
У данных Google Trends есть фундаментальное свойство, которое делает их очень уязвимыми для неправильного использования.
Делиться

Google Trends. Какой же это подарок обществу! Если бы не Google Trends, как бы мы узнали, что большее количество фильмов Disney, вышедших в 2000-х годах, привело к меньшему числу разводов в Великобритании? Или что употребление Coca-Cola — это неизвестное средство от царапин, полученных от кошек?
Подождите, я опять путаю корреляцию и причинно-следственную связь?
Если вы предпочитаете смотреть, а не читать, вы можете сделать это прямо здесь:
Google Trends — один из наиболее широко используемых инструментов для анализа поведения человека в больших масштабах. Его используют журналисты, специалисты по анализу данных, на его основе строятся целые научные работы. Но у данных Google Trends есть фундаментальное свойство, которое делает их очень легко неправильно используемыми, особенно если вы работаете с временными рядами или пытаетесь построить модели, и большинство людей даже не осознают, что делают это.
Все диаграммы и скриншоты созданы автором, если не указано иное.
Проблема с данными Google Trends
Google на самом деле не публикует данные об объеме поисковых запросов . Эта информация приносит им огромные деньги, и они ни за что не стали бы открывать ее для монетизации другими. Но они предоставляют нам возможность увидеть временной ряд, понять изменения в поисковых запросах людей по определенному термину, и делают они это, предоставляя нам нормализованный набор данных .
На первый взгляд, это не кажется проблемой, пока вы не попробуете применить это в машинном обучении. Потому что, чтобы научить машину чему-либо, нам нужно предоставить ей много данных.
Изначально я хотел взять пятилетний временной интервал, но сразу же столкнулся с проблемой: чем больше временной интервал, тем менее детализированными становятся данные. Я не смог получить ежедневные данные за пять лет, и хотя потом подумал: «Просто возьму максимально возможный период, за который можно получить ежедневные данные, и сдвину этот интервал», это тоже оказалось проблемой. Потому что именно здесь я открыл для себя истинный ужас нормализации :
Какой бы период времени я ни использовал или какой бы отдельный поисковый запрос ни привёл, точка данных с наибольшим количеством поисковых запросов немедленно устанавливается на значение 100. Это означает, что значение числа 100 меняется с каждым используемым мной окном.
Весь этот пост существует именно по этой причине.
Основы работы с Google Trends
Я не знаю, пользовались ли вы раньше Google Trends, но если нет, я сейчас вам всё объясню, чтобы мы могли перейти к сути проблемы.
Итак, я собираюсь ввести в поиск слово «мотивация», и по умолчанию будет выбрана Великобритания, потому что я оттуда, и за последние сутки у нас есть прекрасный график, который показывает, как часто люди искали слово «мотивация» за последние 24 часа.

Мне это нравится, потому что очень наглядно видно, что люди в основном ищут мотивацию в течение рабочего дня, никто не ищет её, когда большая часть страны спит, и, конечно же, есть пара детей, которым нужна поддержка для выполнения домашнего задания. У меня нет объяснения ночным поискам, но я бы предположил, что это люди, которые не готовы завтра возвращаться на работу.
Это, конечно, замечательно, но хотя восьмиминутные интервалы за 24 часа дают нам целых 180 точек данных, большинство из них на самом деле равны нулю, и я не знаю, были ли последние 24 часа крайне демотивирующими по сравнению с остальной частью года, или же сегодняшний день представляет собой самый высокий вклад в ВВП за год, поэтому я немного увеличу временной интервал .
Как только мы переходим к неделе, первое, что бросается в глаза, — это гораздо меньшая детализация данных. У нас есть данные за неделю, но теперь они только почасовые, и у меня по-прежнему остается та же основная проблема — непонимание того , насколько репрезентативна эта неделя.
Я могу продолжать расширять горизонты. 30 дней, 90 дней. На каждом этапе мы теряем детализацию и получаем гораздо меньше данных, чем за 24 часа. Если я собираюсь построить настоящую модель, этого будет недостаточно. Мне нужно масштабно подойти к делу.
А когда я выберу пять лет, мы столкнёмся с проблемой, которая и послужила поводом для создания этого видео (простите за каламбур, он получился непреднамеренным): я не могу получить ежедневные данные. И ещё, почему сегодня не 100?

В этом и заключается настоящая проблема с данными Google Trends.
Как я уже упоминал ранее, данные Google Trends нормализованы. Это означает, что независимо от используемого периода времени или отдельного поискового запроса, точка данных с наибольшим количеством запросов сразу же принимает значение 100. Все остальные точки масштабируются соответствующим образом. Если 1 апреля количество запросов было вдвое меньше максимального, то показатель Google Trends для 1 апреля составит 50.
Давайте рассмотрим пример, чтобы проиллюстрировать этот момент. Возьмем май и июнь 2025 года, оба месяца по 30 или 31 дню, то есть у нас есть ежедневные данные, но мы теряем их после 90 дней. Если я посмотрю на май, вы увидите, что мы достигли 100 запросов 13-го числа, а в июне — 10-го. Значит ли это, что поиск по теме мотивации был одинаковым по частоте 10 июня и 13 мая?


Если я сейчас уменьшу масштаб графика, чтобы на одном графике были май и июнь, сразу станет ясно, что это не так. Если включить оба месяца, то видно, что поисковые запросы по теме мотивации имели показатель Google Trends 83 10 июня, что означает, что в процентном отношении к общему количеству запросов в Великобритании, это составляло 81% от доли запросов 13 мая. Если бы мы не уменьшили масштаб, мы бы этого не узнали .

Однако не всё потеряно, мы получили немало полезной информации из этого эксперимента, поскольку знаем, что можем увидеть относительную разницу между двумя точками данных, если они обе включены в один график. Так, если мы загрузим данные за май и июнь отдельно, зная, что 10 июня составляет 81% от 13 мая, мы сможем соответствующим образом масштабировать данные за июнь, и они станут сопоставимыми .
Вот что я и решил сделать. Я возьму данные Google Trends с однодневным пересечением в каждом временном окне: с 1 января по 31 марта, а затем с 31 марта по 31 июля. Затем я смогу использовать 31 марта в обоих наборах данных, чтобы масштабировать второй набор и сделать его сопоставимым с первым.
Но хотя это и близко к тому, что мы можем использовать, есть еще одна проблема , о которой я должен вам сообщить.
Google Trends: ещё один слой случайности
Таким образом, когда речь заходит о данных Google Trends, Google на самом деле не отслеживает каждый поисковый запрос. Это было бы настоящим вычислительным кошмаром. Вместо этого Google использует методы выборки , чтобы создать представление об объемах поисковых запросов.
Это означает, что, хотя выборка, вероятно, очень хорошо сформирована (в конце концов, это Google), каждый день будет иметь некоторые естественные случайные колебания . Если бы 31 марта случайно оказался днем, когда выборка Google оказалась бы необычно высокой или низкой по сравнению с реальным миром, наш метод перекрытия внес бы ошибку во весь наш набор данных.
Помимо этого, нам также необходимо учитывать округление . Google Trends округляет все числа до ближайшего целого. Нет 50,5, нет 50 или нет 51. Это может показаться незначительной деталью, но на самом деле это может стать большой проблемой. Позвольте мне показать вам почему.
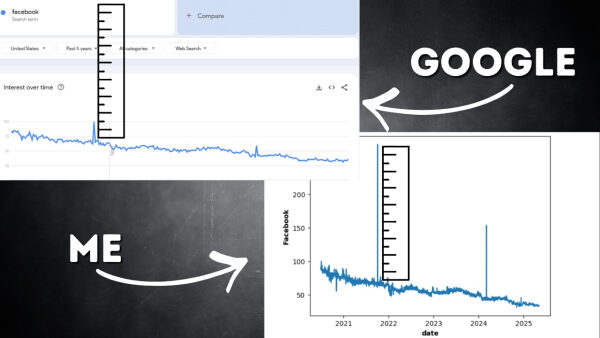
4 октября 2021 года произошёл резкий всплеск поисковых запросов по Facebook. Этот резкий всплеск масштабируется до 100, и в результате все остальные показатели за этот период оказываются гораздо ближе к нулю. При округлении до ближайшего целого числа эта крошечная погрешность в 0,5 внезапно превращается в огромную пропорциональную погрешность, когда число равно всего лишь 1 или 2. Это означает, что наше решение должно быть достаточно устойчивым, чтобы справляться не только с масштабированием, но и с шумом.
Итак, как же решить эту проблему? Мы знаем, что в среднем выборки будут репрезентативными, поэтому давайте просто возьмем выборку большего размера . Если мы используем большее окно для получения перекрытия, случайные колебания и ошибки округления будут оказывать меньшее влияние.
Итак, вот наш окончательный план. Я знаю, что могу получить ежедневные данные за период до 90 дней. Я собираюсь загрузить скользящее окно из 90-дневных периодов, но я убежусь, что каждое окно перекрывается с предыдущим на целый месяц. Таким образом, наше перекрытие будет не просто одним потенциально шумным днем, а стабильным месячным ориентиром , который мы сможем использовать для более точного масштабирования данных.
Итак, похоже, у нас есть план. У меня есть некоторые опасения, главным образом, что при большом количестве партий будут накапливаться ошибки, и это может привести к тому, что цифры резко взлетят. Но чтобы увидеть, как это покажет себя на реальных данных , нам нужно это сделать . Вот один из вариантов, который я составил ранее.
Написание кода для анализа трендов Google
После того, как я записал все, что мы обсуждали, в виде кода и, немного повеселившись, меня временно забанили в Google Trends за сбор слишком большого количества данных, я составил несколько графиков. Моя первая реакция, когда я это увидел, была: «О нет, это взорвалось».

На графике ниже показаны результаты моих пятилетних поисковых запросов по Facebook. Вы увидите довольно устойчивую тенденцию к снижению, но выделяются два пика. Первый из них — это резкий скачок 4 октября 2021 года, о котором мы упоминали ранее.

Первой моей мыслью было проверить эти всплески . Я, без шуток, погуглил и обнаружил масштабные сбои в работе Meta в тот день. Я проанализировал данные по Instagram и WhatsApp за тот же период и увидел похожие всплески. Так что я знал, что всплеск был реальным, но у меня всё ещё оставался вопрос: не слишком ли он велик?
Когда я сравнил свой временной ряд с графиком Google Trends, у меня упало сердце. Мои пики были огромными по сравнению с ним. Я начал думать, как с этим справиться. Стоит ли ограничить максимальное значение пика? Это казалось произвольным и привело бы к потере информации об относительных размерах пиков. Стоит ли применить произвольный масштабирующий коэффициент? Опять же, это казалось просто предположением .

Так продолжалось до тех пор, пока меня не осенила идея. Помните, Google Trends предоставляет нам еженедельные данные за этот период, и именно поэтому мы это делаем. А что если я усредню свои данные за эту неделю, чтобы сравнить их с еженедельным значением Google?
Здесь я с огромным облегчением вздохнул. На той неделе был самый большой скачок в Google Trends, поэтому я установил значение на 100. Когда я усреднил свои данные за ту же неделю, я получил 102,8 . Невероятно близко к Google Trends. Мы также заканчиваем примерно на том же месте. Это означает, что накопившиеся ошибки моего метода масштабирования не испортили мои данные. У меня есть что-то, что выглядит и ведет себя точно так же, как данные Google Trends !
Итак, теперь у нас есть надежная методология для создания чистых, сопоставимых ежедневных временных рядов для любого поискового запроса. Это замечательно. Но что, если мы действительно хотим использовать их для чего-то полезного, например, для сравнения поисковых запросов по всему миру ?
Потому что, хотя Google Trends позволяет сравнивать несколько поисковых запросов, он не позволяет напрямую сравнивать данные по нескольким странам . Таким образом, я могу получить набор данных о мотивации для каждой страны, используя метод, который мы сегодня обсуждали, но как сделать их сопоставимыми? Facebook — часть решения.
Но это решение станет темой для отдельной статьи в блоге, в которой мы создадим «корзину товаров», чтобы сравнить страны и посмотреть, как именно Facebook вписывается во всё это.
Сегодня мы начали с вопроса о том, можем ли мы смоделировать национальную мотивацию, и, пытаясь это сделать, сразу же столкнулись с препятствием. Потому что ежедневные данные Google Trends вводят в заблуждение. Не из-за ошибки, а из-за самой их структуры . Мы нашли способ решить эту проблему, но в жизни специалиста по анализу данных всегда есть новые трудности, подстерегающие на каждом шагу.
Источник: towardsdatascience.com





















