
DS-STAR — это передовой агент для обработки данных, универсальность которого демонстрируется его способностью автоматизировать целый ряд задач — от статистического анализа до визуализации и обработки данных — для различных типов данных, что в конечном итоге приводит к высоким результатам в известном бенчмарке DABStep.
Быстрые ссылки
- Бумага
- Делиться
Наука о данных — это область, посвященная преобразованию необработанных данных в значимые, практически применимые выводы, играющая важную роль в решении реальных задач. Предприятия часто полагаются на данные для принятия ключевых стратегических решений. Однако процесс обработки данных часто сложен и требует высокого уровня экспертных знаний в таких областях, как информатика и статистика. Этот рабочий процесс включает в себя множество трудоемких действий, от интерпретации различных документов до выполнения сложной обработки данных и статистического анализа.
Для оптимизации этого сложного рабочего процесса в недавних исследованиях основное внимание уделялось использованию готовых больших языковых моделей (LLM) для создания автономных агентов в области анализа данных. Цель этих агентов — преобразовывать вопросы на естественном языке в исполняемый код для выполнения желаемой задачи. Однако, несмотря на значительный прогресс, у современных агентов в области анализа данных есть ряд ограничений, препятствующих их практическому применению. Основная проблема заключается в их сильной зависимости от хорошо структурированных данных, таких как CSV-файлы в реляционных базах данных. Эта ограниченная направленность игнорирует ценную информацию, содержащуюся в разнообразных и гетерогенных форматах данных, таких как JSON, неструктурированный текст и файлы Markdown, которые распространены в реальных приложениях. Другая проблема заключается в том, что многие задачи анализа данных являются открытыми и не имеют эталонных меток, что затрудняет проверку правильности рассуждений агента.

Агенты обработки данных отвечают на запросы пользователей, генерируя код, работающий с различными форматами данных. После выполнения кода агент предоставляет окончательное решение, которое может представлять собой обученную модель, обработанную базу данных, визуализацию или ответ в текстовом формате.
С этой целью мы представляем DS-STAR, нового агента, разработанного для решения задач в области анализа данных. DS-STAR внедряет три ключевых нововведения: (1) модуль анализа файлов данных, который автоматически извлекает контекст из различных форматов данных, включая неструктурированные; (2) этап проверки, на котором эксперт на основе LLM оценивает достаточность плана на каждом шаге; и (3) последовательный процесс планирования, который итеративно уточняет первоначальный план на основе обратной связи. Это итеративное уточнение позволяет DS-STAR обрабатывать сложные анализы, извлекая проверяемые результаты из множества источников данных. Мы демонстрируем, что DS-STAR достигает самых современных результатов на сложных тестовых наборах данных, таких как DABStep, KramaBench и DA-Code. Он особенно преуспевает в задачах, связанных с разнообразными, гетерогенными файлами данных.
DS-STAR
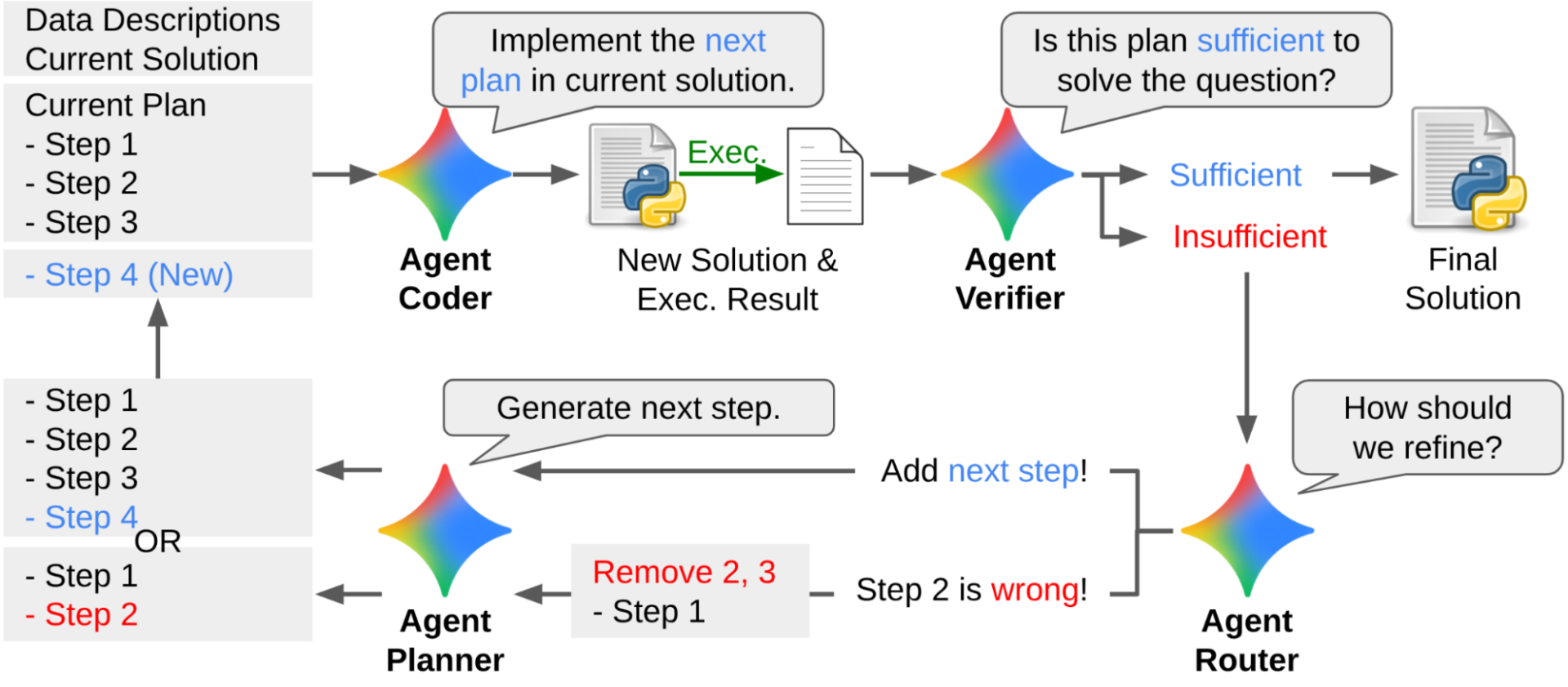
Фреймворк DS-STAR работает в два основных этапа. Во-первых, он автоматически проверяет все файлы в каталоге и создает текстовое описание их структуры и содержимого. Это описание становится важным источником контекста для решения поставленной задачи.

DS-STAR создает скрипт на языке Python для анализа различных файлов данных путем извлечения ключевой информации.
Во-вторых, DS-STAR участвует в основном цикле планирования, реализации и проверки. Агент «Планировщик» сначала создает высокоуровневый план, который затем агент «Кодировщик» преобразует в скрипт кода. Затем агент «Верификатор» оценивает эффективность кода в решении проблемы. Агент «Верификатор» — это судья, основанный на LLM, которому предлагается определить, является ли текущий план адекватным. Если судья считает план недостаточным, DS-STAR уточняет его, изменяя или добавляя шаги (определяемые агентом «Маршрутизатор»), а затем повторяет цикл. Важно отметить, что DS-STAR использует метод, имитирующий то, как эксперт-аналитик использует такие инструменты, как Google Colab, для последовательного построения плана, просматривая промежуточные результаты перед продолжением. Этот итеративный цикл продолжается до тех пор, пока план не будет признан удовлетворительным или не будет достигнуто максимальное количество раундов (10), после чего окончательный код предоставляется в качестве решения.

Рабочий процесс DS-STAR представляет собой итеративный цикл. Он начинается с выполнения простого плана и использует агента-верификатора для проверки его достаточности. Если план недостаточен, агент-маршрутизатор направляет его уточнение, добавляя шаг или исправляя ошибки, после чего цикл повторяется. Процесс продолжается до тех пор, пока верификатор не утвердит план или не будет достигнуто максимальное количество раундов.
Оценка
Для оценки эффективности DS-STAR мы сравнили его производительность с существующими передовыми методами (AutoGen, DA-Agent), используя набор хорошо зарекомендовавших себя бенчмарков для анализа данных: DABStep, KramaBench и DA-Code. Эти бенчмарки оценивают производительность в сложных задачах, таких как обработка данных, машинное обучение и визуализация, использующих множество источников и форматов данных.
Результаты показывают, что DS-STAR значительно превосходит AutoGen и DA-Agent во всех тестовых сценариях. По сравнению с лучшей альтернативой, DS-STAR повысил точность с 41,0% до 45,2% на DABStep, с 39,8% до 44,7% на KramaBench и с 37,0% до 38,5% на DA-Code. Примечательно, что DS-STAR также занял первое место в публичной таблице лидеров по бенчмарку DABStep (по состоянию на 18.09.2025). Как в простых задачах (где ответ находится в одном файле), так и в сложных задачах (требующих нескольких файлов), DS-STAR стабильно превосходит конкурирующие базовые модели, демонстрируя свою превосходную способность работать с множеством разнородных источников данных.

На этом графике показана нормализованная точность (%) как для простых (один файл), так и для сложных (несколько файлов) задач из бенчмарков DABStep, KramaBench и DA-Code. DS-STAR неизменно превосходит конкурирующие базовые модели, демонстрируя особенно сильное преимущество в сложных задачах, требующих обработки нескольких разнородных файлов данных.
Углубленный анализ DS-STAR
Далее мы провели исследования методом абляции, чтобы проверить эффективность отдельных компонентов DS-STAR и проанализировать влияние количества раундов уточнения, в частности, измерив количество итераций, необходимых для создания достаточного плана.
Анализатор файлов данных : Этот агент необходим для высокой производительности. Без генерируемых им описаний (Вариант 1) точность DS-STAR при решении сложных задач в рамках теста DABStep резко упала до 26,98%, что подчеркивает важность богатого контекста данных для эффективного планирования и реализации.
Маршрутизатор : Способность агента-маршрутизатора определять необходимость нового шага или исправлять неправильный шаг имеет решающее значение. Когда мы его удалили (Вариант 2), DS-STAR добавлял новые шаги только последовательно, что привело к ухудшению производительности как в простых, так и в сложных задачах. Это показало, что эффективнее исправлять ошибки в плане, чем постоянно добавлять потенциально ошибочные шаги.
Обобщаемость на разных LLM : Мы также протестировали адаптивность DS-STAR, используя GPT-5 в качестве базовой модели. Это дало многообещающие результаты в бенчмарке DABStep, что указывает на обобщаемость фреймворка. Интересно, что DS-STAR с GPT-5 показал лучшие результаты в простых задачах, в то время как версия Gemini-2.5-Pro показала лучшие результаты в сложных задачах.

Результаты исследования абляции DS-STAR на эталонном тесте DABStep, оценивающие эффективность отдельных агентов и совместимость с LLM.
Анализ процесса уточнения : На рисунке ниже показано, что сложные задачи, естественно, требуют больше итераций. В бенчмарке DABStep для решения сложных задач в среднем требовалось 5,6 раундов, тогда как для простых задач — всего 3,0 раунда. Более того, более половины простых задач были выполнены всего за один раунд.

Анализ раундов уточнения в бенчмарке DABStep показывает, что сложные задачи требуют больше итераций. Для сложных задач в среднем требуется 5,6 раундов против 3,0 для простых задач, при этом более 50% простых задач решаются уже в первом раунде.
Заключение
В этой работе мы представили DS-STAR, нового агента, способного автономно решать задачи в области анализа данных. Фреймворк определяется двумя ключевыми инновациями: автоматическим анализом различных форматов файлов и итеративным, последовательным процессом планирования, использующим новую систему верификации на основе LLM. DS-STAR устанавливает новый стандарт в тестах DABStep, KramaBench и DA-Code, превосходя лучшие альтернативы. Автоматизируя сложные задачи анализа данных, DS-STAR потенциально может сделать науку о данных более доступной для отдельных лиц и организаций, способствуя инновациям во многих различных областях.
Благодарности
Мы хотели бы поблагодарить Цзефэна Чена, Джинву Шина, Раджа Синху, Михира Пармара, Джорджа Ли, Виши Тирумалашетти, Томаса Пфистера и Бурака Гёктюрка за их ценный вклад в эту работу.
Источник: research.google