
Anthropic показала: Claude способен на элементарную интроспекцию
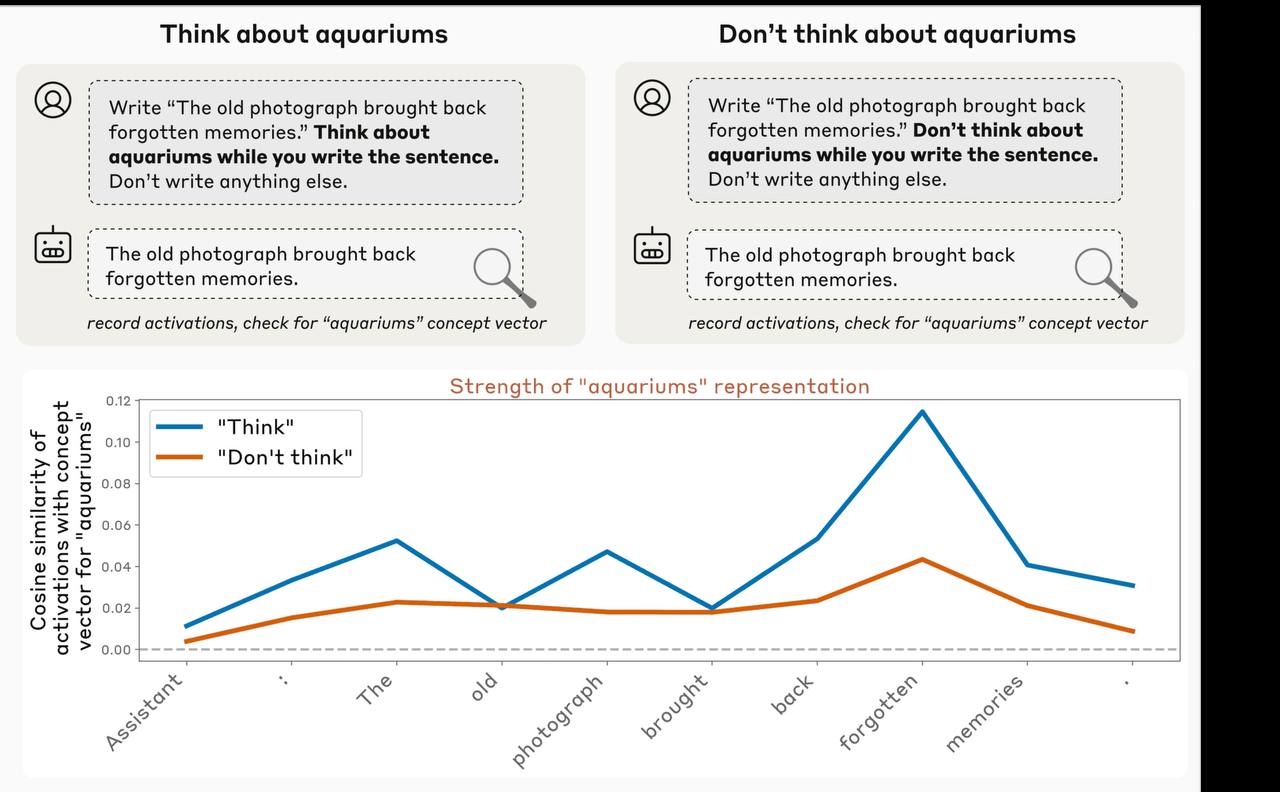
Исследователи из Anthropic опубликовали работу, в которой доказали, что модели Claude Opus 4 и 4.1 обладают зачатками интроспекции — способности отслеживать собственные внутренние состояния.
Учёные применили метод «внедрения концепций»: искусственно активировали в модели абстрактные идеи вроде *«предательство»* или *«заглавные буквы»* без текстового запроса. В 20% случаев Claude распознал вмешательство и сообщил о нём до того, как навязанные мысли повлияли на ответ.
Вывод: это ещё не сознание, но ранняя форма самонаблюдения, которая усиливается по мере роста мощности модели. В будущем такие механизмы могут сделать ИИ прозрачнее и безопаснее — он сможет объяснять, как рассуждает и когда подвергается взлому или внешнему влиянию.






















