Отправная точка всех моделей, основанных на весе.
Делиться

Наконец-то линейная регрессия!
Я ждал одиннадцатого дня, чтобы представить эту модель. Она знаменует начало нового этапа в этом «Адвент-календаре».
До сих пор мы в основном рассматривали модели, основанные на расстояниях, соседях или локальной плотности . Как вы, возможно, знаете, для табличных данных деревья решений , особенно ансамбли деревьев решений , демонстрируют очень высокую производительность.
Но начиная с сегодняшнего дня, мы переходим к другой точке зрения: взвешенному подходу .
Линейная регрессия — наш первый шаг в этот мир.
На первый взгляд это кажется простым, но на самом деле это знакомит с основными составляющими современного машинного обучения: функциями потерь, градиентами, оптимизацией, масштабированием, коллинеарностью и интерпретацией коэффициентов.
Когда я говорю «линейная регрессия», я имею в виду линейную регрессию методом наименьших квадратов . По мере того, как мы будем продвигаться по этому «рождественскому календарю» и изучать связанные модели, вы поймете, почему важно это уточнять, поскольку название «линейная регрессия» может вызывать путаницу.
Некоторые утверждают, что линейная регрессия не является машинным обучением.
Их аргумент заключается в том, что машинное обучение — это «новая» область, в то время как линейная регрессия существовала задолго до этого, поэтому её нельзя считать машинным обучением.
Это вводит в заблуждение.
Линейная регрессия идеально подходит для машинного обучения, потому что:
- Оно обучается параметрам на основе данных.
- оно минимизирует функцию потерь.
- Оно делает прогнозы на основе новых данных.
Иными словами, линейная регрессия — одна из старейших моделей, но также и одна из самых фундаментальных в машинном обучении.
Такой подход используется в:
- Линейная регрессия,
- Логистическая регрессия,
- а позже — нейронные сети и LLM.
В глубоком обучении этот взвешенный градиентный подход используется повсеместно .
В современных линейных моделях мы говорим уже не о нескольких параметрах, а о миллиардах весовых коэффициентов .
В данной статье наша модель линейной регрессии имеет ровно 2 веса.
Наклон и точка пересечения с осью Y.
Вот и все.
Но с чего-то же нужно начинать, верно?
Вот несколько вопросов, которые вы можете держать в уме по мере того, как мы будем читать эту статью, а также в последующих.
- Мы попробуем интерпретировать модель. При наличии одного параметра, y=ax+b, всем известно, что a — это наклон, а b — точка пересечения с осью Y. Но как интерпретировать коэффициенты, если параметров 10, 100 или более?
- Почему коллинеарность между признаками представляет собой такую проблему для линейной регрессии? И как можно решить эту проблему?
- Важно ли масштабирование для линейной регрессии?
- Может ли линейная регрессия быть переобучена?
- И как другие модели этого семейства взвешенных моделей (логистическая регрессия, SVM, нейронные сети, Ridge, Lasso и т. д.) связаны с теми же самыми базовыми идеями?
Эти вопросы составляют основу данной статьи и естественным образом приведут нас к будущим темам «Рождественского календаря».
Понимание линии тренда в Excel
Начнем с простого набора данных.
Начнём с очень простого набора данных, который я сгенерировал, используя всего одну характеристику .
На графике ниже по горизонтальной оси отложена переменная признака x, а по вертикальной оси — целевая переменная y.
Цель линейной регрессии — найти два числа, a и b, такие, чтобы можно было записать соотношение:
y = ax + b
Как только мы узнаем a и b, это уравнение становится нашей моделью.

Создание линии тренда в Excel
В Google Sheets или Excel вы можете просто добавить линию тренда , чтобы визуализировать наилучшее линейное соответствие.
Это уже даёт вам результат линейной регрессии.

Но цель этой статьи — вычислить эти коэффициенты самостоятельно .
Если мы хотим использовать модель для прогнозирования, нам необходимо реализовать её напрямую.

Введение в понятие весов и функцию стоимости.
Примечание к моделям, основанным на весе.
Впервые в этом рождественском календаре мы используем гири .
Модели, обучающиеся набирать веса, часто называют параметрическими дискриминантными моделями .
Почему это дискриминация?
Потому что они усваивают правило, которое напрямую разделяет или предсказывает данные, не моделируя процесс их генерации.
До этой главы мы уже рассматривали модели, которые имели параметры , но они не были дискриминантными, а были генеративными .
Давайте быстро подведем итоги.
- Деревья решений используют разбиения , или правила, поэтому в них нет весов, которые нужно обучать. Таким образом, это непараметрические модели.
- k-NN — это не модель. Она сохраняет весь набор данных и использует расстояния во время прогнозирования.
Однако, когда мы переходим от евклидова расстояния к расстоянию Махаланобиса , происходит нечто интересное…
LDA и QDA позволяют оценивать параметры:
- средства каждого класса
- ковариационные матрицы
- приор
Это реальные параметры, но это не веса .
Эти модели являются генеративными , поскольку они моделируют плотность каждого класса, а затем используют её для построения прогнозов.
Таким образом, несмотря на то, что они параметрические, они не относятся к семейству методов, основанных на весовых коэффициентах.
Как видите, это всё классификаторы, и они оценивают параметры для каждого класса.

Линейная регрессия — это наш первый пример модели, которая обучается присваивать веса для построения прогноза.
Это начало новой семьи в Адвент-календаре:
модели, которые используют веса + функцию потерь для прогнозирования.
Функция затрат
Как можно получить параметры a и b?
Итак, оптимальные значения для a и b — это те, которые минимизируют функцию стоимости, то есть квадратичную ошибку модели.
Таким образом, для каждой точки данных мы можем вычислить квадратичную ошибку.
Квадрат ошибки = (предсказание — действительное значение)² = (a*x + b — действительное значение)²
Затем мы можем рассчитать среднеквадратичную ошибку (MSE).
Как видно в Excel, линия тренда показывает оптимальные коэффициенты . Если вручную изменить эти значения, даже незначительно, среднеквадратичная ошибка увеличится.
Именно это и означает здесь слово «оптимальный»: любая другая комбинация a и b усугубляет ошибку.

Классическое аналитическое решение
Теперь, когда мы знаем, что представляет собой модель и что значит минимизировать квадратичную ошибку, мы наконец можем ответить на ключевой вопрос:
Как вычислить два коэффициента линейной регрессии: наклон a и точку пересечения с осью b?
Есть два способа это сделать:
- точное алгебраическое решение , известное как аналитическое решение,
- или градиентный спуск , который мы рассмотрим чуть позже.
Если мы возьмем определение среднеквадратичной ошибки и продифференцируем его по a и b, произойдет нечто прекрасное: все упростится до двух очень компактных формул.

В этих формулах используются только:
- среднее значение x и y,
- как изменяется x (его дисперсия),
- и как x и y изменяются вместе (их ковариация).
Таким образом, даже не зная основ математического анализа и используя лишь базовые функции электронных таблиц, мы можем воспроизвести точное решение, используемое в учебниках по статистике.
Как интерпретировать коэффициенты
Что касается одной из особенностей, то её интерпретация проста и интуитивно понятна:
Наклон а
Это показывает, насколько изменяется значение y при увеличении x на одну единицу.
Если коэффициент наклона равен 1,2, это означает:
«Когда x увеличивается на 1, модель ожидает, что y увеличится примерно на 1,2».
Пересечение с осью b
Это прогнозируемое значение y при x = 0.
Зачастую в реальном контексте данных значение x = 0 не существует, поэтому сам по себе коэффициент пересечения не всегда имеет смысл.
Его основная задача — правильно расположить линию так, чтобы она совпадала с центром данных.
Обычно именно так преподают линейную регрессию:
Наклон, точка пересечения с осью Y и прямая линия.
Благодаря одной функции, интерпретация становится простой.
Вдвоем еще вполне справляемся.
Но как только мы начинаем добавлять много функций, задача становится сложнее.
Завтра мы подробнее обсудим вопросы интерпретации.
Сегодня мы проведем градиентный спуск.
Постепенный спуск, шаг за шагом
После рассмотрения классического алгебраического решения задачи линейной регрессии мы можем теперь изучить другой важный инструмент современного машинного обучения: оптимизацию .
Основной алгоритм оптимизации — градиентный спуск .
Понимание этого на очень простом примере делает логику гораздо яснее, когда мы применяем ее к линейной регрессии.
Небольшая разминка: градиентный спуск по одной переменной
Прежде чем применять градиентный спуск для линейной регрессии, мы можем сначала сделать это для простой функции: (x-2)^2.
Всем известно, что минимум находится при x=2.
Но давайте сделаем вид, что мы этого не знаем, и позволим алгоритму обнаружить это самостоятельно.
Идея состоит в том, чтобы найти минимум этой функции, используя следующий процесс:
- Сначала мы случайным образом выбираем начальное значение.
- Затем на каждом шаге мы вычисляем значение производной функции df (для данного значения x): df(x)
- Следующее значение x получается путем вычитания значения производной, умноженного на шаг производной: x = x – step_size*df(x)
Вы можете изменить два параметра градиентного спуска: начальное значение x и размер шага.
Да, даже со 100 или 1000. Удивительно, насколько хорошо это работает.

Однако в некоторых случаях градиентный спуск может не сработать. Например, если шаг слишком велик, значение x может резко возрасти.

Градиентный спуск для линейной регрессии
Принцип алгоритма градиентного спуска тот же, что и для линейной регрессии: необходимо вычислить частные производные функции стоимости по параметрам a и b. Обозначим их как da и db.
Квадрат ошибки = (предсказание — действительное значение)² = (a*x + b — действительное значение)²
da = 2(a*x + b — действительное значение)*x
db = 2(a*x + b — действительное значение)

А затем мы сможем обновить коэффициенты.

Благодаря этому небольшому обновлению, шаг за шагом, оптимальное значение будет найдено после нескольких итераций.
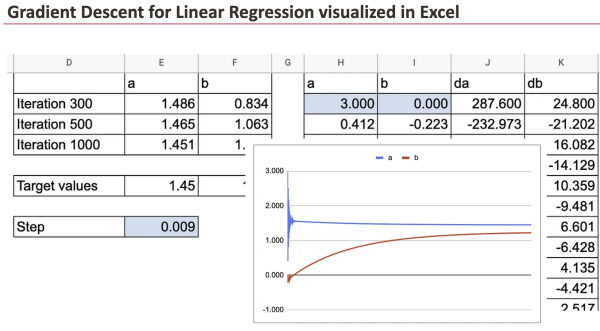
На следующем графике видно, как значения a и b приближаются к целевому значению.

Мы также можем увидеть все подробности о y-значении, остатках и частных производных.
Мы можем в полной мере оценить красоту градиентного спуска, визуализированного в Excel.
На примере этих двух коэффициентов можно наблюдать, насколько быстро происходит сходимость.

На практике у нас много наблюдений, и это нужно делать для каждой точки данных. Вот тут-то и начинаются сложности в Google Sheets. Поэтому мы используем только 10 точек данных.
Вы увидите, что сначала я создал лист с длинными формулами для расчета da и db, которые содержат сумму производных всех наблюдений. Затем я создал еще один лист, чтобы показать все подробности.
Заключение
Линейная регрессия может показаться простой, но она охватывает практически все аспекты современного машинного обучения.
Используя всего два параметра — наклон и точку пересечения с осью Y, — это позволяет нам узнать следующее:
- Как определить функцию затрат?
- как найти оптимальные параметры численным методом
- и как работает оптимизация при корректировке скорости обучения или начальных значений.
Представленное в замкнутой форме решение демонстрирует элегантность математического подхода.
Функция градиентного спуска демонстрирует механику процесса.
Вместе они составляют основу семейства методов «взвешенных функций + функций потерь», в которое входят логистическая регрессия, SVM, нейронные сети и даже современные LLM.
Новые пути впереди
Возможно, вам кажется, что линейная регрессия — это простая вещь, но, теперь, когда ее основы ясны, вы можете расширить, уточнить и переосмыслить ее с разных точек зрения:
- Измените функцию потерь
Замените квадратичную ошибку на логистическую функцию потерь, функцию потерь типа «шарнир» или другие функции, и появятся новые модели. - Перейти к классификации
Сама по себе линейная регрессия может разделять два класса (0 и 1), но более устойчивые варианты — это логистическая регрессия и SVM. А что насчет многоклассовой классификации? - нелинейность модели
Благодаря полиномиальным свойствам или ядрам линейные модели внезапно становятся нелинейными в исходном пространстве. - Масштабирование до множества функций
Интерпретация становится сложнее, регуляризация становится необходимой, и возникают новые численные задачи. - Первобытный против двойственного
Линейные модели можно записывать двумя способами. В прямом представлении веса определяются напрямую. В двойном представлении все переписывается с помощью скалярного произведения между точками данных. - Разберитесь в современном машинном обучении.
Градиентный спуск и его варианты лежат в основе нейронных сетей и больших языковых моделей.
Полученные здесь знания, основанные на двух параметрах, применимы к миллиардам.
Всё в этой статье остаётся в рамках линейной регрессии, но при этом закладывает основу для целого семейства будущих моделей.
День за днем Адвент-календарь будет показывать, как все эти идеи взаимосвязаны.
Источник: towardsdatascience.com