Создайте с нуля высокопроизводительный конвейер данных датчиков и раскройте истинную скорость научного вычислительного ядра Python.
Делиться

Чтобы изучить NumPy, я веду серию мини-проектов. Например, проект «Анализ личных привычек и погоды». Но у меня ещё не было возможности изучить все возможности NumPy. Я хочу понять, почему NumPy так полезен для анализа данных. В завершение серии я покажу это в режиме реального времени.
Для создания интерактивности я буду использовать вымышленного клиента или компанию. В данном случае нашим клиентом будет EnviroTech Dynamics , глобальный оператор промышленных сенсорных сетей.
В настоящее время EnviroTech использует устаревшие циклические скрипты Python для обработки более миллиона показаний датчиков ежедневно . Этот процесс невероятно медленный, задерживая принятие критически важных решений по обслуживанию и снижая эффективность работы. Им необходимо современное высокопроизводительное решение.
Мне было поручено создать прототип концепции на основе NumPy, чтобы продемонстрировать, как можно ускорить их конвейер данных .
Набор данных: смоделированные показания датчиков
Чтобы доказать эту концепцию, я буду работать с большим моделированным набором данных, сгенерированным с использованием случайного модуля NumPy, включающим записи со следующими ключевыми массивами:
- Температура — каждая точка данных показывает, насколько сильно нагревается машина или компонент системы. Эти показания помогают быстро определить, когда машина начинает перегреваться — это признак возможного сбоя, неэффективности или угрозы безопасности.
- Давление — данные, показывающие, какое давление нарастает внутри системы и находится ли оно в безопасном диапазоне.
- Коды состояния — отображают состояние каждой машины или системы в данный момент. 0 (нормальное), 1 (предупреждение), 2 (критическое), 3 (неисправность/отсутствует).
Цели проекта
Основная цель — предоставить четыре понятных векторных решения для задач EnviroTech, связанных с данными, демонстрируя скорость и эффективность. Поэтому я продемонстрирую их все:
- Тест производительности и эффективности
- Основополагающая статистическая база
- Обнаружение критических аномалий и
- Очистка и импутация данных
К концу этой статьи вы сможете получить полное представление о NumPy и его пользе для анализа данных.
Цель 1: Оценка производительности и эффективности
Во-первых, нам нужен огромный набор данных, чтобы разница в скорости стала очевидной. Я буду использовать 1 000 000 показаний температуры, которые мы запланировали ранее.
import numpy as np # Устанавливаем размер наших данных NUM_READINGS = 1_000_000 # Генерируем массив температур (1 миллион случайных чисел с плавающей точкой) # Мы используем начальное число, поэтому результаты будут одинаковыми при каждом запуске кода np.random.seed(42) mean_temp = 45.0 std_dev_temp = 12.0 temperature_data = np.random.normal(loc=mean_temp, scale=std_dev_temp, size=NUM_READINGS) print(f»Размер массива данных: {temperature_data.size} элементов») print(f»Первые 5 температур: {temperature_data[:5]}»)
Выход:
Размер массива данных: 1000000 элементов Первые 5 температур: [50,96056984 43,34082839 52,77226246 63,27635828 42,1901595 ]
Теперь, когда у нас есть записи, давайте проверим эффективность NumPy.
Предположим, мы хотим вычислить среднее значение всех этих элементов, используя стандартный цикл Python, это будет выглядеть примерно так.
# Функция, использующая стандартный цикл Python def calculate_mean_loop(data): total = 0 count = 0 for value in data: total += value count += 1 return total / count # Давайте запустим ее один раз, чтобы убедиться, что она работает loop_mean = calculate_mean_loop(temperature_data) print(f»Mean (Loop method): {loop_mean:.4f}»)
В этом методе нет ничего плохого. Но он довольно медленный, поскольку компьютеру приходится обрабатывать каждое число по одному, постоянно переключаясь между интерпретатором Python и процессором.
Чтобы по-настоящему продемонстрировать скорость, я воспользуюсь командой %timeit. Она запускает код сотни раз, обеспечивая достоверное среднее время выполнения.
# Расчет времени стандартного цикла Python (будет медленным) print(“ — — Расчет времени цикла Python — -”) %timeit -n 10 -r 5 calculate_mean_loop(temperature_data)
Выход
— Измерение времени выполнения цикла Python — 244 мс ± 51,5 мс на цикл (среднее значение ± стандартное отклонение для 5 запусков, по 10 циклов в каждом)
Используя -n 10, я, по сути, запускаю код в цикле 10 раз (чтобы получить стабильное среднее значение), а используя -r 5, весь процесс будет повторяться 5 раз (для еще большей стабильности).
Теперь сравним это с векторизацией NumPy. Под векторизацией подразумевается, что вся операция (в данном случае усреднённая) будет выполнена над всем массивом одновременно, с использованием высокооптимизированного кода на C в фоновом режиме.
Вот как будет рассчитано среднее значение с использованием NumPy
# Используем встроенную функцию NumPy mean def calculate_mean_numpy(data): return np.mean(data) # Запустим ее один раз, чтобы убедиться, что она работает numpy_mean = calculate_mean_numpy(temperature_data) print(f»Mean (метод NumPy): {numpy_mean:.4f}»)
Выход:
Среднее (метод NumPy): 44,9808
Теперь засекаем время.
# Время векторизованной функции NumPy (будет быстро) print(“ — — Расчет времени векторизации NumPy — -”) %timeit -n 10 -r 5 calculate_mean_numpy(temperature_data)
Выход:
— Расчет времени векторизации NumPy — 1,49 мс ± 114 мкс на цикл (среднее значение ± стандартное отклонение для 5 запусков, 10 циклов в каждом)
Это огромная разница. Практически несуществующая. Вот в чём сила векторизации.
Давайте представим эту разницу в скорости клиенту:
«Мы сравнили два метода выполнения одного и того же вычисления для миллиона показаний температуры — традиционный цикл for Python и векторизованную операцию NumPy.
Разница была колоссальной: цикл на чистом Python длился около 244 миллисекунд на запуск, тогда как версия NumPy выполнила ту же задачу всего за 1,49 миллисекунды .
Это примерно в 160 раз больше скорости ».
Цель 2: Базовая статистическая база
Ещё одна интересная функция NumPy — это возможность выполнять как базовые, так и сложные статистические вычисления. Это позволяет получить полное представление о том, что происходит в вашем наборе данных. NumPy предлагает такие операции, как:
- np.mean() — для расчета среднего значения
- np.median — среднее значение данных
- np.std() — показывает, насколько сильно ваши числа разбросаны относительно среднего значения
- np.percentile() — сообщает значение, ниже которого находится определенный процент ваших данных.
Теперь, когда нам удалось предоставить альтернативное и эффективное решение для извлечения и выполнения сводок и вычислений на основе их огромного набора данных, мы можем начать экспериментировать с ним.
Нам уже удалось сгенерировать данные для смоделированной температуры. Давайте сделаем то же самое для давления. Вычисление давления — отличный способ продемонстрировать способность NumPy обрабатывать множество массивов в кратчайшие сроки.
Для нашего клиента это также позволяет мне продемонстрировать проверку работоспособности его промышленных систем.
Кроме того, температура и давление часто взаимосвязаны. Резкое падение давления может вызвать скачок температуры, и наоборот. Расчёт базовых линий для обоих показателей позволяет увидеть, меняются ли они вместе или независимо.
# Сгенерировать массив давления (равномерное распределение между 100,0 и 500,0) np.random.seed(43) # Использовать другое начальное число для нового набора данных pressure_data = np.random.uniform(low=100.0, high=500.0, size=1_000_000) print(“Массивы данных готовы.”)
Выход:
Массивы данных готовы.
Хорошо, приступим к расчетам.
print(“n — — Статистика температуры — -”) # 1. Среднее и медианное значение temp_mean = np.mean(temperature_data) temp_median = np.median(temperature_data) # 2. Среднеквадратичное отклонение temp_std = np.std(temperature_data) # 3. Процентили (определяющие 90% нормальный диапазон) temp_p5 = np.percentile(temperature_data, 5) # 5-й процентиль temp_p95 = np.percentile(temperature_data, 95) # 95-й процентиль # Форматирование результатов print(f»Среднее значение»: {temp_mean:.2f}°C») print(f»Медиана»: {temp_median:.2f}°C») print(f»Стандартное отклонение»: {temp_std:.2f}°C») print(f»90% нормальный диапазон: {temp_p5:.2f}°C до {temp_p95:.2f}°C»)
Вот что получилось:
— Статистика температуры — Среднее значение: 44,98 °C Медиана: 44,99 °C Среднеквадратичное отклонение (разброс): 12,00 °C 90% Нормальный диапазон: от 25,24 °C до 64,71 °C
Итак, чтобы объяснить, что вы здесь видите,
Среднее значение (44,98 °C) фактически даёт нам центральную точку, вокруг которой, как ожидается, будет находиться большинство показаний. Это довольно удобно, поскольку нам не нужно просматривать весь большой набор данных. Благодаря этому значению я получил довольно хорошее представление о том, где обычно находятся наши показания температуры.
Медиана (средняя): 44,99 °C практически совпадает со средним значением, если вы заметили. Это говорит об отсутствии резких выбросов, которые бы завышали или занижали среднее значение.
Стандартное отклонение в 12°C означает, что температура существенно отличается от среднего значения. В принципе, некоторые дни значительно жарче или прохладнее других. Более низкое значение (например, 3°C или 4°C) предполагало бы большую постоянство, но 12°C указывает на высокую изменчивость.
Для процентиля это, по сути, означает, что большинство дней температура колеблется между 25°C и 65°C,
Если бы мне пришлось представить это клиенту, я бы мог выразить это так:
В среднем система (или окружающая среда) поддерживает температуру около 45°C , что служит надёжным ориентиром для типичных условий эксплуатации или окружающей среды. Отклонение на 12°C указывает на значительные колебания температуры вокруг среднего значения.
Проще говоря, показания не очень стабильны. Наконец, 90% всех показаний находятся в диапазоне от 25 до 65 °C. Это даёт реалистичное представление о том, что такое «норма», помогая определить приемлемые пороговые значения для срабатывания оповещений или технического обслуживания. Для повышения производительности или надёжности мы могли бы определить причины высоких колебаний (например, внешние источники тепла, схемы вентиляции, нагрузка на систему)».
Давайте также рассчитаем давление.
print(“n — — Статистика давления — -”) # Рассчитаем все 5 показателей давления pressure_stats = { “Среднее”: np.mean(pressure_data), “Медиана”: np.median(pressure_data), “Стандартное отклонение”: np.std(pressure_data), “5th %tile”: np.percentile(pressure_data, 5), “95th %tile”: np.percentile(pressure_data, 95), } для метки, значения в pressure_stats.items(): print(f”{label:<12}: {value:.2f} кПа”)
Чтобы улучшить нашу кодовую базу, я сохраняю все выполненные вычисления в словаре, который называется pressure stats, и просто перебираю пары ключ-значение.
Вот что получилось:
— Статистика давления — Среднее: 300,09 кПа Медиана: 300,04 кПа Среднеквадратичное отклонение: 115,47 кПа 5-й процент: 120,11 кПа 95-й процент: 480,09 кПа
Если бы я представил это клиенту, это выглядело бы примерно так:
« Среднее значение давления составляет около 300 килопаскалей , а медиана — среднее значение — практически совпадает. Это говорит о том, что распределение давления в целом достаточно сбалансировано. Однако стандартное отклонение составляет около 115 кПа , что означает значительный разброс показаний. Другими словами, некоторые показания значительно выше или ниже типичного уровня в 300 кПа.
Если посмотреть на процентили , 90% наших показаний попадают в диапазон от 120 до 480 кПа . Это широкий диапазон, который говорит о нестабильности давления, возможно, колеблющегося между низкими и высокими значениями во время работы. Поэтому, хотя среднее значение выглядит приемлемым, изменчивость может указывать на нестабильность работы системы или воздействие факторов окружающей среды .
Цель 3: Выявление критических аномалий
Одна из моих любимых функций NumPy — это возможность быстро выявлять и отфильтровывать аномалии в наборе данных. Чтобы продемонстрировать это, наш вымышленный клиент, EnviroTech Dynamics, предоставил нам ещё один полезный массив, содержащий коды состояния системы. Он показывает, насколько стабильно работает машина. Это просто диапазон кодов (0–3).
- 0 → Нормально
- 1 → Предупреждение
- 2 → Критический
- 3 → Ошибка датчика
Они получают миллионы показаний в день, и наша задача — найти каждую машину, которая находится в критическом состоянии и перегревается до опасного уровня.
Если бы это делалось вручную или даже с помощью цикла, это заняло бы уйму времени. Именно здесь на помощь приходит булево индексирование (маскирование). Оно позволяет фильтровать огромные наборы данных за миллисекунды, применяя логические условия непосредственно к массивам, без циклов.
Ранее мы сгенерировали данные о температуре и давлении. Давайте сделаем то же самое для кодов состояния.
# Повторное использование 'temperature_data' из более раннего import numpy как np np.random.seed(42) # Для воспроизводимости status_codes = np.random.choice( a=[0, 1, 2, 3], size=len(temperature_data), p=[0.85, 0.10, 0.03, 0.02] # 0=Нормально, 1=Предупреждение, 2=Критически, 3=Автономно ) # Давайте предварительно просмотрим наши данные print(status_codes[:5])
Выход:
[0 2 0 0 0]
Каждому показанию температуры теперь соответствует код состояния. Это позволяет нам точно определить, какие датчики сообщают о проблемах и насколько серьёзны они.
Далее нам понадобится некий порог или критерий аномалии. В большинстве случаев всё, что превышает среднее значение + 3 × стандартное отклонение , считается серьёзным выбросом, то есть таким значением, которое нежелательно для вашей системы. Чтобы вычислить это значение,
temp_mean = np.mean(temperature_data) temp_std = np.std(temperature_data) SEVERITY_THRESHOLD = temp_mean + (3 * temp_std) print(f»Порог серьезного выброса: {SEVERITY_THRESHOLD:.2f}°C»)
Выход:
Пороговое значение резкого выброса: 80,99 °C
Далее мы создадим два фильтра (маски) для выделения данных, соответствующих нашим условиям: один — для показаний, где состояние системы критическое (код 2), и другой — для показаний, где температура превышает пороговое значение.
# Маска 1 — Показания, при которых состояние системы = Критическое (код 2) critic_status_mask = (status_codes == 2) # Маска 2 — Показания, при которых температура превышает пороговое значение high_temp_outlier_mask = (temperature_data > SEVERITY_THRESHOLD) print(f»Показания критического состояния: {critical_status_mask.sum()}») print(f»Выбросы высокой температуры: {high_temp_outlier_mask.sum()}»)
Вот что происходит за кулисами. NumPy создаёт два массива, заполненных значениями True или False. Каждое значение True соответствует показанию, удовлетворяющему условию. True будет представлено как 1, а False — как 0. Быстрое суммирование позволяет подсчитать количество совпадений.
Вот что получилось:
Показатели критического состояния: 30178 Высокотемпературные выбросы: 1333
Давайте объединим обе аномалии перед выводом окончательного результата. Нам нужны показания, которые одновременно являются критическими и слишком высокими. NumPy позволяет фильтровать по нескольким условиям с помощью логических операторов. В данном случае мы будем использовать функцию И, представленную как &.
# Объедините оба условия с логическим И critic_anomaly_mask = crisis_status_mask & high_temp_outlier_mask # Извлеките фактические температуры этих аномалий extraction_anomalies = temperature_data[critical_anomaly_mask] anomaly_count = crisis_anomaly_mask.sum() print(“n — — Окончательные результаты — -”) print(f”Всего критических аномалий: {anomaly_count}”) print(f”Выборочные температуры: {extracted_anomalies[:5]}”)
Выход:
— Окончательные результаты — Общее количество критических аномалий: 34 Температуры образцов: [81,9465697 81,11047892 82,23841531 86,65859372 81,146086 ]
Давайте представим это клиенту.
«Проанализировав миллион показаний температуры, наша система обнаружила 34 критических отклонения — показания, которые были помечены машиной как «критический статус» и превысили пороговое значение высокой температуры.
Первые несколько показаний находятся в диапазоне от 81 до 86 °C , что значительно превышает наш нормальный рабочий диапазон около 45 °C. Это говорит о том, что небольшое количество датчиков регистрируют опасные скачки температуры , возможно, указывающие на перегрев или неисправность датчика.
Другими словами, хотя 99,99% наших данных выглядят стабильными, эти 34 точки представляют собой точные места , на которых нам следует сосредоточить техническое обслуживание или провести дальнейшее исследование».
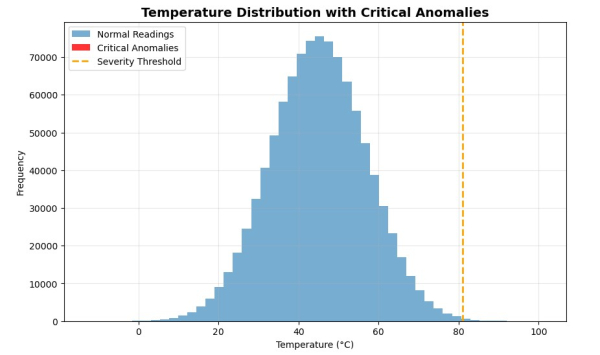
Давайте быстро визуализируем это с помощью matplotlib

Когда я впервые отобразил результаты на графике, я ожидал увидеть группу красных столбцов, отражающих критические отклонения. Но их не было.
Сначала я подумал, что что-то не так, но потом до меня дошло. Из миллиона показаний только 34 были критическими. В этом и заключается прелесть булевой маски: она обнаруживает то, что не видят глаза. Даже когда аномалии скрываются глубоко среди миллионов нормальных значений, NumPy выявляет их за миллисекунды.
Задача 4: Очистка и импутация данных
Наконец, NumPy позволяет избавиться от несоответствий и бессмысленных данных. Возможно, вы сталкивались с концепцией очистки данных в анализе данных. В Python NumPy и Pandas часто используются для упрощения этой задачи.
Для демонстрации этого наши status_codes содержат записи со значением 3 (неисправен/отсутствует). Использование этих неверных показаний температуры в нашем общем анализе исказит результаты. Решение заключается в замене неверных показаний статистически обоснованным оценочным значением.
Первый шаг — определить, какое значение следует использовать для замены некорректных данных. Медиана — всегда хороший выбор, поскольку, в отличие от среднего значения, она меньше подвержена влиянию крайних значений.
# ЗАДАЧА: Определить маску для «допустимых» данных (где status_codes НЕ равен 3 — неверные/отсутствуют). valid_data_mask = (status_codes != 3) # ЗАДАЧА: Рассчитать медианную температуру ТОЛЬКО для допустимых точек данных. Это наше значение вменения. valid_median_temp = np.median(temperature_data[valid_data_mask]) print(f»Медиана всех допустимых показаний: {valid_median_temp:.2f}°C»)
Выход:
Медиана всех достоверных показаний: 44,99°C
Теперь выполним условную замену, используя мощную функцию np.where(). Вот типичная структура этой функции.
np.where(Условие, Значение_если_Истина, Значение_если_Ложь)
В нашем случае:
- Состояние: Код статуса 3 (Неисправен/Отсутствует)?
- Значение True: используйте наше вычисленное значение valid_median_temp.
- Значение, если «Ложь»: сохранить исходное показание температуры.
# ЗАДАЧА: Реализовать условную замену с помощью np.where(). cleaning_temperature_data = np.where( status_codes == 3, # УСЛОВИЕ: Показания неверны? valid_median_temp, # ЗНАЧЕНИЕ_ЕСЛИ_ИСТИНА: Заменить вычисленным медианным значением. temperature_data # ЗНАЧЕНИЕ_ЕСЛИ_ЛОЖЬ: Сохранить исходное значение температуры. ) # ЗАДАЧА: Вывести общее количество замененных значений. imputed_count = (status_codes == 3).sum() print(f»Всего неверных показаний imputed: {imputed_count}»)
Выход:
Общее количество ошибочных показаний: 20102
Я не ожидал, что пропущенных значений будет так много. Вероятно, это как-то повлияло на наши данные выше. Хорошо, что нам удалось их восстановить за считанные секунды.
Теперь давайте проверим исправление, проверив медиану как для исходных, так и для очищенных данных.
# ЗАДАЧА: Вывести изменение общего среднего значения или медианы, чтобы показать влияние очистки. print(f»nИсходная медиана: {np.median(temperature_data):.2f}°C») print(f»Очищенная медиана: {np.median(cleaned_temperature_data):.2f}°C»)
Выход:
Исходная медиана: 44,99 °C Очищенная медиана: 44,99 °C
В этом случае даже после очистки более 20 000 ошибочных записей медианная температура оставалась стабильной на уровне 44,99 °C, что свидетельствует о том, что набор данных статистически надежен и сбалансирован.
Давайте представим это клиенту:
Из миллиона показаний температуры 20 102 были отмечены как ошибочные (код статуса = 3). Вместо того, чтобы удалить эти ошибочные записи, мы заменили их медианным значением температуры (≈ 45 °C) — стандартный подход к очистке данных, который поддерживает согласованность набора данных, не искажая тренд.
Интересно, что медианная температура осталась неизменной (44,99 °C) до и после очистки. Это хороший знак: это означает, что ошибочные показания не исказили набор данных, а замена не повлияла на общее распределение данных.
Заключение
И вот мы начинаем! Мы инициировали этот проект, чтобы решить критически важную проблему для EnviroTech Dynamics : потребность в более быстром анализе данных без циклов. Мощь массивов NumPy и векторизации позволила нам решить эту проблему и подготовить аналитический конвейер к будущему.
NumPy ndarray — это бесшумный движок всей экосистемы Python для анализа данных. Все крупные библиотеки, такие как Pandas , scikit-learn , TensorFlow и PyTorch, используют массивы NumPy в своей основе для быстрых численных вычислений.
Освоив NumPy, вы создали мощный аналитический фундамент. Следующий логичный шаг для меня — перейти от отдельных массивов к структурированному анализу с помощью библиотеки Pandas, которая организует массивы NumPy в таблицы (DataFrames) для ещё более удобной маркировки и обработки данных.
Спасибо за прочтение! Свяжитесь со мной:
Середина
Твиттер
Ютуб
Источник: towardsdatascience.com

 или 4")