
Понимание SVM путем преобразования уже имеющихся знаний
Делиться

SVM, вот мы и здесь.
Именно эта модель с самого начала побудила меня использовать Excel для лучшего понимания машинного обучения.
Сегодня вы увидите другое объяснение SVM, нежели обычно, а именно:
- разделители полей,
- расстояния до гиперплоскости,
- Сначала геометрические построения.
Вместо этого мы будем строить модель шаг за шагом , исходя из того, что нам уже известно.
Возможно, именно сегодня вы наконец скажете: «Ага, теперь я всё лучше понимаю».
Создание новой модели на основе уже имеющихся знаний.
Один из моих главных принципов обучения прост:
Всегда начинайте с того, что нам уже известно .
Перед применением метода опорных векторов (SVM) мы уже изучили:
- логистическая регрессия,
- штрафные санкции и легализация.
Сегодня мы будем использовать эти модели и концепции.
Идея заключается не в создании новой модели, а в преобразовании существующей .
Обучающие наборы данных и правила разметки
Для иллюстрации двух возможных ситуаций, с которыми может столкнуться линейный классификатор, мы используем два сгенерированных мной набора данных :
- один набор данных полностью отделим
- Другая сторона не является полностью отделимой.
Возможно, вы уже знаете, почему мы используем именно эти два набора данных, а не один, верно?
Мы также используем обозначение -1 и 1 вместо 0 и 1 .

В логистической регрессии перед применением сигмоиды мы вычисляем логит . И мы можем обозначить его как f, это линейная оценка.
Эта величина представляет собой линейный показатель, который может принимать любое действительное значение от −∞ до +∞.
- Положительные значения соответствуют одному классу.
- Отрицательные значения соответствуют остальным.
- Ноль — это граница принятия решения.
Использование обозначений -1 и 1 естественным образом соответствует этой интерпретации.
В нем акцент делается на знаке логита , без рассмотрения вероятностей.
Таким образом, мы работаем с чисто линейной моделью , а не в рамках обобщенной линейной модели (GLM).
Здесь нет сигмоиды, нет вероятности, только линейная оценка принятия решения.
Для более краткого выражения этой идеи можно рассмотреть количество:
y(ax + b) = yf(x)
- Если это значение положительное , точка классифицирована правильно.
- Если значение велико , классификация считается достоверной.
- Если значение отрицательное , значит, точка классифицирована неправильно.
На данном этапе мы по-прежнему не говорим о SVM.
Мы лишь уточняем, что означает качественная классификация в линейной среде.
От логарифмической функции потерь к новой функции потерь
При таком подходе мы можем записать логарифмическую функцию потерь для логистической регрессии непосредственно как функцию величины:
yf(x) = y (ax+b)
Мы можем построить график этой функции потерь как функцию от yf(x).
Теперь давайте введем новую функцию потерь, называемую функцией потерь типа «шарнир» .
Если нанести оба показателя потерь на один график, можно заметить, что они имеют довольно схожую форму .
Помните ли вы разницу между коэффициентом Джини и энтропией в классификаторах на основе деревьев решений?
Здесь сравнение очень похожее.

В обоих случаях цель состоит в том, чтобы наказывать:
- точки, которые были неправильно классифицированы yf(x)<0,
- точки, расположенные слишком близко к границе принятия решения .
Разница заключается в способе применения этого штрафа.
- Логарифмическая функция потерь наказывает за ошибки плавно и постепенно .
Даже за хорошо засекреченные очки всё равно начисляются небольшие штрафные баллы. - Потеря шарнира происходит более прямо и резко .
Если точка правильно классифицирована с достаточным запасом, то штрафные санкции больше не применяются .
Таким образом, цель состоит не в том, чтобы изменить то, что мы считаем хорошей или плохой классификацией.
но чтобы упростить способ наложения на это наказания …
Из этого естественным образом вытекает один вопрос.
Можно ли также использовать квадратичную функцию потерь ?
В конце концов, линейную регрессию можно использовать и в качестве классификатора.
Но когда мы это делаем, мы сразу видим проблему:
Квадрат потерь продолжает штрафовать точки, которые уже очень хорошо классифицированы.
Вместо того чтобы фокусироваться на границе принятия решений, модель пытается точно соответствовать числовым целевым значениям.
Именно поэтому линейная регрессия обычно является плохим классификатором, и именно поэтому выбор функции потерь имеет такое большое значение.

Описание новой модели
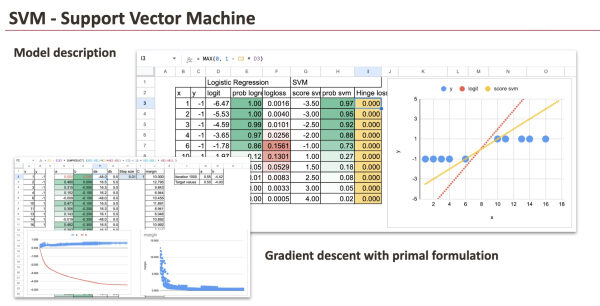
Теперь предположим, что модель уже обучена, и посмотрим непосредственно на результаты.
Для обеих моделей мы вычисляем совершенно одинаковые величины:
- линейный показатель (и в логистической регрессии он называется логитом).
- вероятность (в обоих случаях можно просто применить сигмоидную функцию),
- и сумма убытка .
Это позволяет провести прямое, пошаговое сравнение двух подходов.
Несмотря на различия в функциях потерь, линейные оценки и результирующие классификации на этом наборе данных очень похожи.
Для полностью разделимого набора данных результат очевиден: все точки правильно классифицированы и находятся достаточно далеко от границы принятия решения. В результате функция потерь Hinge равна нулю для каждого наблюдения.
Это приводит к важному выводу.
Когда данные идеально разделимы, единственного решения не существует. На самом деле, существует бесконечно много линейных функций принятия решений , которые дают совершенно одинаковый результат. Мы можем сдвинуть линию, слегка повернуть ее или масштабировать коэффициенты, и классификация останется идеальной, с нулевыми потерями повсюду.
Итак, что же нам делать дальше?
Мы вводим регуляризацию .
Как и в гребенчатой регрессии, мы добавляем штраф за размер коэффициентов . Этот дополнительный член не улучшает точность классификации, но позволяет выбрать одно решение из всех возможных.
Таким образом, в нашем наборе данных мы получаем тот, у которого наименьший наклон a.

И поздравляем, мы только что создали модель SVM .
Теперь мы можем просто записать функцию стоимости для двух моделей: логистической регрессии и SVM.
Помните, что логистическую регрессию можно регуляризовать, и она по-прежнему так называется, верно?

Почему же в модели используется термин «опорные векторы» ?
Если вы посмотрите на набор данных, то увидите, что для определения границы принятия решения достаточно всего нескольких точек, например, точек со значениями 6 и 10. Эти точки называются опорными векторами .
На данном этапе, с учетом используемой нами точки зрения, мы не можем идентифицировать их напрямую.
Позже мы увидим, что с другой точки зрения они выглядят естественно.
И мы можем проделать то же самое для другого набора данных, неразделимого набора данных, но принцип тот же. Ничего не изменилось.
Но теперь мы видим, что для некоторых точек функция потерь шарнира не равна нулю. В нашем случае, показанном ниже, мы можем визуально увидеть, что нам нужны четыре точки в качестве опорных векторов.

Обучение модели SVM с помощью градиентного спуска
Теперь мы обучаем модель SVM явным образом, используя градиентный спуск .
Здесь ничего нового не вводится. Мы используем ту же логику оптимизации, которую уже применяли к линейной и логистической регрессии.
Новая конвенция: лямбда (λ) или C
Во многих моделях, которые мы изучали ранее, таких как гребневая или логистическая регрессия, целевая функция записывается следующим образом:
функция потерь при подгонке данных +λ ∥w∥
В данном случае параметр регуляризации λ регулирует штраф за размер коэффициентов.
Для SVM обычно используется несколько иная конвенция. Мы предпочитаем использовать букву C перед термином data-fit.

Обе формулы эквивалентны .
Они отличаются лишь масштабированием целевой функции.
Мы сохраняем параметр C, потому что это стандартное обозначение, используемое в SVM. И мы увидим, почему у нас есть это соглашение, позже.
Градиент (субградиент)
Мы работаем с линейной функцией принятия решений, и можем определить отступ для каждой точки следующим образом: mi = yi (axi + b)
В потерю шарнира вносят вклад только наблюдения, в которых mi<1.
Ниже представлены субградиенты целевой функции, которые можно реализовать в Excel, используя логические маски и функцию SUMPRODUCT.

Обновление параметров
При заданной скорости обучения или шаге η обновления градиентного спуска выглядят следующим образом, и мы можем использовать обычную формулу:

Мы повторяем эти обновления до достижения сходимости.
И, кстати, эта процедура обучения также дает нам очень наглядный пример для визуализации. На каждой итерации, по мере обновления коэффициентов, размер поля изменяется .
Таким образом, мы можем наглядно увидеть, шаг за шагом, как изменяется граница поля в процессе обучения.
Оптимизационная и геометрическая формулировки метода опорных векторов (SVM)
На рисунке ниже показана одна и та же целевая функция модели SVM, написанная на двух разных языках .

Слева модель представлена в виде задачи оптимизации .
Мы сводим к минимуму сочетание двух факторов:
- термин, который упрощает модель, наказывая за большие коэффициенты.
- а также термин, который предусматривает наказание за ошибки классификации или нарушения границ допустимых значений.
Именно такой подход мы использовали до сих пор. Он естественен, когда мы думаем в терминах функций потерь, регуляризации и градиентного спуска. Это наиболее удобная форма для реализации и оптимизации.
Справа та же модель представлена в геометрической форме .
Вместо того чтобы говорить о потерях, мы говорим о следующем:
- поля,
- ограничения,
- и расстояния до разделительной границы.
Когда данные идеально разделимы, модель ищет разделительную линию с максимально возможным отступом , не допуская никаких нарушений. Это случай жесткого отступа.
Когда идеальное разделение невозможно, нарушения допускаются, но за них предусмотрены штрафы. Это приводит к случаю «мягкой границы».
Важно понимать, что эти две точки зрения строго эквивалентны .
Формулировка задачи оптимизации автоматически обеспечивает соблюдение геометрических ограничений:
- Наложение штрафа на большие коэффициенты соответствует максимизации маржи.
- Наказание за нарушения, связанные с шарнирными соединениями, соответствует разрешению, но контролю нарушений, связанных с полями.
Таким образом, это не две разные модели и не две разные идеи.
Это тот же самый SVM , рассматриваемый с двух взаимодополняющих точек зрения.
Как только эта эквивалентность становится очевидной, SVM становится гораздо менее загадочным: это просто линейная модель с особым способом измерения ошибок и контроля сложности, что естественным образом приводит к известной всем интерпретации максимального поля.
Унифицированный линейный классификатор
С точки зрения оптимизации, теперь мы можем сделать шаг назад и взглянуть на общую картину.
Мы создали не просто «SVM», а общую систему линейной классификации .
Линейный классификатор определяется тремя независимыми выборами:
- линейная функция принятия решений ,
- функция потерь ,
- регуляризационный член .
Как только это становится ясно, многие модели представляют собой простые комбинации этих элементов.
На практике именно это мы можем сделать с помощью SGDClassifier из библиотеки scikit-learn.

С той же точки зрения мы можем:
- объединить функцию потерь шарнира с L1-регуляризацией ,
- заменить потери в шарнире на квадрат потерь в шарнире .
- используйте логарифмические потери, потери на стыке или другие потери, основанные на запасе прочности.
- Выберите штрафы L2 или L1 в зависимости от желаемого поведения.
Каждый выбранный вариант изменяет способ наложения штрафов за ошибки или контроль коэффициентов, но базовая модель остается неизменной: линейная функция принятия решений, обученная методом оптимизации.
Первобытная против двойной формулы
Возможно, вы уже слышали о двойной форме SVM.
До сих пор мы работали исключительно в исходной форме :
- мы напрямую оптимизировали коэффициенты модели.
- с использованием функций потерь и регуляризации.
Двойственная форма — это еще один способ сформулировать ту же задачу оптимизации.
Вместо присвоения весов признакам, в двойной форме каждому элементу данных присваивается коэффициент, обычно называемый альфа .
Мы не будем выводить или реализовывать двойственную форму в Excel, но мы все равно сможем наблюдать ее результат.
Используя scikit-learn, мы можем вычислить значения альфа и убедиться в следующем:
- Первичная и двойственная формы приводят к одной и той же модели .
- Те же границы принятия решений, те же прогнозы.

Что делает двойственную форму особенно интересной для SVM, так это следующее:
- Большинство значений альфа равны нулю.
- Лишь у немногих точек данных значение альфа не равно нулю.
Эти точки являются опорными векторами .
Такое поведение характерно именно для потерь, связанных с запасом прочности, таких как потери в шарнирной области.
Наконец, двойственная форма также объясняет, почему SVM могут использовать трюк с ядром .
Работая со сходством между точками данных, мы можем создавать нелинейные классификаторы, не меняя структуру оптимизации.
Мы увидим это завтра.
Заключение
В этой статье мы не рассматривали SVM как геометрический объект со сложными формулами. Вместо этого мы строили его шаг за шагом, начиная с уже известных нам моделей.
Изменив только функцию потерь , а затем добавив регуляризацию , мы естественным образом пришли к SVM. Сама модель не изменилась. Изменился только способ наложения штрафов за ошибки.
В этом смысле SVM — это не новое семейство моделей. Это естественное расширение линейной и логистической регрессии, рассматриваемое через призму другой функции потерь.
Мы также показали, что:
- Оптимизационный и геометрический подходы эквивалентны.
- Интерпретация принципа максимальной маржи напрямую вытекает из регуляризации.
- А понятие опорных векторов естественным образом вытекает из двойственной перспективы.
Как только эти связи станут ясны, SVM станет гораздо проще для понимания и для размещения в ряду других линейных классификаторов.
На следующем этапе мы воспользуемся этой новой перспективой, чтобы продвинуться дальше и посмотреть, как ядра расширяют эту идею за пределы линейных моделей.
Источник: towardsdatascience.com






















