Создание регрессора нейронной сети с обратным распространением ошибки в Excel
Делиться

Нейронные сети часто представляют в виде «черных ящиков».
Слои, активации, градиенты, обратное распространение ошибки… это может показаться сложным, особенно когда всё скрыто за функцией model.fit().
Мы создадим с нуля регрессор на основе нейронной сети, используя Excel . Все вычисления будут явными. Все промежуточные значения будут видны. Ничего не будет скрыто.
К концу этой статьи вы поймете, как нейронная сеть выполняет регрессию, как работает прямое распространение ошибки и как модель может аппроксимировать нелинейные функции, используя всего несколько параметров.
Прежде чем начать, если вы еще не читали мои предыдущие статьи, вам следует сначала ознакомиться с реализацией линейной регрессии и логистической регрессии.
Вы увидите, что нейронная сеть — это не новый объект. Это естественное расширение этих моделей.
Как обычно, мы будем следовать этим шагам:
- Сначала рассмотрим, как работает модель регрессора нейронной сети. В случае нейронных сетей этот шаг называется прямым распространением.
- Затем мы обучим эту функцию с помощью градиентного спуска. Этот процесс называется обратным распространением ошибки.
1. Прямое распространение
В этой части мы определим нашу модель, а затем реализуем её в Excel, чтобы посмотреть, как работает прогнозирование.
1.1 Простой набор данных
Мы будем использовать очень простой набор данных, который я сгенерировал. Он состоит всего из 12 наблюдений и одного признака.
Как видите, целевая переменная имеет нелинейную зависимость от x.
Для этого набора данных мы будем использовать два нейрона в скрытом слое.

1.2 Структура нейронной сети
В нашем примере нейронной сети есть:
- Один входной слой с признаком x в качестве входных данных.
- Один скрытый слой с двумя нейронами, и эти два нейрона позволят нам создать нелинейную зависимость.
- Выходной слой представляет собой просто линейную регрессию.
Вот диаграмма, представляющая эту нейронную сеть, вместе со всеми параметрами, которые необходимо оценить. Всего имеется 7 параметров.
Скрытый слой:
- a11: вес от x к скрытому нейрону 1
- b11: смещение скрытого нейрона 1
- a12: вес от x к скрытому нейрону 2
- b12: смещение скрытого нейрона 2
Выходной слой:
- a21: вес от скрытого нейрона 1 к выходу
- a22: вес от скрытого нейрона 2 к выходу
- b2: смещение выходного сигнала
По своей сути, нейронная сеть — это просто функция. Составная функция.
Если вы напишете это прямо, то в этом не будет ничего загадочного.

Обычно мы представляем эту функцию в виде диаграммы, состоящей из «нейронов».
На мой взгляд, наилучший способ интерпретации этой диаграммы — это визуальное представление составленной математической функции , а не утверждение о том, что она буквально воспроизводит работу биологических нейронов.

Зачем нужна эта функция?
Каждая сигмоида ведет себя как плавный шаг.
С помощью двух сигмоидных функций модель может увеличивать, уменьшать, изгибать и выравнивать кривую выходного сигнала.
Путем линейного комбинирования этих элементов сеть может аппроксимировать плавные нелинейные кривые.
Поэтому для этого набора данных двух нейронов уже достаточно . Но сможете ли вы найти набор данных, для которого такая структура не подходит?
1.3 Реализация функции в Excel
В этом разделе мы будем предполагать, что 7 коэффициентов уже найдены. И тогда мы сможем применить формулу, которую мы рассматривали ранее.
Для визуализации нейронной сети мы можем использовать новые непрерывные значения x в диапазоне от -2 до 2 с шагом 0,02.
Вот скриншот, и мы видим, что итоговая функция довольно хорошо соответствует форме входных данных.

2. Обратное распространение ошибки (градиентный спуск)
На данном этапе модель полностью определена.
Поскольку это задача регрессии, мы будем использовать среднеквадратичную ошибку (MSE), как и для линейной регрессии.
Теперь нам нужно найти 7 параметров, которые минимизируют среднеквадратичную ошибку (MSE).
2.1 Подробности алгоритма обратного распространения ошибки
Принцип прост. НО, поскольку существует множество составных функций и множество параметров, нам необходимо организовать работу с производными.
Я не буду явно выводить все 7 частных производных. Я просто приведу результаты.

Как видим, здесь присутствует ошибка. Поэтому для реализации всего процесса нам необходимо выполнить следующий цикл:
- инициализируйте веса,
- вычислить выходные данные (прямое распространение),
- вычислить ошибку,
- вычислить градиенты с помощью частных производных,
- обновите веса,
- Повторять до сходимости.
2.2 Инициализация
Начнём с того, что представим входной набор данных в столбцовом формате, что упростит внедрение формул в Excel.

Теоретически, мы можем начать с случайных значений для инициализации параметров. Но на практике количество итераций может быть большим для достижения полной сходимости. А поскольку функция стоимости не является выпуклой, мы можем застрять в локальном минимуме.
Поэтому нам нужно «мудро» выбрать начальные значения. Я подготовил для вас несколько вариантов. Вы можете внести небольшие изменения, чтобы посмотреть, что произойдет.

2.3 Прямое распространение
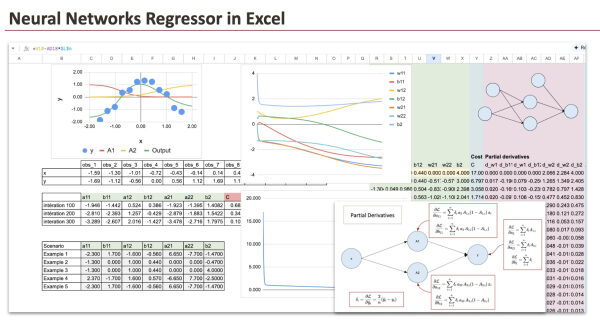
В столбцах от AG до BP мы выполняем фазу прямого распространения. Сначала вычисляем A1 и A2, а затем выходные данные. Это те же формулы, которые использовались в предыдущей части прямого распространения.
Для упрощения вычислений и повышения их управляемости мы выполняем расчеты для каждого наблюдения отдельно. Это означает, что у нас есть 12 столбцов для каждого скрытого слоя (A1 и A2) и выходного слоя. Вместо использования формулы суммирования мы вычисляем значения для каждого наблюдения индивидуально.
Для упрощения работы цикла for на этапе градиентного спуска мы организуем обучающий набор данных в столбцы, после чего можем расширять формулу в Excel по строкам.

2.4 Ошибки и функция стоимости
В столбцах от BQ до CN теперь можно вычислить значения функции стоимости.

2.5 Частные производные
Мы будем вычислять 7 частных производных, соответствующих весам нашей нейронной сети. Для каждой из этих частных производных нам потребуется вычислить значения для всех 12 наблюдений, что в итоге составит 84 столбца. Однако мы постарались упростить этот процесс, организовав таблицу с помощью цветовой кодировки и формул для удобства использования.

Итак, начнём с выходного слоя, где будут указаны параметры: a21, a22 и b2. Их можно найти в столбцах от CO до DX.

Затем параметры a11 и a12 можно найти в столбцах DY–EV:

И наконец, для параметров смещения b11 и b12 мы используем столбцы EW–FT.

В завершение мы суммируем все частные производные по 12 наблюдениям. Эти агрегированные градиенты аккуратно располагаются в столбцах от Z до AF . Затем обновления параметров выполняются в столбцах от R до X , используя эти значения.

2.6 Визуализация сходимости
Для лучшего понимания процесса обучения мы визуализируем эволюцию параметров во время градиентного спуска с помощью графика. Одновременно в столбце Y отслеживается уменьшение функции стоимости, что позволяет наглядно увидеть сходимость модели.

Заключение
Регрессор на основе нейронной сети — это не волшебство.
Это просто композиция элементарных функций, управляемых определенным количеством параметров и обучаемых путем минимизации четко определенной математической цели.
Создав модель непосредственно в Excel, вы сможете увидеть каждый шаг. Прямое распространение ошибки, вычисление погрешности, частные производные и обновление параметров перестают быть абстрактными понятиями и становятся конкретными вычислениями, которые можно проверить и изменить.
Полная реализация нашей нейронной сети, от прямого распространения до обратного распространения, завершена. Мы предлагаем вам поэкспериментировать, изменяя набор данных, начальные значения параметров или скорость обучения, и понаблюдать за поведением модели во время обучения.
В ходе этого практического занятия мы увидели, как градиенты управляют процессом обучения, как параметры обновляются итеративно и как нейронная сеть постепенно подстраивается под данные. Именно это происходит внутри современных библиотек машинного обучения, лишь скрытое за несколькими строками кода.
Если вы поймете это таким образом, нейронные сети перестанут быть «черными ящиками».
Источник: towardsdatascience.com