Почему традиционный метод RAG теряет контекст и как контекстный поиск значительно повышает точность поиска
Делиться

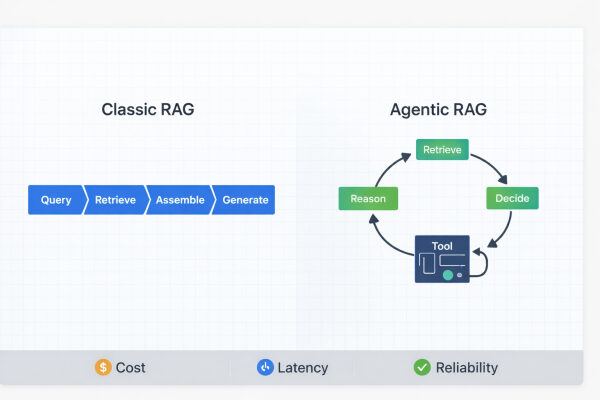
В своей последней публикации я рассказывал о том, как гибридный поиск может значительно повысить эффективность конвейера RAG. RAG в своей базовой версии, использующий только семантический поиск по эмбеддингам, может быть очень эффективным, позволяя нам использовать возможности ИИ в наших собственных документах. Тем не менее, семантический поиск, каким бы мощным он ни был, при использовании в больших базах знаний иногда может пропускать точные совпадения запроса пользователя, даже если они существуют в документах. Этот недостаток традиционного RAG можно устранить, добавив в конвейер компонент поиска по ключевым словам, например, BM25. Таким образом, гибридный поиск, сочетающий семантический поиск и поиск по ключевым словам, приводит к гораздо более полным результатам и значительно повышает производительность системы RAG.

Как бы то ни было, даже при использовании RAG с гибридным поиском мы все равно можем иногда упускать важную информацию, разбросанную по разным частям документа. Это может происходить потому, что при разбиении документа на текстовые фрагменты иногда теряется контекст — то есть окружающий текст фрагмента, составляющий часть его смысла. Это особенно часто случается со сложным текстом, смысл которого взаимосвязан и разбросан по нескольким страницам и неизбежно не может быть полностью включен в один фрагмент. Например, ссылка на таблицу или изображение в нескольких разных текстовых разделах без явного указания, к какой именно таблице мы обращаемся (например, «как показано в таблице, прибыль увеличилась на 6%» — к какой именно таблице?). В результате, при последующем извлечении текстовых фрагментов, они лишаются своего контекста, что иногда приводит к извлечению нерелевантных фрагментов и генерации нерелевантных ответов.
Потеря контекста долгое время была серьезной проблемой для систем RAG, и было предпринято несколько не слишком успешных попыток ее решения. Очевидная попытка улучшить ситуацию — увеличение размера фрагмента, но это часто также изменяет семантическое значение каждого фрагмента и в конечном итоге делает поиск менее точным. Другой подход — увеличение перекрытия фрагментов. Хотя это помогает повысить сохранение контекста, это также увеличивает затраты на хранение и вычисления. Что наиболее важно, это не решает проблему полностью — важные взаимосвязи с фрагментом могут по-прежнему выходить за его границы. Более продвинутые подходы, пытающиеся решить эту проблему, включают гипотетические векторные представления документов (HyDE) или индексы сводной информации о документах. Тем не менее, они по-прежнему не обеспечивают существенных улучшений.
В конечном итоге, эффективным решением этой проблемы, значительно улучшающим результаты работы системы RAG, является контекстный поиск , впервые представленный компанией Anthropic в 2024 году. Цель контекстного поиска — устранить потерю контекста путем сохранения контекста фрагментов и, следовательно, повышения точности этапа поиска в конвейере RAG.
…
А как насчет контекста?
Прежде чем говорить о контекстном поиске, давайте немного отступим назад и поговорим о том, что такое контекст. Конечно, мы все слышали о контексте LLM или контекстных окнах, но что это такое на самом деле?
Если говорить точнее, контекст — это все токены, доступные модели распознавания речи (LLM), на основе которых она предсказывает следующее слово. Напомним, что LLM работают, генерируя текст путем пошагового предсказания каждого слова. Таким образом, это может быть подсказка пользователя, системная подсказка, инструкции, навыки или любые другие указания, влияющие на то, как модель выдает ответ. Важно отметить, что часть окончательного ответа, которую модель уже сгенерировала, также является частью контекста, поскольку каждый новый токен генерируется на основе всего, что было до него.
По-видимому, разные контексты приводят к совершенно разным результатам работы модели. Например:
- «Я пошёл в ресторан и заказал» — в результате может получиться «пицца».
- «Я пошёл в аптеку и купил» может вывести «лекарство».
Фундаментальным ограничением моделей с линейной архитектурой (LLM) является их контекстное окно . Контекстное окно LLM — это максимальное количество токенов, которые могут быть одновременно переданы в качестве входных данных модели и учтены для получения одного ответа. Существуют LLM с большими или меньшими контекстными окнами. Современные модели с линейной архитектурой могут обрабатывать сотни тысяч токенов в одном запросе, тогда как более ранние модели часто имели контекстные окна размером всего в 8000 токенов.
В идеальном мире мы бы хотели просто передать всю необходимую для LLM информацию в контексте, и, скорее всего, получили бы очень хорошие ответы. И это в какой-то степени верно — модель, подобная Opus 4.6, с контекстным окном в 200 000 токенов соответствует примерно 500-600 страницам текста. Если вся необходимая нам информация укладывается в этот лимит, мы действительно можем просто включить все как есть, в качестве входных данных для LLM, и получить отличный ответ.
Проблема заключается в том, что для большинства реальных сценариев использования ИИ нам необходима база знаний, размер которой значительно превышает этот порог — например, юридические библиотеки или руководства по техническому оборудованию. Поскольку модели имеют ограничения по контекстному окну, мы, к сожалению, не можем просто передать все в LLM и позволить ей волшебным образом ответить — нам нужно каким- то образом выбрать наиболее важную информацию, которая должна быть включена в наше ограниченное контекстное окно. И именно в этом, по сути, заключается методология RAG — в выборе соответствующей информации из большой базы знаний для эффективного ответа на запрос пользователя. В конечном итоге это превращается в задачу оптимизации/проектирования — контекстное проектирование — определение соответствующей информации для включения в ограниченное контекстное окно, чтобы получить наилучшие возможные ответы.
Это наиболее важная часть системы RAG — обеспечение извлечения соответствующей информации и её передачи в качестве входных данных в LLM. Это можно сделать с помощью семантического поиска и поиска по ключевым словам, как уже объяснялось. Тем не менее, даже при извлечении всех семантически релевантных фрагментов и всех точных совпадений, всё ещё существует большая вероятность того, что некоторая важная информация может остаться незамеченной.
Но что это за информация? Поскольку мы уже рассмотрели значение с помощью семантического поиска и точные совпадения с помощью поиска по ключевым словам, какие еще типы информации следует учитывать?
Различные документы с принципиально разным смыслом могут содержать части, похожие или даже идентичные. Представьте себе книгу рецептов и руководство по химической обработке, в которых читателю предписывается «Медленно нагревать смесь». Семантическое значение такого фрагмента текста и сами слова очень похожи — идентичны. В этом примере то, что формирует смысл текста и позволяет нам различать кулинарию и химическую инженерию, — это то, что мы называем контекстом .

Таким образом, именно такую дополнительную информацию мы стремимся сохранить. И именно это и делает контекстный поиск: он сохраняет контекст — окружающий смысл — каждого фрагмента текста.
…
А как насчет контекстного поиска?
Таким образом, контекстный поиск — это методология, применяемая в RAG, направленная на сохранение контекста каждого фрагмента. Благодаря этому, когда фрагмент извлекается и передается в LLM в качестве входных данных, мы можем сохранить как можно больше его первоначального значения — семантику, ключевые слова, контекст — всё.
Для достижения этой цели контекстный поиск предполагает, что сначала мы генерируем вспомогательный текст для каждого фрагмента — а именно, контекстный текст , — который позволяет нам определить место фрагмента текста в исходном документе, из которого он взят. На практике мы просим магистра права (LLM) сгенерировать этот контекстный текст для каждого фрагмента. Для этого мы предоставляем документ вместе с самим фрагментом в одном запросе к LLM и просим его «предоставить контекст для определения места конкретного фрагмента в документе». Запрос на генерацию контекстного текста для нашего фрагмента «Итальянская поваренная книга» будет выглядеть примерно так:
the entire document Italian Cookbook document the chunk comes from Here is the chunk we want to place within the context of the full document. the actual chunk Provide a brief context that situates this chunk within the overall document to improve search retrieval. Respond only with the concise context and nothing else.Функция LLM возвращает контекстный текст, который мы объединяем с исходным фрагментом текста. Таким образом, для каждого фрагмента исходного текста мы генерируем контекстный текст, описывающий, как этот конкретный фрагмент расположен в родительском документе. В нашем примере это будет выглядеть примерно так:
Context: Recipe step for simmering homemade tomato pasta sauce. Chunk: Heat the mixture slowly and stir occasionally to prevent it from sticking.Это действительно гораздо более информативно и конкретно! Теперь нет никаких сомнений в том, что это за загадочная смесь, потому что вся необходимая информация для определения, говорим ли мы о томатном соусе или о лабораторных растворах крахмала, удобно собрана в одном и том же блоке.
С этого момента мы рассматриваем исходный текст фрагмента и контекстный текст как неразрывную пару. Затем остальные шаги RAG с гибридным поиском выполняются практически так же. То есть мы создаем эмбеддинги, которые хранятся в векторном поиске и индексе BM25 для каждого фрагмента текста, с добавлением его контекстного текста в начало.

Этот простой подход приводит к поразительному улучшению производительности поиска в конвейерах RAG. По данным Anthropic, контекстный поиск повышает точность поиска на впечатляющие 35%.
…
Снижение затрат за счет оперативного кэширования.
Я слышу, как вы спрашиваете: «Но разве это не обойдется в целое состояние?». Удивительно, но нет.
Интуитивно мы понимаем, что такая настройка значительно увеличит стоимость обработки данных в конвейере RAG — по сути, вдвое, если не больше. В конце концов, мы добавили множество дополнительных вызовов к LLM, не так ли? Это верно лишь отчасти — действительно, теперь для каждого фрагмента мы делаем дополнительный вызов к LLM, чтобы поместить его в исходный документ и получить контекстный текст.
Однако эти затраты мы несем только один раз, на этапе загрузки документа. В отличие от альтернативных методов, которые пытаются сохранить контекст во время выполнения — таких как гипотетические векторные представления документов (HyDE) — контекстный поиск выполняет основную работу на этапе загрузки документа. В подходах, основанных на времени выполнения, для каждого запроса пользователя требуются дополнительные вызовы LLM, что может быстро привести к увеличению задержки и операционных затрат. В отличие от этого, контекстный поиск переносит вычисления на этап загрузки, а это означает, что улучшенное качество поиска не сопровождается дополнительными накладными расходами во время выполнения. Кроме того, для дальнейшего снижения затрат на контекстный поиск можно использовать дополнительные методы. Точнее, можно использовать кэширование для генерации краткого описания документа только один раз, а затем сопоставления каждого фрагмента с полученным кратким описанием документа.
…
В моих мыслях
Контекстный поиск представляет собой простое, но мощное усовершенствование традиционных систем RAG. Обогащая каждый фрагмент контекстным текстом и точно определяя его семантическую позицию в исходном документе, мы значительно уменьшаем неоднозначность каждого фрагмента и, таким образом, повышаем качество информации, передаваемой в LLM. В сочетании с гибридным поиском этот метод позволяет одновременно сохранять семантику, ключевые слова и контекст.
Понравился этот пост? Давайте дружить! Присоединяйтесь ко мне:
📰 Substack 💌 Medium 💼 LinkedIn ☕ Угостите меня кофе!
Все изображения предоставлены автором, если не указано иное.
Мария Мушуци Посмотреть все от Марии Мушуци
Источник: towardsdatascience.com