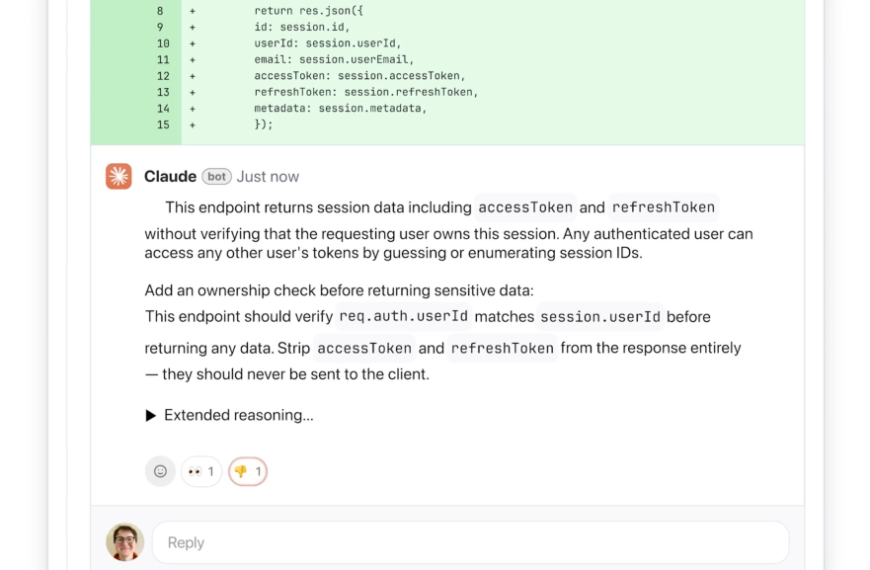
Мы вводим новое понятие достаточного контекста для исследования систем генерации с дополненной реальностью (RAG), разрабатываем метод классификации экземпляров, анализируем сбои в системах RAG и предлагаем способ уменьшения галлюцинаций.
Быстрые ссылки
- Бумага
- Подкаст Illuminate
- Делиться
Генерация с расширенным поиском (Retrieval augmented generation, RAG) улучшает работу больших языковых моделей (LLM), предоставляя им соответствующий внешний контекст. Например, при использовании системы RAG для решения задачи «вопрос-ответ» (QA) LLM получает контекст, который может представлять собой комбинацию информации из нескольких источников, таких как общедоступные веб-страницы, частные корпуса документов или графы знаний. В идеале LLM либо выдает правильный ответ, либо отвечает «Я не знаю», если отсутствует определенная ключевая информация.
Основная проблема систем RAG заключается в том, что они могут вводить пользователя в заблуждение, предоставляя искаженную (и, следовательно, неверную) информацию. Другая проблема состоит в том, что большинство предыдущих работ рассматривали только релевантность контекста запросу пользователя. Но мы считаем, что одной лишь релевантности контекста недостаточно для измерения — нам действительно нужно знать, предоставляет ли он достаточно информации для того, чтобы LLM ответил на вопрос, или нет.
В статье «Достаточный контекст: новый взгляд на системы генерации с дополненной информацией для поиска информации», опубликованной на ICLR 2025, мы изучаем идею «достаточного контекста» в системах генерации с дополненной информацией для поиска информации. Мы показываем, что можно определить, когда у системы генерации с дополненной информацией для поиска информации достаточно информации, чтобы дать правильный ответ на вопрос. Мы изучаем роль контекста (или его отсутствия) в точности фактов и разрабатываем способ количественной оценки достаточности контекста для систем генерации с дополненной информацией для поиска. Наш подход позволяет нам исследовать факторы, влияющие на производительность систем генерации с дополненной информацией для поиска информации, и анализировать, когда и почему они добиваются успеха или терпят неудачу.
Кроме того, мы использовали эти идеи для запуска функции LLM Re-Ranker в движке Vertex AI RAG. Наша функция позволяет пользователям переранжировать полученные фрагменты текста на основе их релевантности запросу, что приводит к улучшению показателей поиска (например, nDCG) и повышению точности системы RAG.

В системе RAG, LLM использует полученный контекст для предоставления ответа на заданный вопрос.
Основной концептуальный вклад: Достаточный контекст
Мы определяем контекст как «достаточный», если он содержит всю необходимую информацию для предоставления окончательного ответа на запрос, и как «недостаточный», если в нем отсутствует необходимая информация, он неполный, неубедительный или содержит противоречивую информацию. Например:
Ввод запроса: Код ошибки «Страница не найдена» назван в честь комнаты 404, в которой хранилась центральная база данных сообщений об ошибках в какой известной лаборатории?
- Достаточный контекст: ошибка «Страница не найдена», часто отображаемая как код 404, названа в честь комнаты 404 в ЦЕРНе, Европейской организации ядерных исследований. Именно в этой комнате хранилась центральная база данных сообщений об ошибках, включая сообщение об ошибке, когда страница не найдена.
- Недостаточный контекст: ошибка 404, или «Страница не найдена», указывает на то, что веб-сервер не может найти запрошенную страницу. Это может произойти по разным причинам, включая опечатки в URL-адресе, перемещение или удаление страницы, а также временные проблемы с веб-сайтом.
Второй контекст очень актуален для запроса пользователя, но он не отвечает на вопрос, и поэтому является недостаточным.
Разработка достаточного контекстного автора
Исходя из этого определения, мы сначала разрабатываем автоматический оценщик на основе LLM («авторейтер»), который оценивает пары запрос-контекст. Для оценки авторейтера мы сначала попросили экспертов проанализировать 115 примеров вопросов и контекстов, чтобы определить, достаточно ли контекста для ответа на вопрос. Это стало «золотым стандартом», с которым мы сравнивали оценки LLM. Затем мы попросили LLM оценить те же вопросы и контексты, где он выдал либо «истина» при достаточном контексте, либо «ложь» при недостаточном контексте.
Для оптимизации способности модели решать эту задачу мы также улучшили подсказку, используя различные стратегии, такие как цепочка рассуждений и предоставление одноразового примера. Затем мы измерили эффективность классификации на основе того, как часто метки «истина/ложь» модели LLM совпадали с эталонными метками.

Наш автоматический метод оценки (авторейтер) достаточности контекста. Мы используем модель LLM с подсказками для оценки примеров, состоящих из входного запроса и полученного контекста. Модель выдает бинарную метку «истина/ложь», которая обозначает достаточный или недостаточный контекст.
Используя нашу оптимизированную подсказку, мы показываем, что можем классифицировать достаточный контекст с очень высокой точностью (по крайней мере, в 93% случаев). Также оказалось, что наилучший из опробованных нами методов — это Gemini 1.5 Pro с подсказкой, без какой-либо тонкой настройки. В качестве базовых показателей мы показываем, что FLAMe (тонко настроенная PaLM 24B) немного хуже, чем Gemini, но может быть более эффективной с точки зрения вычислительных ресурсов альтернативой. Мы также сравниваем наш подход с методами, которые полагаются на ответы, основанные на истинном значении, такими как TRUE-NLI (тонко настроенная модель логического вывода), и методом, который проверяет, появляется ли истинное значение в контексте («Содержит истинное значение»). Gemini превосходит альтернативы, вероятно, потому что обладает лучшими способностями к пониманию языка.

Точность классификации достаточного контекста, где мы измеряем соответствие между различными автоматическими методами и метками, размеченными человеком.
Этот авторизатор позволяет масштабируемо маркировать экземпляры и анализировать ответы модели на основе достаточного и недостаточного контекста.
Ключевые выводы о системах RAG
Используя наш достаточный контекстный авторегрессионный алгоритм, мы проанализировали производительность различных моделей LLM и наборов данных, что привело к нескольким ключевым выводам:
- Современные крупномасштабные модели: модели, такие как Gemini, GPT и Claude, как правило, отлично справляются с ответами на запросы при наличии достаточного контекста, но им не хватает способности распознавать и избегать генерации неверных ответов, когда предоставленного контекста недостаточно.
- Меньшие по размеру модели с открытым исходным кодом: наш анализ выявляет специфическую проблему, заключающуюся в высоком уровне галлюцинаций и воздержания от ответа в моделях с открытым исходным кодом, даже когда контекст достаточен для правильного ответа на вопрос.
- Недостаточный контекст : Иногда модели выдают правильные ответы, даже если мы оцениваем контекст как недостаточный. Это подчеркивает тот факт, что недостаточный контекст все еще может быть полезен. Например, он может восполнить пробелы в знаниях модели или прояснить неоднозначности в запросе.
Практические выводы: На основе полученных данных мы разработали рекомендации по улучшению систем RAG. Например, может быть полезно (i) добавить проверку достаточности перед генерацией, (ii) получить больше контекста или переранжировать полученные контексты, или (iii) настроить порог воздержания с учетом сигналов уверенности и контекста.
Погружение в исследования, лежащие в основе концепции достаточного контекста.
Наш анализ показывает, что несколько стандартных эталонных наборов данных содержат множество примеров с недостаточным контекстом. Мы рассматриваем три набора данных: FreshQA, HotPotQA и MuSiQue. Наборы данных с более высоким процентом примеров с достаточным контекстом, такие как FreshQA, как правило, представляют собой те, где контекст получен из вспомогательных документов, отобранных человеком.
Пример 182 из FreshQA — это вопрос : «Сколько пищевых аллергенов с обязательной маркировкой существует в Соединенных Штатах?» Это сложный вопрос, поскольку ответ — девять, после того как в 2023 году кунжут был добавлен в список. Вспомогательный документ в наборе данных — это статья Википедии о пищевых аллергиях, где в таблице в разделе «Регулирование маркировки» приведен список из девяти аллергенов с обязательной маркировкой.

Сравнение процента примеров с достаточным контекстом (ось Y) по трем наборам данных (ось X).
Добавление контекста приводит к усилению галлюцинаций.
Удивительное наблюдение заключается в том, что, хотя RAG в целом улучшает общую производительность, он парадоксальным образом снижает способность модели воздерживаться от ответа, когда это уместно. Введение дополнительного контекста, по-видимому, повышает уверенность модели, что приводит к большей склонности к галлюцинациям, а не к воздержанию.
Чтобы это понять, мы используем Gemini для оценки каждого ответа модели, сравнивая его с набором возможных истинных ответов. Мы классифицируем каждый ответ как «Правильный», «Галлюцинация» (т.е., неправильный ответ) или «Воздержание» (например, «Я не знаю»). При таком подходе мы обнаруживаем, например, что Gemma переходит от предоставления неправильных ответов на 10,2% вопросов без контекста к 66,1% при использовании недостаточного контекста.

Детальный анализ трех LLM в четырех различных условиях RAG.
Селективная генерация для уменьшения галлюцинаций
В качестве еще одного вклада мы разрабатываем структуру «селективной генерации», которая использует достаточную контекстную информацию для управления воздержанием от ответа. Мы рассматриваем следующие метрики: селективная точность измеряет долю правильных ответов модели среди тех, на которые она отвечает, а охват — это доля отвеченных вопросов (не воздержавшихся).
Наш подход к селективной генерации сочетает в себе достаточный контекстный сигнал с самооценкой уверенности модели, чтобы принимать обоснованные решения о том, когда следует воздержаться от ответа. Это более тонкий подход, чем просто воздержание от ответа всякий раз, когда контекст недостаточен, поскольку модели иногда могут давать правильные ответы даже при ограниченном контексте. Мы используем эти сигналы для обучения модели логистической регрессии для прогнозирования галлюцинаций. Затем мы устанавливаем пороговое значение компромисса между охватом и точностью, определяя, когда модель должна воздерживаться от ответа.
воспроизведение видео без звука зацикливание пауза видео без звука зацикливание включение звука видео выключение звука
Схема нашего метода селективной генерации для уменьшения галлюцинаций.
Мы используем два основных сигнала для воздержания:
- Самооценка уверенности: Мы используем две стратегии: P (Истина) и P (Правильно). Стратегия P (Истина) включает в себя многократную выборку ответов и запрос к модели для присвоения каждому ответу метки «правильно» или «неправильно». Стратегия P (Правильно) используется для моделей, где обширные запросы обходятся дорого; она включает в себя получение ответа модели и ее оценочной вероятности правильности.
- Сигнал достаточности контекста: Мы используем бинарную метку из авторегрессионной модели (FLAMe), чтобы указать, является ли контекст достаточным. Важно отметить, что нам не нужен истинный ответ для определения метки достаточности контекста, поэтому мы можем использовать этот сигнал при ответе на вопрос.
Наши результаты показывают, что такой подход обеспечивает лучший компромисс между точностью и охватом выборки по сравнению с использованием только уверенности модели. Используя метку достаточного контекста, мы можем повысить точность ответов модели на вопросы, иногда до 10% случаев.

Селективная точность (т.е. точность по доле отвеченных вопросов) против охвата (т.е. доли отвеченных вопросов).
Заключение
Наша работа дает новое понимание поведения LLM в системах RAG. Введя и используя концепцию достаточного контекста, мы разработали ценный инструмент для анализа и улучшения этих систем. Мы показали, что галлюцинации в системах RAG могут быть вызваны недостаточным контекстом, и продемонстрировали, что селективная генерация может смягчить эту проблему. В будущих исследованиях будет проанализировано, как различные методы поиска влияют на достаточность контекста, и изучено, как сигналы о качестве поиска могут быть использованы для улучшения модели после обучения.
Благодарности
Данная работа выполнена в сотрудничестве с Хейли Йорен (ведущий автор-студент), Цзяньи Чжаном, Чун-Сун Фернгом и Анкуром Тали. Мы благодарим Марка Симборга и Кимберли Шведе за помощь в написании и оформлении текста соответственно. Мы также благодарим Алишию Олсен за помощь в разработке графического оформления.
Источник: research.google