Если вы обладаете уникальными экспертными знаниями в своей области и знаете, как применить их в своих системах искусственного интеллекта, вас будет трудно превзойти.
Делиться

В течение последних трех лет я постоянно возвращаюсь к одному и тому же вопросу: если передовые базовые модели широко доступны, откуда же тогда может взяться устойчивое конкурентное преимущество, обеспечиваемое искусственным интеллектом?
Сегодня я хотел бы подробнее остановиться на контекстной инженерии — дисциплине динамического заполнения контекстного окна модели ИИ информацией, которая максимизирует ее шансы на успех. Контекстная инженерия позволяет кодировать и передавать вашу существующую экспертизу и знания в предметной области системе ИИ, и я считаю это важным компонентом стратегического дифференциации. Если у вас есть уникальная экспертиза в предметной области и вы знаете, как сделать ее применимой в ваших системах ИИ, вас будет трудно превзойти.
В этой статье я кратко изложу компоненты проектирования контекста, а также лучшие практики, которые зарекомендовали себя за последний год. Одним из важнейших факторов успеха является тесное взаимодействие между экспертами в предметной области и инженерами. Эксперты необходимы для кодирования знаний и рабочих процессов в предметной области, в то время как инженеры отвечают за представление знаний, организацию и динамическое построение контекста. Далее я постараюсь объяснить проектирование контекста таким образом, чтобы это было полезно как экспертам в предметной области, так и инженерам. Поэтому мы не будем углубляться в технические темы, такие как компактирование и сжатие контекста.
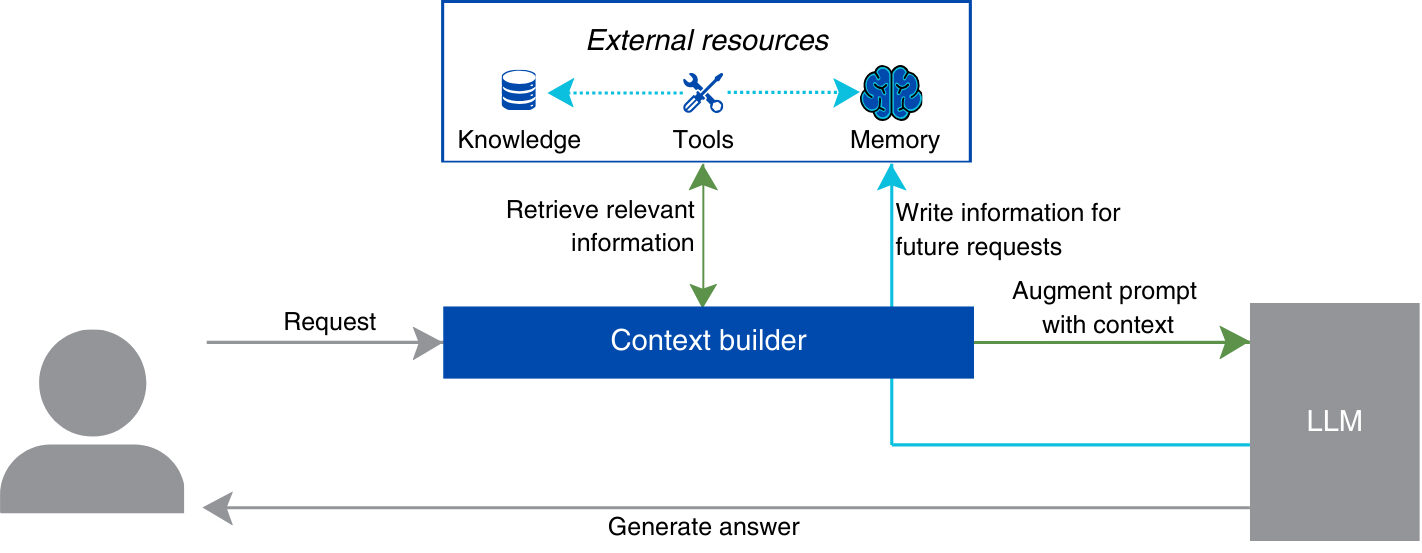
Предположим, что наша система искусственного интеллекта имеет абстрактный компонент — построитель контекста, — который формирует наиболее эффективный контекст для каждого взаимодействия с пользователем. Построитель контекста находится между запросом пользователя и языковой моделью, выполняющей этот запрос. Его можно рассматривать как интеллектуальную функцию, которая принимает текущий запрос пользователя, извлекает наиболее релевантную информацию из внешних ресурсов и формирует для него оптимальный контекст. После того, как модель выдает результат, построитель контекста может также сохранять новую информацию, такую как правки пользователя и отзывы. Таким образом, система накапливает опыт и обеспечивает непрерывность взаимодействия с течением времени.

В концептуальном плане, строитель контекста должен управлять тремя различными ресурсами:
- Знание предметной области и конкретных задач превращает универсальную систему искусственного интеллекта в эксперта в этой области.
- Инструменты позволяют агенту действовать в реальном мире.
- Память позволяет агенту персонализировать свои действия и учиться на основе отзывов пользователей.
По мере развития системы вы также обнаружите все больше интересных взаимозависимостей между этими тремя компонентами, которые можно устранить с помощью надлежащей координации.
Давайте рассмотрим эти компоненты по отдельности. Мы проиллюстрируем их на примере системы искусственного интеллекта, которая поддерживает задачи RevOps, такие как еженедельные прогнозы.
Знание
Приступая к проектированию системы, вы консультируетесь с руководителем отдела RevOps, чтобы понять, как сейчас осуществляется прогнозирование. Она объясняет: «Когда я готовлю прогноз, я смотрю не только на воронку продаж. Мне также необходимо понимать, как аналогичные сделки работали в прошлом, какие сегменты демонстрируют тенденцию к росту или снижению, увеличивается ли скидка и где мы исторически переоценивали конверсию. Иногда эта информация уже известна, но часто мне приходится искать ее в наших системах и общаться с продавцами. В любом случае, снимок CRM сам по себе является лишь базовым показателем».
Магистратура по управлению корпоративными продажами (LLM) предполагает наличие обширных общих знаний, полученных в ходе предварительной подготовки. Они понимают, что такое воронка продаж, и знают распространенные методы прогнозирования. Однако им неизвестна специфика вашей компании, например:
- Исторические показатели закрытия сделок по этапам и сегментам
- Средние показатели времени на этапе
- Сезонные закономерности в сопоставимых кварталах
- Ценовая политика и политика скидок
- Текущие целевые показатели выручки
- Определения этапов конвейера и вероятностной логики.
Без этой информации пользователям придётся вручную корректировать результаты работы системы. Они будут объяснять, что в четвёртом квартале чаще срываются корпоративные сделки, корректировать предположения о расширении и напоминать модели о задержках в утверждении скидок. Вскоре они могут прийти к выводу, что система искусственного интеллекта интересна сама по себе, но не подходит для их повседневной работы.
Рассмотрим шаблоны, позволяющие интегрировать модель ИИ со знаниями, специфичными для конкретной компании. Начнем с RAG (Retrieval-Augmented Generation) в качестве базового варианта и будем постепенно переходить к более структурированным представлениям знаний.
ТРЯПКА
В методе генерации информации с расширенными возможностями поиска (Retrieval-Augmented Generation, RAG) знания, специфичные для компании и предметной области, разбиваются на управляемые фрагменты (обзор методов разбиения на фрагменты см. в этой статье). Каждый фрагмент преобразуется в текстовое векторное представление и сохраняется в базе данных. Текстовые векторные представления представляют смысл текста в виде числового вектора. Семантически похожие тексты являются соседями в пространстве векторных представлений, поэтому система может извлекать «релевантную» информацию посредством поиска по сходству.
Теперь, когда поступает запрос на прогнозирование, система извлекает наиболее похожие фрагменты текста и включает их в подсказку:

Концептуально это элегантно, и каждая молодая команда разработчиков B2B-ИИ, уважающая себя, уже реализует инициативу RAG. Однако большинство прототипов и MVP испытывают трудности с внедрением. Наивная версия RAG делает несколько чрезмерно упрощающих предположений о природе корпоративных знаний. Она использует изолированные фрагменты текста в качестве источника истины. Она предполагает, что документы внутренне непротиворечивы. Она также сводит сложную эмпирическую концепцию релевантности к сходству, что гораздо удобнее с вычислительной точки зрения.
В действительности, текстовые данные в необработанном виде создают запутанный контекст для моделей ИИ. Документы устаревают, политики меняются, метрики корректируются, а бизнес-логика может быть задокументирована по-разному в разных командах. Если вы хотите получить результаты прогнозирования, которым руководство сможет доверять, вам необходимо более целенаправленное представление знаний.
Представление знаний с помощью графиков
Многие команды просто сбрасывают имеющиеся данные во встроенную базу данных, не зная, что в ней находится. Это верный путь к провалу. Необходимо знать семантику данных . Ваше представление знаний должно отражать основные объекты, процессы и KPI бизнеса таким образом, чтобы оно было понятно как людям, так и машинам. Для людей это обеспечивает удобство сопровождения и управления. Для систем искусственного интеллекта это обеспечивает возможность извлечения и правильного использования. Модель должна не только получать доступ к информации, но и понимать, какой источник подходит для какой задачи.
Графы представляют собой перспективный подход, поскольку позволяют структурировать знания, сохраняя при этом гибкость. Вместо того чтобы рассматривать знания как архив слабо связанных документов, вы моделируете основные объекты вашего бизнеса и взаимосвязи между ними.
В зависимости от того, что именно вам нужно закодировать, можно рассмотреть следующие типы графов:
- Таксономии или онтологии, определяющие основные бизнес-объекты — сделки, сегменты, учетные записи, представителей — а также их свойства и взаимосвязи.
- Канонические графы знаний, отражающие более сложные, неиерархические зависимости.
- Контекстные графы, которые фиксируют траектории принятия прошлых решений и позволяют восстанавливать прецеденты.
Графы — мощный инструмент представления данных, а варианты RAG, такие как GraphRAG, предоставляют план их интеграции. Однако графы не растут на деревьях. Для их проектирования необходимы целенаправленные усилия — нужно решить, что именно кодирует граф, как он поддерживается и какие его части доступны модели в данном цикле рассуждений. В идеале, это следует рассматривать не как разовое вложение, а как непрерывный процесс, в рамках которого пользователи-люди взаимодействуют с системой ИИ параллельно со своей повседневной работой. Это позволит наращивать знания системы, вовлекая пользователей и способствуя её внедрению.
Инструменты
Прогнозирование — это не аналитический, а оперативный и интерактивный процесс. Ваш руководитель отдела RevOps объясняет: «Я постоянно переключаюсь между системами и веду диалоги — проверяю CRM, сверяю данные с финансовым отделом, пересчитываю сводные отчеты и связываюсь с представителями, когда что-то кажется не так. Весь процесс интерактивный».
Для поддержки этого рабочего процесса система искусственного интеллекта должна выйти за рамки простого чтения и генерации текста. Она должна уметь взаимодействовать с цифровыми системами, в которых фактически функционирует бизнес. Инструменты предоставляют эту возможность.
Инструменты делают вашу систему управляемой — то есть, способной действовать в реальном мире. В контексте RevOps к таким инструментам могут относиться:
- Получение данных из воронки продаж CRM (вывод открытых возможностей с указанием этапа, суммы, даты закрытия, ответственного лица и категории прогноза)
- Расчет сводного прогноза (применение вероятности, специфичной для каждой компании, и логики переопределения для расчета суммы обязательств, наилучшего сценария и общего объема проектов в портфеле).
- Анализ отклонений и рисков (сравнение текущего прогноза с предыдущими периодами и выявление отклонений, риска концентрации или зависимости от сделок).
- Создание краткого обзора для руководства (преобразование структурированных результатов в готовый к использованию прогнозный текст).
- Триггер оперативного отслеживания (создание задач или уведомлений для сделок высокого риска или устаревших сделок)
Встраивая эти действия в инструменты с помощью жесткого кодирования, вы инкапсулируете бизнес-логику, которую не следует оставлять на угадывание вероятностей. Например, модели больше не нужно аппроксимировать, как вычисляется «коммит» или как разлагается дисперсия — она просто вызывает функцию, которая уже отражает ваши внутренние правила. Это повышает уверенность и надежность вашей системы.
Как называются инструменты
На следующем рисунке показан базовый цикл после интеграции инструментов в вашу систему:

Давайте рассмотрим этот процесс по порядку:
- Пользователь отправляет запрос в LLM, например: «Почему наш корпоративный прогноз снизился по сравнению с предыдущей неделей?» Конструктор контекста добавляет соответствующую информацию (последний снимок воронки продаж, определения прогнозов, предыдущие итоги) и подмножество доступных инструментов.
- LLM определяет, необходим ли тот или иной инструмент. Если задача требует структурированных вычислений, например, разложения на дисперсии, он выбирает соответствующую функцию.
- Выбранный инструмент выполняется извне. Например, функция анализа отклонений запрашивает данные из CRM, вычисляет дельты (новые сделки, просроченные сделки, закрытые сделки, изменения сумм) и возвращает структурированный результат.
- Результат работы инструмента добавляется обратно в контекст.
- Метод LLM генерирует окончательный ответ. Основанный на проверенной вычислительной схеме, он предоставляет структурированное объяснение изменения прогноза.
Таким образом, задача создания бизнес-логики перекладывается на экспертов, которые разрабатывают соответствующие инструменты. Агент искусственного интеллекта управляет заранее определенной логикой и анализирует полученные результаты.
Выбор правильных инструментов
Со временем ваш набор инструментов будет расти. Помимо извлечения данных из CRM и сводных прогнозов, вы можете внедрить оценку риска продления контрактов, моделирование расширения, картирование территорий, отслеживание квот и многое другое. Внедрение всего этого в каждый запрос увеличивает сложность и снижает вероятность выбора правильного инструмента.
За управление этой сложностью отвечает конструктор контекста. Вместо того чтобы предоставлять доступ ко всей экосистеме инструментов, он выбирает подмножество в зависимости от поставленной задачи. Запрос типа «Какова наша вероятная выручка на конец квартала?» может потребовать получения данных из CRM-системы и логики агрегирования, в то время как запрос «Почему прогноз по всей компании снизился по сравнению с предыдущей неделей?» может потребовать декомпозиции отклонений и анализа движения по этапам.
Таким образом, инструменты становятся частью динамического контекста. Для обеспечения надежной работы каждого инструмента необходима понятная, удобная для ИИ документация:
- Что это делает
- Когда его следует использовать
- Что представляют собой его входные данные
- Как следует интерпретировать его результаты
Данная документация представляет собой договор между моделью и вашей операционной логикой.
Стандартизация интерфейса между программами обучения на уровне магистратуры и инструментами.
Когда вы подключаете модель ИИ к предопределенным инструментам, вы объединяете два совершенно разных мира: вероятностную языковую модель и детерминированную бизнес-логику. Один работает с вероятностями и закономерностями; другой выполняет точные операции, основанные на правилах. Если интерфейс между ними не определен четко, взаимодействие становится ненадежным.
Стандарты, такие как протокол контекста модели (MCP), направлены на формализацию интерфейса. MCP предоставляет структурированный способ описания и вызова внешних возможностей, что делает интеграцию инструментов более согласованной между системами. WebMCP расширяет эту идею, предлагая способы превращения веб-приложений в вызываемые инструменты в рамках рабочих процессов, управляемых искусственным интеллектом.
Эти стандарты важны не только для обеспечения совместимости, но и для управления. Они определяют, какие части вашей операционной логики разрешено выполнять модели и при каких условиях.
Память — ключ к персонализированному, самосовершенствующемуся искусственному интеллекту.
Ваш руководитель отдела RevOps применяет индивидуальный подход к каждому циклу прогнозирования: «Прежде чем окончательно утвердить прогноз, я убеждаюсь, что понимаю, как руководство хочет представить цифры. Я также отслеживаю корректировки, которые мы уже обсуждали на этой неделе, чтобы не возвращаться к тем же предположениям и не повторять одни и те же ошибки».
До сих пор наши запросы не имели состояния. Однако многим приложениям генеративного ИИ необходимы состояние и память. Существует множество различных подходов к формализации памяти агента. В конечном итоге, то, как вы будете создавать и повторно использовать память, — это очень индивидуальное проектное решение.
Для начала определите, какие именно знания, полученные в результате взаимодействия с пользователями, могут быть полезны:

Как показано в этой таблице, тип знаний также влияет на выбор формата хранения. Для более точного определения рассмотрим следующие два вопроса:
- Устойчивость : Как долго должны храниться знания? Представьте текущую сессию как кратковременную память, а информацию, которая сохраняется от одной сессии к другой, как долговременную память.
- Область применения : Кто должен иметь доступ к памяти? В большинстве случаев мы рассматриваем память на уровне пользователя. Однако, особенно в контексте B2B, может быть целесообразно хранить определенные взаимодействия, входные данные и последовательности в базе знаний системы, позволяя другим пользователям также извлекать из нее пользу.

По мере роста объема памяти вы можете все больше согласовывать результаты с тем, как команда фактически работает. Если вы также храните процедурные данные о выполнении и результатах (включая те, которые потребовали корректировок), ваш построитель контекста сможет постепенно улучшать использование памяти с течением времени.
Взаимодействие между тремя компонентами контекста
Для упрощения, до настоящего момента мы четко разделяли три компонента эффективного контекста — знания, инструменты и память. На практике они будут взаимодействовать друг с другом, особенно по мере развития вашей системы:
- Можно разработать инструменты для извлечения знаний из различных источников и создания различных типов воспоминаний.
- Долговременные воспоминания можно записывать в источники знаний и сохранять для последующего извлечения.
- Если пользователь часто повторяет определенную задачу или рабочий процесс, агент может помочь ему оформить это в виде инструмента.
Задача проектирования и управления этими взаимодействиями называется оркестровкой. Фреймворки для агентов, такие как LangChain и DSPy, поддерживают эту задачу, но они не заменяют архитектурное мышление. Для более сложных систем агентов вы можете решить реализовать их самостоятельно. Наконец, как уже говорилось в начале, взаимодействие с людьми — особенно с экспертами в предметной области — имеет решающее значение для повышения интеллекта агента. Это требует образованных и заинтересованных пользователей, надлежащей оценки и пользовательского опыта, который поощряет обратную связь.
Подводя итог
Если вы завтра запускаете агента прогнозирования RevOps, начните с составления карты:
- Какие источники информации существуют и используются для решения этой задачи ( знания )?
- Какие операции и вычисления являются повторяющимися и обязательными ( инструменты )?
- Какие решения в рамках рабочих процессов требуют непрерывности ( памяти )?
В конечном итоге, контекстная инженерия определяет, отражает ли ваша система ИИ то, как на самом деле работает ваш бизнес, или же просто выдает предположения, которые «звучат убедительно» для неспециалистов. Модель взаимозаменяема, но ваш уникальный контекст — нет. Если вы научитесь целенаправленно представлять и управлять им, вы сможете превратить общие возможности ИИ в устойчивое конкурентное преимущество.
Доктор Янна Липенкова. Все материалы от доктора Янны Липенковой.
Источник: towardsdatascience.com