LOF объясняется шаг за шагом с помощью небольших наборов данных
Делиться

Вчера мы работали с методом обнаружения аномалий Isolation Forest.
Сегодня мы рассмотрим другой алгоритм, преследующий ту же цель. Но, в отличие от Isolation Forest, он не строит деревья.
Это называется LOF или коэффициент локального выброса.
Люди часто суммируют LOF одним предложением: находится ли эта точка в регионе с более низкой плотностью, чем ее соседи?
Это предложение на самом деле сложно понять . Я долго над ним бился.
Однако есть одна часть, которую легко понять сразу,
и мы увидим, что это становится ключевым моментом:
есть понятие соседей.
И как только мы говорим о соседях,
мы, естественно, возвращаемся к моделям, основанным на расстоянии .
Мы объясним этот алгоритм в 3 шага.
Для простоты мы снова будем использовать этот набор данных:
1, 2, 3, 9
Помните, у меня есть авторские права на этот набор данных? Мы провели с ним Isolation Forest и снова проведём LOF. И мы также можем сравнить два результата.

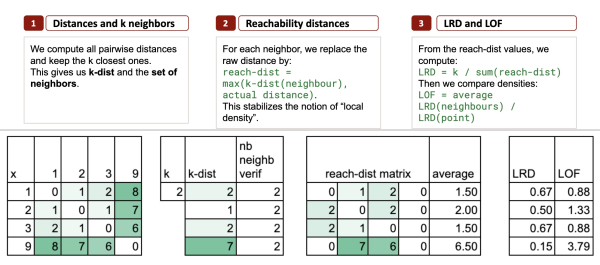
Шаг 1 – k соседей и k-расстояние
LOF начинается с чего-то чрезвычайно простого:
Посмотрите на расстояния между точками.
Затем найдите k ближайших соседей каждой точки.
Давайте возьмем k = 2 , чтобы свести все к минимуму.
Ближайшие соседи для каждой точки
- Точка 1 → соседи: 2 и 3
- Точка 2 → соседи: 1 и 3
- Точка 3 → соседи: 2 и 1
- Точка 9 → соседи: 3 и 2
Уже сейчас мы видим вырисовывающуюся четкую структуру:
- 1, 2 и 3 образуют плотный кластер
- 9 жизней в одиночестве, вдали от других
Расстояние k: локальный радиус
Расстояние k — это просто наибольшее расстояние среди k ближайших соседей.
И это на самом деле ключевой момент .
Потому что это единственное число говорит вам нечто очень конкретное:
локальный радиус вокруг точки.
Если k-расстояние мало, точка находится в плотной области.
Если k-расстояние велико, точка находится в разреженной области.
С помощью только этого одного измерения вы уже получите первый сигнал «изоляции».
Здесь мы используем идею «k ближайших соседей», что, конечно, напоминает нам о k-NN (классификаторе или регрессоре).
Контекст здесь другой, но расчет тот же самый.
И если вы думаете о k-средних , не смешивайте их:
«k» в аббревиатуре k-means не имеет ничего общего с «k» в данном случае.
Расчет k-расстояния
Для точки 1 два ближайших соседа — это 2 и 3 (расстояния 1 и 2), поэтому k-расстояние(1) = 2 .
Для точки 2 соседями являются 1 и 3 (оба на расстоянии 1), поэтому k-расстояние(2) = 1 .
Для точки 3 два ближайших соседа — это 1 и 2 (расстояния 2 и 1), поэтому k-расстояние(3) = 2 .
Для точки 9 соседями являются точки 3 и 2 (т.е. 6 и 7), поэтому k-расстояние(9) = 7. Это очень много по сравнению со всеми остальными.
В Excel мы можем создать матрицу парных расстояний, чтобы получить k-расстояние для каждой точки.

Шаг 2 – Расстояния достижимости
На этом этапе я просто определю вычисления здесь и применю формулы в Excel. Потому что, честно говоря, мне так и не удалось найти по-настоящему интуитивно понятный способ объяснения результатов.
Итак, что такое «расстояние достижимости»?
Для точки p и ее соседа o мы определяем это расстояние достижимости как:
досягаемость-расстояние(p, o) = макс(k-расстояние(o), расстояние(p, o))
Зачем брать максимум?
Целью расстояния достижимости является стабилизация сравнения плотности .
Если сосед o живет в очень плотной области (малое k-расстояние), то мы не хотим допускать нереально малого расстояния.
В частности, по пункту 2:
- Расстояние до 1 = 1, но k-расстояние(1) = 2 → расстояние-расстояние(2, 1) = 2
- Расстояние до 3 = 1, но k-расстояние(3) = 2 → расстояние-расстояние(2, 3) = 2
Оба соседа увеличивают расстояние достижимости.
В Excel мы сохраним матричный формат для отображения расстояний достижимости: одна точка в сравнении со всеми остальными.

Среднее расстояние достижимости
Для каждой точки мы теперь можем вычислить среднее значение, которое говорит нам: какое расстояние в среднем мне нужно проехать, чтобы добраться до моего местного района?
А теперь заметьте: точка 2 имеет большее среднее расстояние достижимости, чем точки 1 и 3.
Для меня это не так уж и интуитивно понятно!
Шаг 3 – LRD и оценка LOF
Последний шаг — это своего рода «нормализация» для нахождения показателя аномалии.
Сначала мы определяем LRD (плотность локальной достижимости), которая является просто обратной величиной среднего расстояния достижимости.
Окончательный балл LOF рассчитывается следующим образом:

Итак, LOF сравнивает плотность точки с плотностью ее соседей.
Интерпретация:
- Если LRD(p) ≈ LRD (соседей), то LOF ≈ 1
- Если LRD(p) намного меньше , то LOF >> 1. Таким образом, p находится в разреженной области.
- Если LRD(p) намного больше → LOF < 1. Таким образом, p находится в очень плотном кармане.
Я также сделал версию с большим количеством развитий и более короткими формулами.

Понимание того, что означает «аномалия» в неконтролируемых моделях
В неконтролируемом обучении нет основополагающих принципов. И именно здесь всё может стать запутанным.
У нас нет этикеток.
У нас нет «правильного ответа».
У нас есть только структура данных.
Возьмем этот небольшой пример:
1, 2, 3, 7, 8, 12
(У меня также есть на него авторские права.)
Если взглянуть интуитивно, какой из вариантов кажется вам аномалией?
Лично я бы сказал 12 .
Теперь посмотрим на результаты. LOF показывает, что выброс равен 7 .
(И вы можете заметить, что в случае k-расстояния мы бы сказали, что оно равно 12. )

Теперь мы можем сравнить Isolation Forest и LOF бок о бок.
Слева, с наборами данных 1, 2, 3, 9 , оба метода согласуются:
9 — явный выброс.
Isolation Forest дает ему самую низкую оценку,
а LOF дает ему наивысшее значение LOF.
Если присмотреться, то для Isolation Forest: 1, 2 и 3 разницы в результатах нет. А LOF даёт более высокий результат для 2. Это мы уже заметили.
С наборами данных 1, 2, 3, 7, 8, 12 ситуация меняется.
- Isolation Forest указывает на 12 как на самую изолированную точку.
Это соответствует интуиции: 12 — далеко не для всех. - Однако LOF вместо этого выделяет 7 .

Так кто же прав?
Трудно сказать.
На практике нам сначала необходимо договориться с бизнес-командами о том, что на самом деле означает «аномалия» в контексте наших данных.
Потому что при неконтролируемом обучении не существует единой истины.
Существует только определение «аномалии», которое использует каждый алгоритм.
Вот почему так важно понимать
как работает алгоритм и какие виды аномалий он предназначен для обнаружения.
Только после этого вы сможете решить, является ли метод LOF, или k-расстояния, или изолирующего леса правильным выбором для вашей конкретной ситуации.
И в этом заключается суть неконтролируемого обучения:
Разные алгоритмы рассматривают данные по-разному.
«Истинного» выброса не существует.
Только определение того, что означает выброс для каждой модели.
Вот почему понимание того, как работает алгоритм,
важнее, чем конечный результат, который он выдает.
Заключение
Оба метода — LOF и Isolation Forest — обнаруживают аномалии, но рассматривают данные с совершенно разных точек зрения.
- k-расстояние показывает, какое расстояние должна пройти точка, чтобы найти своих соседей.
- LOF сравнивает локальные плотности.
- Изолирующий лес изолирует точки, используя случайные разделения.
И даже на очень простых наборах данных эти методы могут не сработать.
Один алгоритм может пометить точку как выброс, в то время как другой выделит совершенно другую.
И вот ключевое сообщение:
При неконтролируемом обучении не существует «истинных» выбросов.
Каждый алгоритм определяет аномалии в соответствии со своей логикой.
Вот почему понимание того, как работает метод, важнее, чем число, которое он выдает.
Только тогда вы сможете выбрать правильный алгоритм для нужной ситуации и с уверенностью интерпретировать результаты.
Источник: towardsdatascience.com