В некоторых случаях необходимо исследовать большие объемы информации и затрачивать на это минимум времени. Например, когда мы не хотим читать большой документ целиком, а нам нужно найти ответы на некоторые вопросы. Конечно, это звучит странно. Ведь, чтобы задать вопрос, нужно знать о чем документ :). Тем не менее, сейчас многие говорят о RAGах. Технология позволяет «говорить» с информацией, которая может храниться в базе, или в огромном текстовом документе. Как правило, речь идет о текстовой информации. Но есть возможность построить RAG на картинках. В этой статье будем говорить именно о такой задаче и легком способе ее решения.
Retriever
Чтобы появилась возможность задавать вопросы документам нужно решить проблему поиска релевантной информации в этих документах. Для этого сначала построим ретривер, который будет нам возвращать картинки, в которых содержится информация из запроса пользователя.
Воспользуемся Google Colab (https://colab.google) Создадим новый блокнотик. Нам понадобятся мощности GPU. Поэтому выбираем в Среде выполнения -> Сменить среду выполнения -> T4. Нажимаем подключиться в верхнем правом углу. Ждем, когда включится GPU и приступаем.
Первое, что нужно будет сделать это установить нужные нам библиотеки. В первой ячейке блокнотика запускаем следующий код:
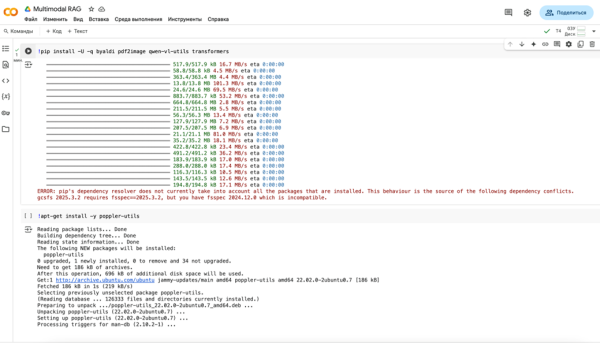
pip install -U -q byaldi pdf2image qwen-vl-utils transformers
Во второй:
!apt-get install -y poppler-utils
Выглядеть это будет так.

Если увидите Errors — не пугайтесь, будет работать и с ними в большинстве случаев.
Дальше мы создаем папку data, в которую будем складывать наши pdf-файлы. В нашем случае будем использовать один файл. Но их может быть сколько угодно.
Запускаем код в следующей ячейке:
import requests import os output_dir = «data» os.makedirs(output_dir, exist_ok=True)
Появилась папка data
В эту папку переносим какой-нибудь pdf-файл. Например, инструкцию для фена.
Теперь самое интересное. В дальнейшем мы будем работать не с текстами, а с изображениями. Преобразуем страницы pdf в картинки. Обратите внимание, что вместо pdf в таком подходе могут быть любые другие документы: Word, Excel или просто сканы записей на салфетках. В нашем случае, будет только pdf , но вы можете дополнить код функциями получения из других форматов документов изображений страниц.
Этот код преобразует каждую страницу pdf-документа в изображение.
import os from pdf2image import convert_from_path def convert_pdfs_to_images(pdf_folder): pdf_files = [f for f in os.listdir(pdf_folder) if f.endswith(«.pdf»)] all_images = {} for doc_id, pdf_file in enumerate(pdf_files): pdf_path = os.path.join(pdf_folder, pdf_file) images = convert_from_path(pdf_path) all_images[doc_id] = images return all_images all_images = convert_pdfs_to_images(«/content/data/»)
После выполнения кода мы получили набор картинок всех страниц документа.
Давайте посмотрим, что получилось. Выполним код.
import matplotlib.pyplot as plt fig, axes = plt.subplots(1, 10, figsize=(15, 10)) for i, ax in enumerate(axes.flat): img = all_images[0][i] ax.imshow(img) ax.axis(«off») plt.tight_layout() plt.show()
Увидим первые 10 страниц из набора.

У нас есть изображения страниц документа. Теперь мы получим эмбеддинг этих картинок, т.е. векторное хранилище с содержанием изображений, чтобы в дальнейшем можно было производить в нем поиск. Для этого нам потребуется специальная эмбеддинговая модель. Будем использовать colpali-v1.3, пожалуй, одной из лучших моделей.
Запустим код для запуска этой модели.
from byaldi import RAGMultiModalModel docs_retrieval_model = RAGMultiModalModel.from_pretrained(«vidore/colpali-v1.3»)
Далее, создадим ретривер, т.е. механизм поиска картинок на основе текстового запроса пользователя.
docs_retrieval_model.index( input_path=»data/», index_name=»image_index», store_collection_with_index=False, overwrite=True )
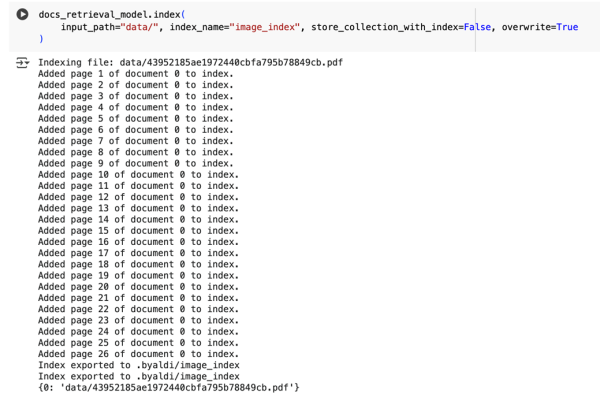
После выполнения кода будет построен Индекс, и мы получим возможность делать поиск по изображениям.
Давайте попробуем задать вопрос и посмотрим, что нам вернет ретривер. Мы ожидаем, что он отдаст самые релевантные изображения, в которых содержится ответ.
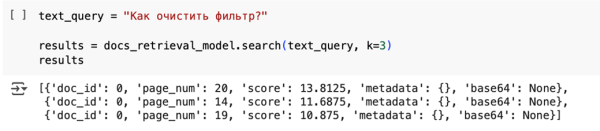
text_query = «Как очистить фильтр?» results = docs_retrieval_model.search(text_query, k=3) results
Мы увидим, что ретривер вернул нам 3 наиболее (с его точки зрения) подходящих картинки. Это 20, 14 и 19 страницы pdf-документа, при этом, наиболее подходящая 20-я страница, т.к. у нее самый большой вес (13.8125)
Результаты выдачи упакуем в список для дальнейшей работы, и чтобы получить возможность их посмотреть.
def get_grouped_images(results, all_images): grouped_images = [] for result in results: doc_id = result[«doc_id»] page_num = result[«page_num»] grouped_images.append( all_images[doc_id][page_num — 1] ) # page_num are 1-indexed, while doc_ids are 0-indexed. Source https://github.com/AnswerDotAI/byaldi?tab=readme-ov-file#searching return grouped_images grouped_images = get_grouped_images(results, all_images)

Чтобы посмотреть результаты, запустим следующий код:
import matplotlib.pyplot as plt fig, axes = plt.subplots(1, 3, figsize=(15, 10)) for i, ax in enumerate(axes.flat): img = grouped_images[i] ax.imshow(img) ax.axis(«off») plt.tight_layout() plt.show()
Видим, что на вопрос «Как очистить фильтр?» ретривер вернул картинки, в которых действительно содержится релевантная информация.
Не в каждой картинке может содержаться нужная нам информация, но это проблема всех ретриверов. Где-то они бывают неточными. Но эту проблему решают не одной картинкой в выдаче, а несколькими, в надежде на то, что в этом случае, хотя бы на одной-двух картинках будет релевантная информация. Разбираться в том, на какой картинке самая точная информация будет уже другая модель.
RAG
Другой модели мы дадим на вход картинки, и уже она будет решать, что и где надо искать уже в каждой из найденных картинок, чтобы максимально точно ответить на наш вопрос. Дальше речь будет идти о RAG (Retrieval Augmented Generation), это, как раз, тот случай, когда к ретриверу прикручивают еще одну модель. А когда речь идет о картинках, то нам потребуется особенная модель, которая умеет «видеть».
Этой моделью будет Qwen2-VL-2B-Instruct. Она маленькая. И она не способна на многое. Но бОльшую модель мы в среде Colab не можем себе позволить, т.к. нам просто не хватит размера памяти GPU, которым готова бесплатно делиться с нами Google.
from transformers import Qwen2VLForConditionalGeneration, Qwen2VLProcessor from qwen_vl_utils import process_vision_info import torch vl_model = Qwen2VLForConditionalGeneration.from_pretrained( «Qwen/Qwen2-VL-2B-Instruct», torch_dtype=torch.bfloat16, ) vl_model.cuda().eval()
Выполним следующий код:
min_pixels = 224 * 224 max_pixels = 500 * 500 vl_model_processor = Qwen2VLProcessor.from_pretrained( «Qwen/Qwen2-VL-2B-Instruct», min_pixels=min_pixels, max_pixels=max_pixels )
Обратите внимание, в переменной max_pixels устанавливается максимальное разрешение картинок. Сейчас оно оптимально 500 * 500. Если поставить бОльшие значения, то наша система «упадет». Не хватит бесплатной памяти GPU. И к слову, если что-то пойдет не так, и система все-таки упадет, не стоит расстраиваться. Такое случается сплошь и рядом. Нужно в верхнем правом углу, где T4, выбрать <Отключиться от среды выполнения и удалить ее> и пройти все шаги сначала. У бесплатного, есть свои ограничения…
Мы практически все сделали и близки к завершению. Объединим предыдущий код в одну функцию.
def answer_with_multimodal_rag( vl_model, docs_retrieval_model, vl_model_processor, grouped_images, text_query, top_k, max_new_tokens ): results = docs_retrieval_model.search(text_query, k=top_k) grouped_images = get_grouped_images(results, all_images) chat_template = [ { «role»: «user», «content»: [{«type»: «image», «image»: image} for image in grouped_images] + [{«type»: «text», «text»: text_query}], } ] # Prepare the inputs text = vl_model_processor.apply_chat_template(chat_template, tokenize=False, add_generation_prompt=True) image_inputs, video_inputs = process_vision_info(chat_template) inputs = vl_model_processor( text=[text], images=image_inputs, padding=True, return_tensors=»pt», ) inputs = inputs.to(«cuda») # Generate text from the vl_model generated_ids = vl_model.generate(**inputs, max_new_tokens=max_new_tokens) generated_ids_trimmed = [out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)] # Decode the generated text output_text = vl_model_processor.batch_decode( generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False ) return output_text, grouped_images
Теперь мы готовы задавать вопросы и ждем, что получим релевантные ответы. Спросим: «На какие ошибки указывает индикация?» Этот вопрос будем задавать в значении переменной text_query.
text_query = «На какие ошибки указывает индикация?» output_text, grouped_images = answer_with_multimodal_rag( vl_model=vl_model, docs_retrieval_model=docs_retrieval_model, vl_model_processor=vl_model_processor, grouped_images=grouped_images, text_query=text_query, top_k=3, max_new_tokens=500, ) print(output_text[0]) fig, axes = plt.subplots(1, 3, figsize=(15, 10)) for i, ax in enumerate(axes.flat): img = grouped_images[i] ax.imshow(img) ax.axis(«off») plt.tight_layout() plt.show()
Получаем ответ и картинки для контроля.

Ретривер нашел по запросу релевантные (на его взгляд) картинки. Отдал их модели с «глазками», чтобы она посмотрела на эти картинки и ответила на вопрос пользователя. Как видно из примера, наша система неплохо справилась. Это не значит, что она идеальна. Она далека от этого, но вполне подходит для демонстрации технологии «RAG на картинках».
ИИ это не так сложно, как может показаться. Пробуйте, экспериментируйте и все обязательно получится.
Источник: habr.com