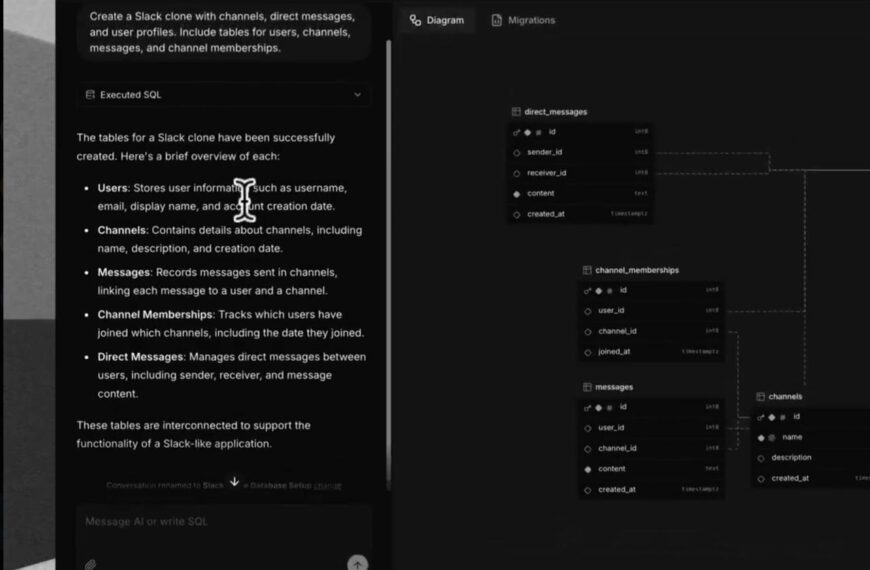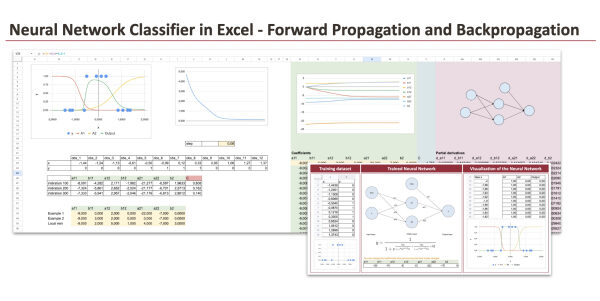
Понимание прямого и обратного распространения с помощью явных формул.
Делиться

После вчерашнего рассмотрения регрессора на основе нейронных сетей, мы переходим к версии классификатора .
С математической точки зрения, обе модели очень похожи. Фактически, они различаются главным образом интерпретацией выходных данных и выбором функции потерь.
Однако именно в этой версии классификатора интуиция обычно оказывается гораздо сильнее.
На практике нейронные сети гораздо чаще используются для классификации , чем для регрессии. Представление о роли нейронов и слоев в терминах вероятностей, границ принятия решений и классов упрощает понимание этого понятия.
В этой статье вы увидите:
- Как интуитивно определить структуру нейронной сети.
- почему количество нейронов имеет значение.
- и почему одного скрытого слоя уже достаточно , по крайней мере, в теории.
В этот момент возникает закономерный вопрос:
Если достаточно одного скрытого слоя, зачем тогда так много говорить о глубоком обучении?
Ответ важен.
Глубокое обучение — это не просто наложение множества скрытых слоев друг на друга. Глубина помогает, но это не вся история. Действительно важно то, как строятся, используются и ограничиваются представления, и почему более глубокие архитектуры эффективнее для обучения и обобщения на практике.
Мы вернемся к этому различию позже. А пока мы намеренно оставляем сеть небольшой, чтобы каждое вычисление можно было понять, записать и проверить вручную.
Это лучший способ по-настоящему понять, как работает классификатор на основе нейронной сети.
Как и в случае с созданным нами вчера регрессором на основе нейронной сети, мы разделим работу на две части .
Сначала рассмотрим прямое распространение и определим нейронную сеть как фиксированную математическую функцию, которая сопоставляет входные данные с прогнозируемыми вероятностями.
Затем мы переходим к обратному распространению ошибки , где обучаем эту функцию, минимизируя логарифмическую функцию потерь с помощью градиентного спуска.
Принципы остались точно такими же, как и прежде. Изменилась только интерпретация выходных данных и функция потерь.
1. Прямое распространение
В этом разделе мы сосредоточимся только на одном: самой модели . Обучение пока не проводится. Только функция.
1.1 Простой набор данных и интуитивное понимание построения функции
Начнём с очень небольшого набора данных:
- 12 наблюдений
- Одна единственная функция x
- Бинарная целевая переменная y
Набор данных намеренно упрощен, чтобы каждое вычисление можно было выполнить вручную. Однако он обладает одним важным свойством: классы не являются линейно разделимыми .
Это означает, что простая логистическая регрессия не сможет решить эту проблему, независимо от того, насколько хорошо она обучена.

Однако интуитивное предположение прямо противоположно тому, что может показаться на первый взгляд.
Сначала мы построим две логистические регрессии . Каждая из них создаст разрез во входном пространстве, как показано ниже.
Иными словами, мы начинаем с одной единственной характеристики и преобразуем её в две новые характеристики .

Затем мы применяем еще одну логистическую регрессию , на этот раз к этим двум признакам, чтобы получить окончательную вероятность результата.
Если записать функцию в виде единого математического выражения, она уже будет несколько сложной для чтения. Именно поэтому мы используем диаграмму: не потому, что диаграмма точнее, а потому, что так проще понять, как функция строится путем композиции .

1.2 Структура нейронной сети
Таким образом, визуальная диаграмма представляет следующую модель:
- Один скрытый слой с двумя нейронами, что позволяет нам представить два фрагмента данных, которые мы наблюдаем в наборе данных.
- Один выходной нейрон, и здесь используется логистическая регрессия.

В нашем случае модель зависит от семи коэффициентов :
- Веса и смещения для двух скрытых нейронов
- Веса и смещения для выходного нейрона
Взятые вместе, эти семь чисел полностью определяют модель.
Если вы уже понимаете, как работает классификатор на основе нейронной сети, вот вам вопрос:
Сколько различных решений может иметь эта модель?
Иными словами, сколько различных наборов из семи коэффициентов могут дать одну и ту же границу классификации или почти одинаковые прогнозируемые вероятности на этом наборе данных?
1.3 Реализация алгоритма прямого распространения в Excel
Теперь мы реализуем модель, используя формулы Excel.
Для визуализации выходных данных нейронной сети мы генерируем новые значения x в диапазоне от −2 до 2 с шагом 0,02.
Для каждого значения x мы вычисляем:
- Выходные сигналы двух скрытых нейронов (A1 и A2)
- Конечный результат работы сети
На данном этапе модель еще не обучена. Поэтому нам необходимо зафиксировать семь параметров сети. Пока что мы просто используем набор разумных значений, показанных ниже, что позволяет нам визуализировать распространение модели вперед.
Это лишь одна из возможных конфигураций параметров. Еще до начала обучения возникает интересный вопрос: сколько различных конфигураций параметров могут дать допустимое решение этой задачи?

Для вычисления значений скрытых слоев и выходных данных можно использовать следующие уравнения.

Промежуточные значения A1 и A2 отображаются явно. Это позволяет избежать сложных, нечитаемых формул и упрощает отслеживание распространения ошибки.

С помощью нейронной сети удалось успешно разделить набор данных на два отдельных класса.

1.4 Прямое распространение: краткое изложение и наблюдения
Подводя итог, мы начали с простого обучающего набора данных и определили нейронную сеть как явную математическую функцию, реализованную с помощью простых формул Excel и фиксированного набора коэффициентов. Подавая новые значения xxx в эту функцию, мы смогли визуализировать выходные данные нейронной сети и наблюдать, как она разделяет данные.

Теперь, если внимательно посмотреть на формы, полученные из скрытого слоя, содержащего две логистические регрессии, можно увидеть, что существует четыре возможных конфигурации . Они соответствуют различным возможным ориентациям наклонов двух логистических функций.
Каждый скрытый нейрон может иметь либо положительный, либо отрицательный наклон. При наличии двух нейронов это приводит к 2×2=4 возможным комбинациям. Эти различные конфигурации могут приводить к очень похожим границам принятия решений на выходе, даже несмотря на то, что базовые параметры различны.
Это объясняет, почему модель может допускать несколько решений для одной и той же задачи классификации.

Самая сложная задача сейчас — определить значения этих коэффициентов.
Вот тут-то и вступает в игру обратное распространение ошибки .
2. Обратное распространение ошибки: обучение нейронной сети с помощью градиентного спуска.
После определения модели обучение становится численной задачей.
Несмотря на своё название, обратное распространение ошибки не является отдельным алгоритмом. Это просто градиентный спуск, применённый к составной функции .
2.1 Напоминание об алгоритме обратного распространения ошибки
Принцип одинаков для всех моделей, основанных на весе .
Сначала мы определяем модель, то есть математическую функцию, которая отображает входные данные на выходные.
Затем мы определяем функцию потерь. Поскольку это задача бинарной классификации, мы используем логарифмическую функцию потерь , точно так же, как и в логистической регрессии.
Наконец, для обучения коэффициентов мы вычисляем частные производные функции потерь по каждому коэффициенту модели. Именно эти производные позволяют нам обновлять параметры с помощью градиентного спуска.
Ниже приведён скриншот, демонстрирующий окончательные формулы для этих частных производных.

Алгоритм обратного распространения ошибки можно кратко описать следующим образом:
- Инициализируйте веса нейронной сети случайным образом.
- Передайте входные данные через нейронную сеть, чтобы получить прогнозируемый выходной результат.
- Рассчитайте погрешность между прогнозируемым и фактическим результатом.
- Для вычисления градиента функции потерь относительно весов необходимо выполнить обратное распространение ошибки по сети.
- Обновите веса, используя вычисленный градиент и скорость обучения.
- Повторяйте шаги со 2 по 5 до тех пор, пока модель не сойдется.
2.2 Инициализация коэффициентов
Набор данных организован по столбцам, что упрощает расширение формул Excel.

Здесь коэффициенты инициализируются определенными значениями. Вы можете изменить их, но сходимость не гарантируется. В зависимости от инициализации градиентный спуск может сходиться к другому решению, сходиться очень медленно или вовсе не сходиться.

2.3 Прямое распространение
В столбцах от AG до BP мы реализуем этап прямого распространения. Сначала мы вычисляем две скрытые активации A1 и A2 , а затем выходные данные сети. Это те же самые формулы, которые использовались ранее для определения прямого распространения модели.
Для обеспечения читаемости вычислений мы обрабатываем каждое наблюдение отдельно . В результате у нас получается 12 столбцов для выходных данных скрытого слоя (A1 и A2) и 12 столбцов для выходного слоя.
Вместо того чтобы писать единую формулу суммирования, мы вычисляем значения для каждого наблюдения отдельно. Это позволяет избежать очень больших и трудночитаемых формул и делает логику вычислений гораздо понятнее.
Такая организация по столбцам также упрощает имитацию цикла for во время градиентного спуска: формулы можно просто расширять по строкам для представления последовательных итераций.

2.4 Ошибки и функция стоимости
В столбцах от BQ до CN мы вычисляем погрешности и значения функции стоимости.
Для каждого наблюдения мы оцениваем логарифмическую функцию потерь на основе прогнозируемого результата и истинной метки. Затем эти отдельные функции потерь объединяются для получения общей стоимости для каждой итерации.

2.5 Частные производные
Теперь перейдём к вычислению частных производных.
Нейронная сеть имеет 7 коэффициентов , поэтому нам необходимо вычислить 7 частных производных , по одной для каждого параметра. Для каждой производной вычисление выполняется для всех 12 наблюдений , что в сумме дает 84 промежуточных значения .
Для удобства работы таблица тщательно структурирована. Столбцы сгруппированы и выделены разными цветами, что позволяет легко отслеживать каждую производную.
В столбцах от CO до DL мы вычисляем частные производные, связанные с a11 и a12 .

В столбцах от DM до EJ мы вычисляем частные производные, связанные с b11 и b12 .

В столбцах от EK до FH мы вычисляем частные производные, связанные с a21 и a22 .

В столбцах от FI до FT мы вычисляем частные производные, связанные с b2 .

В завершение мы суммируем частные производные по 12 наблюдениям.
Полученные градиенты сгруппированы и показаны в столбцах от Z до FI .

2.6 Обновление весов в цикле for
Эти частные производные позволяют нам выполнять градиентный спуск для каждого коэффициента. Обновления вычисляются в столбцах от R до X.
На каждой итерации мы можем наблюдать за изменением коэффициентов. Значение функции стоимости показано в столбце Y , что позволяет легко увидеть, работает ли алгоритм спуска и уменьшается ли значение функции потерь.

После обновления коэффициентов на каждом шаге цикла for мы пересчитываем выходные данные нейронной сети.

Если начальные значения коэффициентов выбраны неудачно, алгоритм может не сойтись или сойтись к нежелательному решению, даже при разумном шаге.

Приведённый ниже GIF-файл показывает выходные данные нейронной сети на каждой итерации цикла for. Он помогает визуализировать, как модель развивается в процессе обучения и как граница принятия решений постепенно сходится к решению.

Заключение
Мы завершили полную реализацию классификатора на основе нейронной сети, от прямого распространения до обратного распространения, используя только явные формулы.
Пошагово построив все компоненты, мы убедились, что нейронная сеть — это не что иное, как математическая функция, обучаемая методом градиентного спуска. Прямое распространение ошибки определяет, что именно вычисляет модель. Обратное распространение ошибки показывает, как скорректировать коэффициенты для уменьшения функции потерь.
Этот файл позволяет свободно экспериментировать: вы можете изменять набор данных, модифицировать начальные значения коэффициентов и наблюдать за поведением обучения. В зависимости от инициализации модель может быстро сходиться, сходиться к другому решению или застревать в локальном минимуме.
Благодаря этому упражнению механика нейронных сетей становится понятной. Как только эти основы становятся ясными, использование высокоуровневых библиотек кажется гораздо менее сложным, потому что вы точно знаете, что происходит за кулисами.
Источник: towardsdatascience.com