Обнаружение аномалий стало интуитивно понятным
Делиться

Проведя выходные с деревьями решений, как для регрессии, так и для классификации, мы продолжим использовать принцип деревьев решений сегодня.
И на этот раз мы находимся на этапе неконтролируемого обучения, поэтому нет никаких меток.
Алгоритм называется «Лес изоляции» (Isolation Forest). Его идея заключается в построении множества деревьев решений, образующих лес. Принцип заключается в обнаружении аномалий путём их изоляции.
Чтобы все было проще понять, давайте возьмем очень простой пример набора данных, который я создал сам:
1, 2, 3, 9
(И поскольку главный редактор TDS напомнил мне о юридических деталях, связанных с упоминанием источника данных, позвольте мне заявить следующее: этот набор данных полностью защищен моими авторскими правами. Это набор данных из четырех точек, который я создал вручную, и я с радостью предоставляю всем право использовать его в образовательных целях.)
Цель здесь проста: найти аномалию, нарушителя.
Я знаю, вы уже догадались, о чем речь.
Как всегда, идея состоит в том, чтобы превратить это в алгоритм, который сможет обнаружить это автоматически.
Обнаружение аномалий в классической структуре машинного обучения
Прежде чем двигаться дальше, давайте сделаем шаг назад и посмотрим, какое место занимает обнаружение аномалий в общей картине.

Слева мы имеем контролируемое обучение с маркированными данными и двумя основными типами:
- Регрессия, когда цель числовая
- Классификация, когда цель категориальна
До сих пор мы использовали деревья решений.
Справа мы имеем неконтролируемое обучение , без меток.
Мы ничего не предсказываем. Мы просто манипулируем наблюдениями (кластеризация и обнаружение аномалий) или манипулируем признаками (снижение размерности и другие методы).
Снижение размерности манипулирует признаками. Несмотря на то, что оно относится к категории «неконтролируемых», его цель существенно отличается от других. Поскольку оно изменяет форму самих признаков, это похоже на конструирование признаков.
Для методов уровня наблюдения у нас есть две возможности:
- Кластеризация : групповые наблюдения
- Обнаружение аномалий : присвоение оценки каждому наблюдению
На практике некоторые модели могут выполнять обе задачи одновременно. Например, метод k-средних способен обнаруживать аномалии.
Изолированный лес предназначен только для обнаружения аномалий, а не для кластеризации.
Итак, сегодня мы именно здесь:
Неконтролируемое обучение → Кластеризация / Обнаружение аномалий → Обнаружение аномалий
Мучительная часть: построение деревьев в Excel
Теперь мы начинаем реализацию в Excel, и я должен признаться: эта часть действительно болезненная…
Это неудобно, потому что нам нужно создать множество мелких правил, а формулы сложно перетаскивать. Это одно из ограничений Excel, когда модель основана на решениях . Excel отлично работает, когда формулы выглядят одинаково для каждой строки. Но здесь каждый узел дерева подчиняется своему правилу, поэтому формулы сложно обобщать.
Для деревьев решений мы видели, что при одном разделении формула работает. Но я специально остановился на этом. Почему? Потому что добавление дополнительных разделений в Excel усложняет задачу. Структура дерева решений изначально не «удобна для перетаскивания».
Однако в случае с Isolation Forest у нас нет выбора.
Нам нужно построить полное дерево , до самого низа, чтобы увидеть, насколько изолирована каждая точка.
Если у вас, дорогие читатели, есть идеи, как это упростить, пожалуйста, свяжитесь со мной.
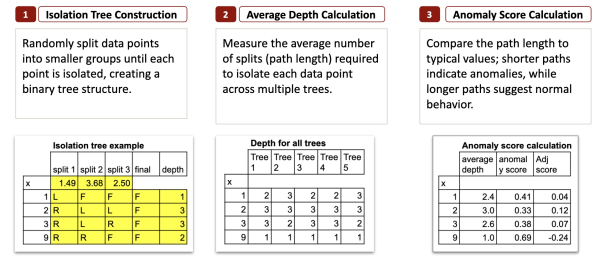
Изолированный лес в 3 шага
Несмотря на сложность формул, я постарался структурировать подход. Вот весь метод, состоящий всего из трёх шагов.

1. Построение дерева изоляции
Начнем с создания одного дерева изоляции.
В каждом узле мы выбираем случайное значение разделения между минимумом и максимумом текущей группы.
Это разделение делит наблюдения на «левые» (Л) и «правые» (П).
Когда наблюдение становится изолированным, я отмечаю его как F (Final), что означает, что оно достигло листа.
Повторяя этот процесс, мы получаем полное бинарное дерево, в котором аномалии, как правило, изолируются за меньшее количество шагов. Для каждого наблюдения мы можем затем подсчитать его глубину , которая представляет собой количество разбиений, необходимых для его изоляции.

2. Расчет средней глубины
Одного дерева недостаточно. Поэтому мы повторяем один и тот же случайный процесс несколько раз, чтобы построить несколько деревьев.
Для каждой точки данных мы подсчитываем, сколько разделений потребовалось для ее изоляции в каждом дереве.
Затем мы вычисляем среднюю глубину (или среднюю длину пути) по всем деревьям.
Это дает стабильную и значимую меру того, насколько легко изолировать каждую точку.
На этом этапе средняя глубина уже дает нам надежный индикатор:
чем меньше глубина, тем больше вероятность, что точка является аномалией.
Небольшая глубина означает, что точка изолируется очень быстро, что является признаком аномалии.
Большая глубина означает, что точка ведет себя так же, как и остальные данные, поскольку они остаются сгруппированными вместе и их нелегко разделить.
В нашем примере оценка вполне логична.
- Во-первых, 9 — это аномалия со средней глубиной 1. Для всех 5 деревьев одного разделения достаточно, чтобы её изолировать. (Хотя это не всегда так, вы можете проверить это сами.)
- Для остальных трёх наблюдений глубина аналогична и заметно больше. Наивысший балл присуждён варианту 2, который находится в середине группы, и это именно то, чего мы и ожидали.
Если когда-нибудь вам придётся кому-то объяснить этот алгоритм, смело используйте этот набор данных: он легко запоминается и интуитивно понятен для иллюстрации. И, пожалуйста, не забудьте упомянуть мои авторские права на него!

3. Расчет показателя аномальности
Последний шаг — нормализация средней глубины для получения стандартного показателя аномальности от 0 до 1.
Утверждение, что наблюдение имеет среднюю глубину n, само по себе ничего не значит.
Это значение зависит от общего количества точек данных, поэтому мы не можем интерпретировать его напрямую как «нормальное» или «аномальное».
Идея состоит в том, чтобы сравнить среднюю длину пути каждой точки с типичным значением, ожидаемым в условиях чистой случайности. Это показывает, насколько удивительной (или нет) является глубина.
Мы увидим трансформацию позже, но цель проста:
превратить сырую глубину в относительную оценку, имеющую смысл без какого-либо контекста.
Короткие глубины, естественно, станут оценками, близкими к 1 (аномалии),
а большие глубины станут оценками, близкими к 0 (нормальные наблюдения).
И наконец, некоторые реализации корректируют оценку таким образом, что она приобретает другой смысл: положительные значения указывают на нормальные точки , а отрицательные — на аномалии . Это просто преобразование исходной оценки аномалии.
Основная логика совершенно не меняется: короткие пути по-прежнему соответствуют аномалиям, а длинные пути — нормальным наблюдениям.

Построение дерева изоляции
Вот это и есть болезненная часть.
Краткий обзор
Я создал таблицу, в которой отражены различные этапы процесса построения дерева.
Он нестандартный и не идеально структурированный, но я приложил все усилия, чтобы сделать его читабельным.
И я не уверен, что все формулы хорошо обобщаются.

- Получить минимальное и максимальное значения текущей группы.
- Сгенерировать случайное значение разделения между этим минимумом и максимумом.
- Разделите наблюдения на левые (Л) и правые (П).
- Подсчитайте, сколько наблюдений попадает в L и R.
- Если группа содержит только одно наблюдение , отметьте ее как F (финальная) и остановитесь на этой ветви.
- Повторяйте процесс для каждой нефинальной группы, пока все наблюдения не будут изолированы.
Вот и вся логика построения одного дерева изоляции.
Развернутое объяснение
Начнем со всех наблюдений одновременно.
Первый шаг — найти минимум и максимум в этой группе. Эти два значения определяют интервал, в котором можно сделать случайный выбор.
Затем мы генерируем случайное значение разбиения где-то между минимумом и максимумом. В отличие от деревьев решений, здесь нет оптимизации, критериев и мер примесей. Разбиение происходит чисто случайно.
Мы можем использовать функцию СЛЧИС в Excel, как показано на следующем снимке экрана.

После случайного разделения мы делим данные на две группы:
- Слева (L): наблюдения меньше или равны разделению
- Справа (R): наблюдения больше, чем разделение
Это просто делается путем сравнения разделения с наблюдениями с помощью формулы ЕСЛИ.

После разделения мы подсчитываем , сколько наблюдений досталось каждой стороне.
Если одна из этих групп содержит только одно наблюдение , то эта точка теперь изолирована.
Мы помечаем его как F (Final), что означает, что он находится в листе и для этой ветви не требуется дальнейшего разделения.
Функция ВПР предназначена для извлечения из таблицы подсчетов тех наблюдений, на стороне которых находится 1.

Для всех остальных групп, которые все еще содержат множественные наблюдения, мы повторяем точно такой же процесс.
Мы останавливаемся только тогда, когда каждое наблюдение изолировано , то есть каждое из них находится в своём собственном конечном листе. Получающаяся структура представляет собой бинарное дерево , а количество разбиений, необходимых для изоляции каждого наблюдения, — это его глубина .
Здесь мы знаем, что трех делений достаточно.
В конце вы получаете итоговую таблицу одного полностью сформировавшегося дерева изоляции.
Расчет показателя аномалии
Часть об усреднении глубины — это просто повторение того же процесса, и вы можете скопировать и вставить.
Теперь я расскажу более подробно о расчете показателя аномальности.
Коэффициент нормализации
Для вычисления показателя аномалии в методе Isolation Forest сначала необходим нормализующий фактор, называемый c(n) .
Это значение представляет собой ожидаемую глубину случайной точки в случайном двоичном дереве поиска с n наблюдениями.
Зачем нам это нужно?
Потому что мы хотим сравнить фактическую глубину точки с типичной глубиной, ожидаемой в условиях случайности.
Точка, которая изолируется гораздо быстрее, чем ожидалось, скорее всего, является аномалией.
Формула для c(n) использует гармонические числа.
Гармоническое число H(k) приблизительно равно:

где γ = 0,5772156649 — константа Эйлера–Маскерони.
Используя это приближение, нормализующий коэффициент становится:

Затем мы можем рассчитать это число в Excel.

Как только у нас есть c(n) , оценка аномалии будет равна:

где h(x) — средняя глубина, необходимая для изоляции точки среди всех деревьев.
Если оценка близка к 0 , балл нормальный.
Если оценка близка к 1 , то точка является аномалией.
Таким образом, мы можем преобразовать глубины в оценки.

Наконец, для скорректированной оценки мы можем использовать смещение, т. е. среднее значение оценок аномалий, и выполнить перевод.

Дополнительные элементы в реальном алгоритме
На практике Isolation Forest включает в себя несколько дополнительных шагов, которые делают его более надежным.
1. Выберите подвыборку данных
Вместо того чтобы использовать полный набор данных для каждого дерева, алгоритм выбирает небольшое случайное подмножество.
Это сокращает объем вычислений и увеличивает разнообразие деревьев.
Это также помогает предотвратить перегрузку модели очень большими наборами данных.
Так что, похоже, название «Лес случайной изоляции» будет более подходящим, верно?
2. Сначала выберите случайный объект.
При построении каждого разделения Isolation Forest не всегда использует одну и ту же функцию.
Сначала он выбирает случайный объект, а затем выбирает случайное значение разделения внутри этого объекта.
Это делает деревья еще более разнообразными и помогает модели эффективно работать с наборами данных со многими переменными.
Эти простые дополнения делают Isolation Forest удивительно мощным инструментом для реальных приложений.
Это снова то, что делал бы «Лес случайной изоляции», это название определенно лучше!
Преимущества изолированного леса
По сравнению со многими моделями, основанными на расстоянии, Isolation Forest имеет несколько важных преимуществ:
- Работает с категориальными признаками
Методы, основанные на расстоянии, испытывают трудности с категориями, но Isolation Forest может справляться с ними более естественно. - Легко справляется со многими функциями
Многомерные данные не являются проблемой.
Алгоритм не полагается на метрики расстояния, которые ломаются в больших измерениях. - Никаких предположений о распределениях
Нет необходимости в нормальности, оценке плотности, вычислении расстояний. - Хорошо масштабируется до больших размеров
Его производительность не падает при увеличении количества функций. - Очень быстро
Разделение тривиально: выбираем признак, выбираем случайное значение, разрезаем.
Никакого этапа оптимизации, никакого градиента, никакого расчета примесей.
У Isolation Forest также очень освежающий образ мышления:
Вместо того, чтобы спрашивать : «Как должны выглядеть нормальные точки?» ,
Isolation Forest спрашивает: «Как быстро я смогу изолировать эту точку?»
Это простое изменение перспективы решает многие трудности классического обнаружения аномалий.
Заключение
Isolation Forest — это алгоритм, который снаружи выглядит сложным, но если его разобрать, то логика на самом деле очень проста.
Да, реализация Excel — проблема, но сама идея — нет.
И как только вы поймете идею, все остальное станет намного проще: как работают деревья, почему глубина имеет значение, как вычисляется оценка и почему алгоритм так хорошо работает на практике.
«Лес изоляции» не пытается моделировать «нормальное» поведение. Вместо этого он задаёт совершенно другой вопрос: насколько быстро я могу изолировать это наблюдение?
Это небольшое изменение точки зрения решает многие проблемы, с которыми сталкиваются модели, основанные на расстоянии или плотности.
Источник: towardsdatascience.com