Новое исследование выявило скрытые признаки ошибочных корреляций и предложило метод повышения точности.  «Мы показали, что даже при обучении моделей на больших объемах данных и выборе наилучшей усредненной модели, в новых условиях эта «лучшая модель» может оказаться наихудшей моделью для 6-75 процентов новых данных», — говорит доцент Марзие Гассеми. Изображение: iStock
«Мы показали, что даже при обучении моделей на больших объемах данных и выборе наилучшей усредненной модели, в новых условиях эта «лучшая модель» может оказаться наихудшей моделью для 6-75 процентов новых данных», — говорит доцент Марзие Гассеми. Изображение: iStock
Исследователи из Массачусетского технологического института выявили значительные примеры сбоев в работе моделей машинного обучения при применении этих моделей к данным, отличным от тех, на которых они обучались. Это поднимает вопрос о необходимости тестирования моделей при каждом их развертывании в новых условиях.
«Мы показали, что даже при обучении моделей на больших объемах данных и выборе наилучшей усредненной модели, в новых условиях эта «лучшая модель» может оказаться наихудшей моделью для 6-75 процентов новых данных», — говорит Марзие Гассеми, доцент кафедры электротехники и компьютерных наук (EECS) Массачусетского технологического института, член Института медицинской инженерии и науки и главный исследователь Лаборатории информационных и систем принятия решений.
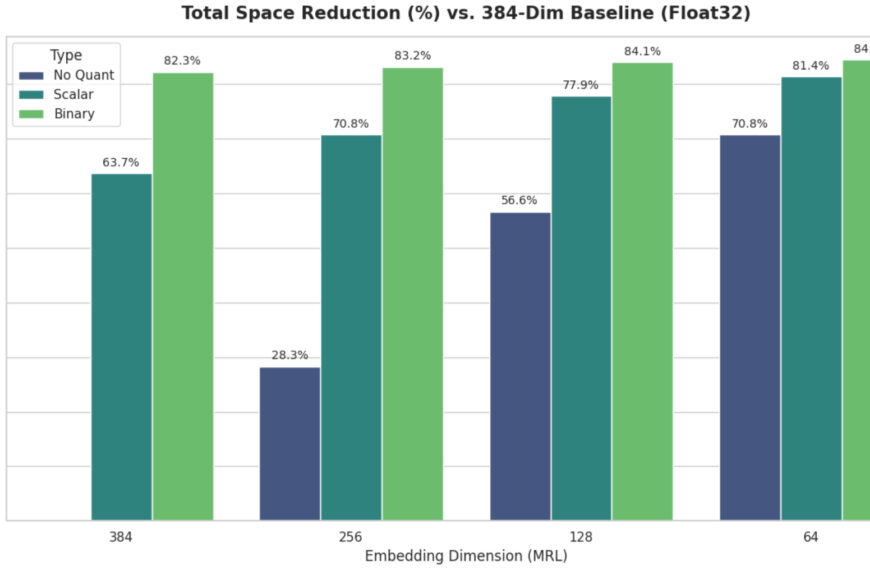
В статье, представленной на конференции Neural Information Processing Systems (NeurIPS 2025) в декабре, исследователи отмечают, что модели, обученные эффективно диагностировать заболевания по рентгеновским снимкам грудной клетки в одной больнице, например, могут считаться эффективными в среднем и в другой больнице. Однако проведенная исследователями оценка производительности показала, что некоторые из лучших моделей в первой больнице показали наихудшие результаты для 75 процентов пациентов во второй больнице, хотя при объединении всех пациентов во второй больнице высокие средние показатели скрывают этот недостаток.
Результаты их исследований показывают, что, хотя ложные корреляции — простой пример тому: система машинного обучения, не «видев» много фотографий коров на пляже, классифицирует фотографию коровы на пляже как косатку просто из-за фона — считаются устраненными путем улучшения производительности модели на наблюдаемых данных, на самом деле они все еще возникают и остаются риском для надежности модели в новых условиях. Во многих случаях — включая области, исследованные учеными, такие как рентгеновские снимки грудной клетки, гистопатологические изображения раковых заболеваний и обнаружение разжигания ненависти — такие ложные корреляции гораздо сложнее обнаружить.
В случае, например, модели медицинской диагностики, обученной на рентгеновских снимках грудной клетки, модель могла научиться сопоставлять специфическую и не имеющую отношения к делу метку на рентгеновских снимках в одной больнице с определенной патологией. В другой больнице, где эта метка не используется, эта патология может быть пропущена.
Предыдущие исследования группы Гассеми показали, что модели могут ложно коррелировать такие факторы, как возраст, пол и раса, с медицинскими данными. Например, если модель была обучена на большем количестве рентгеновских снимков грудной клетки пожилых людей с пневмонией и «видела» меньше снимков, принадлежащих более молодым людям, она может предсказать, что пневмония встречается только у пожилых пациентов.
«Мы хотим, чтобы модели научились анализировать анатомические особенности пациента и принимать решения на их основе, — говорит Олавале Салаудин, научный сотрудник Массачусетского технологического института и ведущий автор статьи, — но на самом деле модель может использовать всё, что есть в данных и коррелирует с принимаемым решением. И эти корреляции могут быть не очень устойчивыми при изменениях окружающей среды, что делает прогнозы модели ненадежным источником информации для принятия решений».
Ложные корреляции способствуют риску принятия предвзятых решений. В докладе, представленном на конференции NeurIPS, исследователи показали, например, что модели рентгеновских снимков грудной клетки, улучшающие общую диагностическую эффективность, на самом деле показывают худшие результаты у пациентов с плевральными заболеваниями или увеличенным кардиомедиастинумом, то есть увеличением сердца или центральной полости грудной клетки.
В число других авторов статьи вошли аспиранты Хаоран Чжан и Кумаил Альхамуд, доцент кафедры электротехники и информатики Сара Бири и Гассеми.
Хотя в предыдущих работах в целом считалось, что модели, упорядоченные по показателям эффективности от лучших к худшим, сохранят этот порядок при применении в новых условиях, что называется точностью на линии, исследователи смогли продемонстрировать примеры, когда модели с наилучшими показателями в одних условиях оказывались моделями с наихудшими показателями в других.
Салаудин разработал алгоритм под названием OODSelect для поиска примеров, где точность вычислений на линии была нарушена. По сути, он обучил тысячи моделей, используя данные из распределения, то есть данные из первого набора данных, и вычислил их точность. Затем он применил модели к данным из второго набора данных. Когда модели с наивысшей точностью на данных первого набора данных оказывались неверными при применении к большому проценту примеров во втором наборе данных, это позволило выявить проблемные подмножества или субпопуляции. Салаудин также подчеркивает опасность использования агрегированной статистики для оценки, которая может скрывать более детальную и важную информацию о производительности модели.
В ходе своей работы исследователи выделили «наиболее ошибочные примеры», чтобы не смешивать ложные корреляции в наборе данных с ситуациями, которые просто трудно классифицировать.
В статье, опубликованной на конференции NeurIPS, представлен код исследователей, а также некоторые определенные подмножества данных для дальнейшей работы.
Как только больница или любая организация, использующая машинное обучение, выявит подмножества данных, на которых модель работает плохо, эту информацию можно использовать для улучшения модели в соответствии с конкретной задачей и условиями. Исследователи рекомендуют в будущих работах использовать OODSelect для выделения целей оценки и разработки подходов к более последовательному улучшению производительности.
«Мы надеемся, что опубликованный код и подмножества OODSelect станут ступенькой на пути к созданию эталонных показателей и моделей, которые позволят противостоять негативным последствиям ложных корреляций», — пишут исследователи.
Источник: news.mit.edu