От k-средних до гауссовой смеси: понимание EM с помощью простых формул Excel
Делиться

В предыдущей статье мы исследовали кластеризацию на основе расстояний с использованием метода K-средних.
Сегодня мы сделаем еще один шаг: чтобы улучшить способ измерения расстояния, мы добавим дисперсию, чтобы получить расстояние Махаланобиса.
Итак, если k-Means является неконтролируемой версией классификатора ближайшего центроида , то возникает естественный вопрос:
Что такое неконтролируемая версия QDA?
Это означает, что, как и в случае QDA, каждый кластер теперь должен быть описан не только средним значением , но и дисперсией (и нам также придётся добавлять ковариацию, если число признаков больше 2). Но здесь всё изучается без меток.
Итак, вы понимаете идею, да?
И название этой модели — модель гауссовой смеси (GMM) …
GMM и названия этих моделей…
Как это часто бывает, названия моделей имеют историческое происхождение. Они не всегда призваны подчёркивать связи между моделями, если они не встречаются вместе.
Разные исследователи, разные периоды, разные варианты использования… и в итоге мы получаем названия, которые иногда скрывают истинную структуру идей.
Здесь название «модель гауссовой смеси» просто означает, что данные представлены в виде смеси нескольких гауссовых распределений .
Если следовать той же логике наименования, что и в случае k-средних, было бы понятнее назвать его как-то вроде k-Gaussian Mixture.
Потому что на практике вместо того, чтобы использовать только среднее значение, мы добавляем дисперсию. Можно было бы просто использовать расстояние Махаланобиса или другое взвешенное расстояние, использующее как среднее значение, так и дисперсию. Но гауссово распределение даёт нам вероятности, которые легче интерпретировать.
Поэтому мы выбираем число k гауссовых компонент.
И, кстати, GMM — не единственный.
Фактически, вся система машинного обучения появилась гораздо позже, чем многие из входящих в неё моделей. Большинство этих методов изначально были разработаны в области статистики, обработки сигналов, эконометрики или распознавания образов.
Затем, гораздо позже, возникла область, которую мы сейчас называем «машинным обучением», и объединила все эти модели под одной крышей. Но названия остались прежними.
Поэтому сегодня мы используем смесь лексики, пришедшей из разных эпох, разных сообществ и с разными намерениями.
Вот почему взаимосвязи между моделями не всегда очевидны, если смотреть только на названия.
Если бы нам пришлось переименовать все в современном, унифицированном стиле машинного обучения , картина была бы гораздо яснее:
- GMM станет k-гауссовой кластеризацией
- QDA станет ближайшим гауссовым классификатором
- LDA, то есть ближайший гауссовский классификатор с одинаковой дисперсией по классам.
И вдруг появляются все ссылки:
- k-средних ↔ Ближайший центроид
- GMM ↔ Ближайший гауссов (QDA)
Вот почему GMM так естественен после K-средних. Если K-средние группируют точки по ближайшему центроиду, то GMM группирует их по наиболее близкой гауссовой форме .
Зачем посвятил целый раздел обсуждению имен?
Ну, правда в том, что, поскольку мы уже рассмотрели алгоритм k-средних и уже осуществили переход от классификатора ближайших центроидов к QDA, мы уже знаем все об этом алгоритме, и алгоритм обучения не изменится…
А как НАЗЫВАЕТСЯ этот алгоритм обучения?
О, алгоритм Ллойда.
На самом деле, до того, как алгоритм k-средних получил такое название, он был известен просто как алгоритм Ллойда, опубликованный Стюартом Ллойдом в 1957 году . Лишь позже сообщество машинного обучения изменило его на «k-средние».
А этот алгоритм манипулировал только средствами, так что нам нужно другое название, верно?
Видите, к чему это приводит: алгоритм максимизации ожиданий!
EM — это просто общая форма идеи Ллойда. Ллойд обновляет средние значения, EM обновляет всё: средние значения, дисперсии, веса и вероятности.
Итак, вы уже всё знаете о ГММ!
Но поскольку моя статья называется «GMM в Excel», я не могу закончить ее здесь…
GMM в 1 измерении
Начнем с этого простого набора данных, того же самого, который мы использовали для k-средних: 1, 2, 3, 11, 12, 13
Хм, у двух гауссианов будут одинаковые дисперсии. Так что подумайте о том, чтобы поиграться с другими числами в Excel!
И нам, естественно, нужно 2 кластера .
Вот различные шаги.
Инициализация
Начнем с предположений относительно средних значений, дисперсий и весов.

Шаг ожидания (шаг E)
Для каждой точки мы вычисляем вероятность ее принадлежности к каждой гауссиане.

Шаг максимизации (M-шаг)
Используя эти вероятности, мы обновляем средние значения, дисперсии и веса.

Итерация
Повторяем E-шаг и M-шаг до тех пор, пока параметры не стабилизируются.

Каждый шаг становится чрезвычайно простым, как только формулы становятся видимыми.
Вы увидите, что EM — это не что иное, как обновление средних значений, дисперсий и вероятностей.
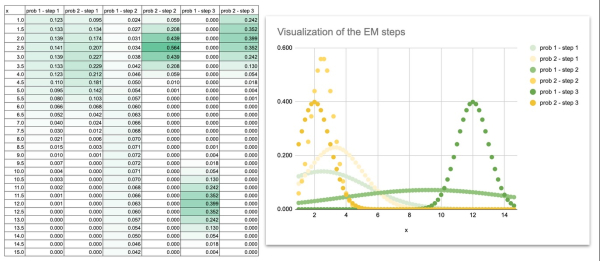
Мы также можем провести некоторую визуализацию, чтобы увидеть, как кривые Гаусса движутся во время итераций.
Вначале две гауссовы кривые сильно перекрываются, поскольку начальные средние значения и дисперсии являются всего лишь догадками.
Кривые медленно разделяются, выравнивают свою ширину и, наконец, точно совпадают с двумя группами точек.
Построив гауссовы кривые на каждой итерации, вы можете буквально наблюдать, как модель обучается:
- средства скользят к центрам данных
- дисперсии уменьшаются, чтобы соответствовать разбросу каждой группы
- перекрытие исчезает
- окончательные формы соответствуют структуре набора данных
Эта визуальная эволюция чрезвычайно полезна для развития интуиции. Как только вы видите движение кривых, электромагнетизм перестаёт быть абстрактным алгоритмом. Он становится динамическим процессом, который можно отслеживать шаг за шагом.

GMM в 2 измерениях
Логика точно такая же, как в одномерном пространстве. Ничего принципиально нового. Мы просто расширяем формулы…
Вместо одного объекта на точку теперь у нас два .
Каждый гауссианец теперь должен узнать:
- среднее для x1
- среднее для x2
- дисперсия для x1
- дисперсия для x2
- И ковариационный член между двумя признаками.
После того как вы запишете формулы в Excel, вы увидите, что процесс остается точно таким же:
Ну, правда в том, что если взглянуть на скриншот, можно подумать: «Ого, какая длинная формула!» И это ещё не всё.

Но не обманывайтесь. Формула получилась длинной только потому, что мы явно выписываем двумерную гауссову плотность :
- одна часть для расстояния в x1
- одна часть для расстояния в х2
- ковариационный член
- константа нормализации
Ничего больше.
Это просто формула плотности, расширенная по ячейкам.
Долго печатать, но вполне понятно, как только вы увидите структуру: взвешенное расстояние внутри экспоненты, деленное на определитель.
Так что да, формула выглядит громоздкой… но идея, лежащая в ее основе, чрезвычайно проста.
Заключение
Метод K-средних устанавливает жесткие границы.
GMM дает вероятности.
После того как формулы EM записаны в Excel, модель становится простой для понимания: средние значения меняются, дисперсии корректируются, а гауссовы функции естественным образом устанавливаются вокруг данных.
GMM — это всего лишь следующий логический шаг после k-средних, предлагающий более гибкий способ представления кластеров и их форм.
Источник: towardsdatascience.com