Понимание принципов ансамблевого обучения в Excel на основе базовых принципов
Делиться

В течение 18 дней мы изучали большинство основных моделей машинного обучения, сгруппированных в три основные группы: модели, основанные на расстоянии и плотности, модели, основанные на деревьях или правилах, и модели, основанные на весах.
До этого момента каждая статья была посвящена одной модели, обученной самостоятельно. Ансамблевое обучение полностью меняет эту перспективу. Это не автономная модель. Вместо этого, это способ объединения этих базовых моделей для создания чего-то нового.
Как показано на диаграмме ниже, ансамбль представляет собой метамодель . Он строится поверх отдельных моделей и объединяет их прогнозы.

Голосование: простейшая ансамблевая идея
Простейшая форма ансамблевого обучения — это голосование .
Идея практически тривиальна: обучить несколько моделей, взять их прогнозы и вычислить среднее значение. Если одна модель ошибается в одном направлении, а другая — в противоположном, ошибки должны компенсировать друг друга. По крайней мере, такова интуиция.
На бумаге это звучит разумно. На практике же все обстоит совсем иначе.
Как только вы попробуете проголосовать за реальные модели, станет очевидным один факт: голосование — это не волшебство . Простое усреднение прогнозов не гарантирует улучшения результатов. Во многих случаях это, наоборот, ухудшает ситуацию.
Причина проста. Когда вы объединяете модели, которые ведут себя совершенно по-разному, вы также объединяете их слабые стороны. Если модели не допускают взаимодополняющих ошибок, усреднение может ослабить полезную структуру, а не усилить ее.
Чтобы это стало нагляднее, рассмотрим очень простой пример. Возьмем дерево решений и линейную регрессию, обученные на одном и том же наборе данных. Дерево решений улавливает локальные, нелинейные закономерности. Линейная регрессия улавливает глобальный линейный тренд. При усреднении их прогнозов вы не получаете лучшую модель. Вы получаете компромисс, который часто оказывается хуже, чем каждая модель, взятая по отдельности.

Это иллюстрирует важный момент: ансамблевое обучение требует большего, чем просто усреднение . Оно требует стратегии. Способа объединения моделей, который действительно повышает стабильность или обобщающую способность.
Более того, если рассматривать ансамбль как единую модель, то его необходимо обучать именно так. Простое усреднение не предоставляет параметров для настройки. Здесь нечего изучать, нечего оптимизировать.
Одним из возможных улучшений системы голосования является присвоение моделям разных весов. Вместо того чтобы придавать каждой модели одинаковую важность, мы могли бы попытаться определить, какие из них должны иметь большее значение. Но как только мы вводим веса, возникает новый вопрос: как их обучать? В этот момент сам ансамбль становится моделью, которую необходимо подогнать под свои параметры.
Это наблюдение естественным образом приводит к разработке более структурированных ансамблевых методов.
В этой статье мы начнем с одного статистического подхода к перевыборке обучающего набора данных перед усреднением: бэггинг .
Суть концепции Bagging
Почему «упаковка»?
Что такое упаковка в пакеты?
Ответ, по сути, скрыт в самом названии.
Бэггинг = Бутстрап + Агрегирование .
Сразу видно, что это название придумал математик или статистик. 🙂
За этим несколько пугающим словом скрывается предельно простая идея. Бэггинг — это выполнение двух задач: во-первых, создание множества версий набора данных с использованием бутстрапа, и во-вторых, агрегирование результатов, полученных из этих наборов данных.
Таким образом, основная идея заключается не в изменении модели, а в изменении данных .
Бутстреп-анализ набора данных
Метод бутстрапа подразумевает выборку данных с замещением . Каждая бутстрап-выборка имеет тот же размер, что и исходный набор данных, но не те же самые наблюдения. Некоторые строки встречаются несколько раз, другие исчезают.
В Excel это очень легко реализовать и, что более важно, очень легко увидеть.
Для начала добавьте в свой набор данных столбец ID, по одному уникальному идентификатору на каждую строку. Затем, используя функцию RANDBETWEEN, случайным образом выбирайте индексы строк. Каждый выбор соответствует одной строке в выборке бутстрапа. Повторяя этот процесс, вы создадите полный набор данных, который будет выглядеть знакомо, но немного отличаться от исходного.
Уже один этот шаг делает идею упаковки в пакеты конкретной. Вы можете буквально увидеть дубликаты. Вы можете увидеть, каких наблюдений не хватает. Ничто не является абстрактным.
Ниже вы можете увидеть примеры бутстрап-выборок, сгенерированных на основе одного и того же исходного набора данных. Каждая выборка рассказывает немного отличающуюся историю, хотя все они получены из одних и тех же данных.
Эти альтернативные наборы данных являются основой метода бэггинга.

Метод агрегирования линейных регрессий: понимание принципа
Процесс упаковки в пакеты
Да, вероятно, вы впервые слышите о линейной регрессии с использованием метода бэггинга .
Теоретически, в этом нет ничего плохого. Как мы уже говорили, бэггинг — это ансамблевый метод, который можно применять к любой базовой модели . Линейная регрессия — это модель, поэтому технически она подходит под это определение.
Однако на практике вы быстро убедитесь, что это не очень полезно.
Но ничто не мешает нам это сделать. И именно потому, что это не очень полезно, это отличный пример для обучения. Так давайте же это сделаем.
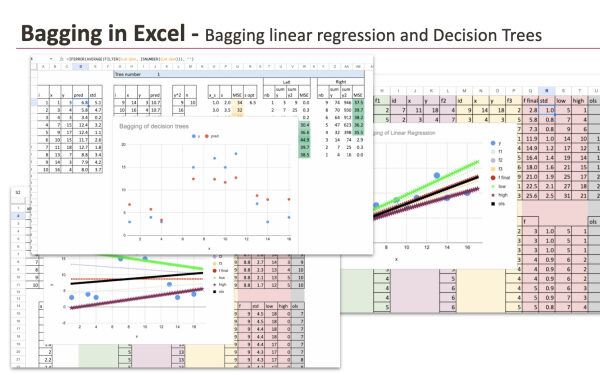
Для каждой бутстрап-выборки мы строим линейную регрессию. В Excel это сделать очень просто. Мы можем напрямую использовать функцию LINEST для оценки коэффициентов. Каждый цвет на графике соответствует одной бутстрап-выборке и соответствующей ей линии регрессии.
Пока что всё идёт точно так, как ожидалось. Линии близки друг к другу, но не идентичны. Каждая выборка методом бутстрапа немного изменяет коэффициенты, а следовательно, и аппроксимирующую линию.

Теперь перейдём к ключевому наблюдению.
Вы можете заметить, что на графике черным цветом показана еще одна модель. Она соответствует стандартной линейной регрессии, построенной на исходном наборе данных без бутстрапа.
Что произойдет, если сравнить это с моделями, упакованными в пакеты?
Когда мы усредняем прогнозы всех этих линейных регрессий, конечный результат по-прежнему остается линейной регрессией . Форма прогноза не меняется. Связь между переменными остается линейной. Мы не создали более выразительную модель.
И что еще более важно, модель, полученная методом агрегирования данных, оказывается очень близка к стандартной линейной регрессии, обученной на исходных данных.
Мы можем даже расширить этот пример, используя набор данных с явно нелинейной структурой. В этом случае каждая линейная регрессия, построенная на основе бутстрап-выборки, сталкивается со своими трудностями. Некоторые линии слегка наклоняются вверх, другие — вниз, в зависимости от того, какие наблюдения были продублированы или отсутствовали в выборке.

Доверительные интервалы, рассчитанные методом бутстрапа.
С точки зрения точности прогнозирования, линейная регрессия с использованием метода бэггинга не очень полезна.
Однако метод бутстреппинга остается чрезвычайно полезным для одного важного статистического понятия : оценки доверительного интервала прогнозов .
Вместо того чтобы рассматривать только среднее значение прогноза, мы можем посмотреть на распределение прогнозов, полученных всеми моделями, построенными методом бутстрапа. Для каждого входного значения у нас теперь есть множество прогнозируемых значений, по одному из каждой выборки бутстрапа.
Простой и интуитивно понятный способ количественной оценки неопределенности — вычислить стандартное отклонение этих прогнозов . Это стандартное отклонение показывает, насколько чувствителен прогноз к изменениям данных. Малое значение означает, что прогноз стабилен. Большое значение означает, что он неопределен.
Этот подход отлично работает в Excel. После того, как вы получили все прогнозы из бутстрапированных моделей, вычисление их стандартного отклонения не представляет сложности. Результат можно интерпретировать как доверительный интервал вокруг прогноза.
Это наглядно видно на графике ниже. Интерпретация проста: в областях, где обучающие данные разрежены или сильно рассеяны, доверительный интервал становится широким, поскольку прогнозы значительно различаются в разных выборках, полученных методом бутстрапа.
И наоборот, там, где данные плотные, прогнозы более стабильны, а доверительный интервал сужается.

Теперь, когда мы применяем это к нелинейным данным, становится совершенно ясно одно. В областях, где линейная модель с трудом соответствует данным, прогнозы, полученные на основе различных бутстрап-выборок, значительно разбросаны. Доверительный интервал становится шире.
Это важное наблюдение. Даже если метод бэггинга не повышает точность прогнозирования, он предоставляет ценную информацию о неопределенности . Он показывает, где модель надежна, а где нет.
Наблюдение за тем, как эти доверительные интервалы формируются непосредственно из бутстрап-выборок в Excel, делает эту статистическую концепцию очень наглядной и интуитивно понятной.

Использование метода бэггинга для построения деревьев решений: от слабых алгоритмов обучения к сильной модели.
Теперь перейдём к деревьям решений.
Принцип бэггинга остается неизменным. Мы генерируем несколько бутстрап-выборок, обучаем одну модель на каждой из них, а затем объединяем их прогнозы.
Я улучшил реализацию в Excel, чтобы сделать процесс разделения более автоматизированным. Для удобства работы в Excel мы ограничиваем деревья одним разделением. Построение более глубоких деревьев возможно, но в электронной таблице это быстро становится громоздким.
Ниже вы можете увидеть два дерева, построенных методом бутстрапа. В общей сложности я построил восемь таких деревьев, просто скопировав и вставив формулы, что делает процесс простым и легким для воспроизведения.

Поскольку деревья решений представляют собой сильно нелинейные модели, а их прогнозы являются кусочно-постоянными, усреднение их результатов оказывает сглаживающий эффект.
В результате метод бэггинга естественным образом сглаживает прогнозы. Вместо резких скачков, создаваемых отдельными деревьями, агрегированная модель обеспечивает более плавные переходы.
В Excel этот эффект очень легко наблюдать. Сгенерированные с помощью агрегирования прогнозы явно более сглажены, чем прогнозы, полученные с помощью любого отдельного дерева.

Некоторые из вас, возможно, уже слышали о деревьях решений с максимальной глубиной, равной единице. Именно их мы здесь и используем. Каждая такая модель предельно проста. Сама по себе такая модель является слабым обучающимся алгоритмом.
Вопрос здесь следующий:
Достаточно ли набора нерешительных аргументов в сочетании с методом «бэггинга»?
Мы вернемся к этому позже в моем «Рождественском календаре» по машинному обучению.
Случайный лес: расширение метода бэггинга
А что насчет алгоритма Random Forest?
Это, пожалуй, одна из самых популярных моделей среди специалистов по анализу данных.
Так почему бы не обсудить это здесь, даже в Excel?
По сути, то, что мы только что создали, уже очень близко к случайному лесу!
Чтобы понять почему, вспомним, что алгоритм Random Forest вводит два источника случайности .
- Первый этап — это бутстрап-анализ набора данных. Это в точности то, что мы уже сделали с помощью бэггинга.
- Второй фактор — случайность в процессе разделения. При каждом разделении рассматривается только случайное подмножество признаков.
В нашем случае, однако, у нас есть только один признак. Это означает, что выбирать нечего. Случайность признаков здесь просто не применима.
В результате, полученный результат можно рассматривать как упрощенный вариант алгоритма случайного леса.
Как только эта концепция станет понятной, распространение этой идеи на множество функций станет лишь дополнительным слоем случайности, а не новой концепцией.
И вы можете даже спросить, можно ли применить этот принцип к линейной регрессии и провести случайную выборку.
Заключение
Ансамблевое обучение меньше связано со сложными моделями и больше — с управлением нестабильностью.
Простое голосование редко бывает эффективным. Метод линейной регрессии с использованием бэггинга мало что меняет и остается в основном педагогическим, хотя и полезен для оценки неопределенности. Однако в случае с деревьями решений бэггинг действительно имеет значение: усреднение нестабильных моделей приводит к более плавным и надежным прогнозам.
Алгоритм случайного леса естественным образом расширяет эту идею, добавляя дополнительную случайность, не меняя при этом основной принцип. В Excel ансамблевые методы перестают быть «черными ящиками» и становятся логичным следующим шагом.
Дополнительная литература
Спасибо за вашу поддержку моего «Рождественского календаря» по машинному обучению.
Обычно много говорят об обучении с учителем, но обучение без учителя иногда упускается из виду, хотя оно может выявить структуру, которую невозможно показать никаким обозначением.
Если вы хотите подробнее изучить эти идеи, вот три статьи, посвященные мощным моделям обучения без учителя.
Модель гауссовой смеси
Улучшенная и более гибкая версия алгоритма k-средних.
В отличие от алгоритма k-средних, алгоритм GMM позволяет кластерам растягиваться, вращаться и адаптироваться к истинной форме данных.
Но когда алгоритмы k-средних и GMM действительно дают разные результаты?
Ознакомьтесь с этой статьей, чтобы увидеть конкретные примеры и наглядные сравнения.
Локальный фактор выбросов (LOF)
Умный метод, который сравнивает локальную плотность каждой точки с плотностью её соседей для обнаружения аномалий.
Источник: towardsdatascience.com