Кластеризация и обнаружение аномалий на основе анализа соседних участков.
Делиться

Вот и наступил 10-й день моего «Рождественского календаря» по машинному обучению. Хочу поблагодарить вас за поддержку.
Я создаю эти файлы Google Sheets уже много лет. Они постепенно развивались. Но когда приходит время их публиковать, мне всегда требуются часы, чтобы всё переорганизовать, привести в порядок и сделать их удобными для чтения.
Сегодня мы переходим к DBSCAN .
DBSCAN не обучается параметрической модели.
Как и LOF, DBSCAN не является параметрической моделью. Здесь нет формулы для хранения, нет правил, нет центроидов и ничего компактного для последующего использования.
Мы должны сохранить весь набор данных, поскольку структура плотности зависит от всех точек.
Его полное название — Density-Based Spatial Clustering of Applications with Noise (Пространственная кластеризация приложений на основе плотности с учетом шума) .
Но будьте осторожны: эта «плотность» не является гауссовой плотностью.
Это основанное на подсчетах понятие плотности населения. Просто «сколько соседей живут рядом со мной».
Почему DBSCAN особенный
Как следует из названия, DBSCAN выполняет две функции одновременно :
- оно находит кластеры
- Это отмечает аномалии (точки, которые не принадлежат ни к одному кластеру).
Именно поэтому я представляю алгоритмы в таком порядке:
- k -средних и GMM — это модели кластеризации . В качестве выходных данных они выдают компактный объект: центроиды для k-средних, средние значения и дисперсии для GMM.
- Isolation Forest и LOF — это модели, предназначенные исключительно для обнаружения аномалий . Их единственная цель — найти необычные точки.
- DBSCAN занимает промежуточное положение. Он выполняет как кластеризацию, так и обнаружение аномалий , основываясь исключительно на понятии плотности окрестности.
Небольшой набор данных для большей интуитивности.
Мы используем тот же небольшой набор данных, что и для LOF: 1, 2, 3, 7, 8, 12
Если вы посмотрите на эти цифры, вы уже увидите две компактные группы:
Один примерно 1–2–3 года , другой примерно 7–8 лет , а 12 живут одни.
DBSCAN точно передает эту интуицию.
Краткое изложение в 3 шага
DBSCAN задает три простых вопроса для каждой точки:
- Сколько у вас соседей в пределах небольшого радиуса (eps)?
- У вас достаточно соседей, чтобы стать ключевой точкой (minPts)?
- После того, как мы определим ключевые моменты, к какой из связанных групп вы принадлежите?
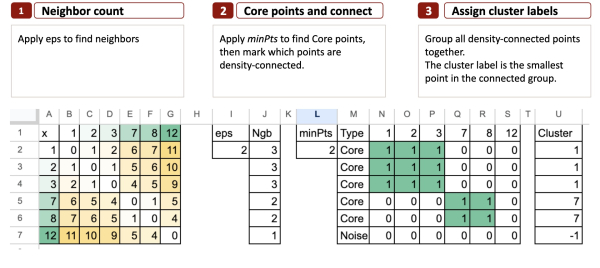
Вот краткое описание алгоритма DBSCAN в 3 шага :

Начнём шаг за шагом.
DBSCAN в 3 шага
Теперь, когда мы понимаем концепцию плотности застройки и районов, DBSCAN становится очень легко описать.
Вся работа алгоритма укладывается в три простых шага .
Шаг 1 – Подсчитайте соседей
Цель состоит в том, чтобы проверить, сколько соседей у каждой точки.
Мы берем небольшой радиус, называемый eps .
Для каждой точки мы рассматриваем все остальные точки и отмечаем те, расстояние до которых меньше eps.
Это наши соседи .
Это даёт нам первое представление о плотности:
Точка, имеющая множество соседей, находится в плотном регионе.
Точка с небольшим количеством соседей находится в малонаселенном регионе.
В качестве примера с одномерной игрушкой, как в нашем случае, обычно выбирают следующее:
eps = 2
Вокруг каждой точки мы рисуем небольшой интервал радиусом 2.
Почему он называется eps ?
Название eps происходит от греческой буквы ε (эпсилон) , которая традиционно используется в математике для обозначения малой величины или малого радиуса вокруг точки.
Таким образом, в DBSCAN eps буквально означает «небольшой радиус окрестности».
Это отвечает на вопрос:
Насколько далеко мы заглядываем вокруг каждой точки?
Таким образом, в Excel первым шагом является вычисление матрицы попарных расстояний , а затем подсчет количества соседей у каждой точки в пределах eps.

Шаг 2 – Ключевые точки и плотность связности
Теперь, когда мы знаем соседей из Шага 1, мы применяем minPts , чтобы определить, какие точки являются Core .
В данном случае minPts означает минимальное количество баллов.
Это наименьшее количество соседей, которое должна иметь точка (внутри радиуса eps), чтобы считаться основной точкой.
Точка считается ядром, если она имеет как минимум minPts соседей внутри eps .
В противном случае, это может превратиться в «Границу» или «Шум» .
При eps = 2 и minPts = 2 у нас получается 12 элементов, которые не относятся к Core.
Как только ключевые точки известны, мы просто проверяем, какие точки достижимы из них с точки зрения плотности. Если точка может быть достигнута путем перемещения из одной ключевой точки в другую в пределах eps, она принадлежит к той же группе.
В Excel это можно представить в виде простой таблицы связей, показывающей, какие точки связаны через соседние точки ядра сети.
Именно эти взаимосвязи DBSCAN использует для формирования кластеров на шаге 3.

Шаг 3 – Присвоение меток кластерам
Цель состоит в том, чтобы преобразовать возможности подключения в реальные кластеры.
Как только матрица связности будет готова, кластеры появятся естественным образом.
DBSCAN просто группирует все связанные точки вместе.
Чтобы дать каждой группе простое и воспроизводимое название, мы используем очень интуитивно понятное правило:
Метка кластера — это наименьшая точка в связанной группе.
Например:
- Группа {1, 2, 3} становится кластером 1.
- Группа {7, 8} становится кластером 7
- Точка, подобная 12, не имеющая соседей в ядре, становится шумом.
Именно это мы и отобразим в Excel с помощью формул.

Заключительные мысли
DBSCAN идеально подходит для обучения понятию локальной плотности.
Здесь нет вероятности, нет формулы Гаусса, нет этапа оценки.
Просто расстояния, соседи и небольшой радиус.
Но эта простота также ограничивает его возможности.
Поскольку DBSCAN использует один фиксированный радиус для всех, он не может адаптироваться, когда набор данных содержит кластеры разного масштаба.
HDBSCAN сохраняет ту же самую интуитивность, но анализирует все радиусы и сохраняет только те, которые остаются стабильными.
Этот метод гораздо надежнее и намного ближе к тому, как люди естественным образом воспринимают кластеры.
Источник: towardsdatascience.com