форме.
В следующей статье мы увидим, как эта структура становится по-настоящему мощной, когда базовой моделью является дерево решений, что приводит к использованию регрессоров на основе градиентного бустинга деревьев решений.
Примечание о порядке обучения
Метод градиентного бустинга часто представляется как наиболее мощный ансамблевый метод, и он действительно очень популярен на практике.
Однако понимание ансамблевого обучения начинается не с бустинга.
Метод бэггинга остается более простым и фундаментальным подходом, особенно с точки зрения статистики.
Это позволяет явно оценить снижение дисперсии и предоставляет полезную информацию о неопределенности прогнозирования, что дополняет оптимизационный подход градиентного бустинга.
Источник: towardsdatascience.com

























