
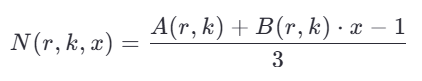
Рассмотрим стандартную 8-битную кодировку (например, ASCII+). Но с одним условием, мы хотим передавать сообщения так, чтобы только адресат мог их расшифровать — без применения традиционных криптографических примитивов, таких как AES или RSA. Есть ли альтернатива? Оказывается, да — можно построить биективное отображение между символами и определённым подмножеством нечётных натуральных чисел, генерируемых по заданному правилу.
Велосипед, но свой…
Обратимся к ранее опубликованной статье «Параметризация нечётных чисел на основе подмножеств вычетов по модулю шесть».
Идея: параметризация через «подмножества» и «подпространства»
Пусть каждому символу сопоставляется тройка параметров (r, k, x), где:
r ∈ {1, 3} — номер «подмножества» (на основе подмножеств вычетов по модулю 6),
k ∈ {1, 2, 3, 4} — номер «подпространства»,
x ∈ [0, 31] — индекс внутри уровня (достаточно для покрытия 256 значений).
Параметры r,k,x — подробно описаны ранее, поэтому здесь используется только их применение.
Для каждой такой тройки параметров мы вычисляем нечётное число по формуле:

где A и B — заранее заданные табличные коэффициенты. Все полученные N — нечётные целые числа.
Таким образом, мы строим отображение символ → число, и в обратную сторону — число → символ, используя свойства последовательности Коллатца.
Реализация
Вот упрощённая реализация такого кодека на Python:
A = { (1, 1): 22, (1, 2): 4, (1, 3): 40, (1, 4): 112, (3, 1): 10, (3, 2): 28, (3, 3): 136, (3, 4): 208 } B = { (1, 1): 36, (1, 2): 72, (1, 3): 144, (1, 4): 288, (3, 1): 36, (3, 2): 72, (3, 3): 144, (3, 4): 288 } def collatz_number(r, k, x): if (r, k) not in A or (r, k) not in B: return -1 a = A[(r, k)] b = B[(r, k)] return (a + b * x — 1) // 3
Затем строим таблицы кодирования/декодирования (с проверкой на наличие ошибок):
char_to_code = {} code_to_char = {} used_numbers = set() index = 0 collision_count = 0 for r in [1, 3]: for k in range(1, 5): for x in range(32): if index >= 256: break number = collatz_number(r, k, x) if number in used_numbers: collision_count += 1 continue ch = chr(index) char_to_code[ch] = (r, k, x, number) code_to_char[number] = ch used_numbers.add(number) index += 1 print(f»Пропущено коллизий: {collision_count}»)
Обратное преобразование реализуется через итеративное применение обратных шагов Коллатца:
def decode(num): steps = 0 while steps < 30: if num in code_to_char: return code_to_char[num] elif num < 5: return ‘?’ if num % 2 == 0: num //= 2 else: num = (num — 1) // 3 steps += 1 return ‘?’
Тестирование
Проверим корректность кодека на случайном сообщении из 1000 символов:
import random random.seed(42) test_message = ».join(chr(random.randint(0, 255)) for _ in range(1000)) encoded = [encode(ch) for ch in test_message] decoded = ».join(decode(n) for n in encoded) assert test_message == decoded print(«Сообщение совпадает с оригиналом:», test_message == decoded)
Результат: полное восстановление данных. Коллизий (повторяющихся чисел) при построении таблицы — нет.
Эффективность и битовая глубина
Хотя числа N могут быть достаточно большими (десятки тысяч и выше), важно понимать: в данном подходе мы не передаём сами числа как есть, а используем их как секретный словарь. В реальном применении передаётся не число, а его компактный индекс (r, k, x), требующий всего 1 + 2 + 5 = 8 бит — ровно как в ASCII+.
Таким образом:
Внешний наблюдатель видит только неструктурированные нечётные числа.
Получатель, зная таблицу A/B и алгоритм декодирования, легко восстанавливает исходный текст.
Без знания параметров A и B восстановление невозможно (по крайней мере, без перебора).
Заключение и возможные применения
Этот метод не является криптографически стойким в классическом смысле (ключи A, B можно подобрать), но он демонстрирует новый способ стеганографического кодирования, где семантика сообщения скрыта в арифметических свойствах чисел.
Возможные направления развития:
Использование более сложных параметрических семейств (с большим числом «подмножеств» или переменной глубиной).
Интеграция с физическим уровнем передачи (например, модуляция несущей частоты по значению N).
Применение в системах, где требуется обфускация данных без шифрования (например, IoT-устройства с ограниченными ресурсами).
Как идея, не ограничиваться указанными подмножествами и пространствами в примере, а использовать полный набор. Но для этого например передовая в конце или начале сообщения 8 бит с номером набора подмножеств и подпространств.
Спасибо за внимание!
Если идея показалась вам любопытной — делитесь в комментариях: можно ли использовать подобные структуры для построения легковесных протоколов обмена.
Источник: habr.com





















