Как реализовать алгоритм обучения, который наконец станет похож на «настоящее» машинное обучение
Делиться

Добро пожаловать в четвертый день Адвент-календаря машинного обучения.
В течение первых трех дней мы изучали дистанционные модели контролируемого обучения:
- регрессор k-NN ,
- классификатор k-NN ,
- и классификатор ближайшего центроида .
Во всех этих моделях идея была одинаковой: мы измеряем расстояния и определяем выходные данные на основе ближайших точек или ближайших центров.
Сегодня мы придерживаемся той же идеи. Но используем расстояния без учителя: метод k-средних .
Теперь один вопрос для тех, кто уже знаком с этим алгоритмом: на какую модель больше похож алгоритм k-means, на классификатор k-NN или на классификатор ближайшего центроида?
И если вы помните, во всех моделях, которые мы видели до сих пор, на самом деле не было фазы «обучения» или настройки гиперпараметров.
- Для k-NN обучение вообще не требуется.
- Для LDA, QDA или GNB обучение сводится лишь к вычислению средних значений и дисперсий. Кроме того, здесь нет реальных гиперпараметров.
Теперь с помощью k-средних мы реализуем алгоритм обучения, который наконец станет похож на «настоящее» машинное обучение.
Начнём с небольшого одномерного примера. Затем перейдём к двухмерному.
Цель метода k-средних
В обучающем наборе данных начальные метки отсутствуют .
Целью метода k-средних является создание осмысленных меток путем группировки точек, расположенных близко друг к другу.
Давайте посмотрим на иллюстрацию ниже. Вы можете ясно увидеть две группы точек. Каждый центроид (красный и зелёный квадраты) находится в центре своего кластера, и каждая точка соответствует ближайшему к нему центроиду.
Это дает очень наглядное представление о том, как метод k-средних обнаруживает структуру, используя только расстояния.
И здесь k означает количество центров, которые мы пытаемся найти.

Теперь ответим на вопрос: к какому алгоритму ближе k-means, к классификатору k-NN или к классификатору ближайшего центроида?
Не позволяйте букве k в аббревиатурах k-NN и k-means вводить вас в заблуждение.
Они не означают одно и то же:
- в k-NN k — это число соседей, а не число классов;
- в алгоритме k-средних k — число центроидов.
Метод K-средних гораздо ближе к классификатору ближайшего центроида .
Обе модели представлены центроидами , и для нового наблюдения мы просто вычисляем расстояние до каждого центроида, чтобы решить, к какому из них он принадлежит.
Разница, конечно, состоит в том, что в классификаторе «Ближайший центроид» мы уже знаем центроиды, поскольку они берутся из помеченных классов.
В алгоритме k-средних мы не знаем центроидов. Вся цель алгоритма — найти подходящие центроиды непосредственно из данных.
Проблема бизнеса совершенно иная: вместо того, чтобы предсказывать этикетки, мы пытаемся их создавать .
В алгоритме k-средних значение k (количество центроидов) неизвестно. Поэтому оно становится гиперпараметром , который можно настраивать.
k-means только с одной особенностью
Начнём с небольшого одномерного примера, чтобы всё было видно на одной оси. И выберем значения настолько тривиально, что сразу увидим два центроида.
1, 2, 3, 11, 12, 13
Да, 2 и 12.
Но откуда компьютеру знать? Машина будет «учиться», угадывая шаг за шагом.
Вот алгоритм, называемый алгоритмом Ллойда .
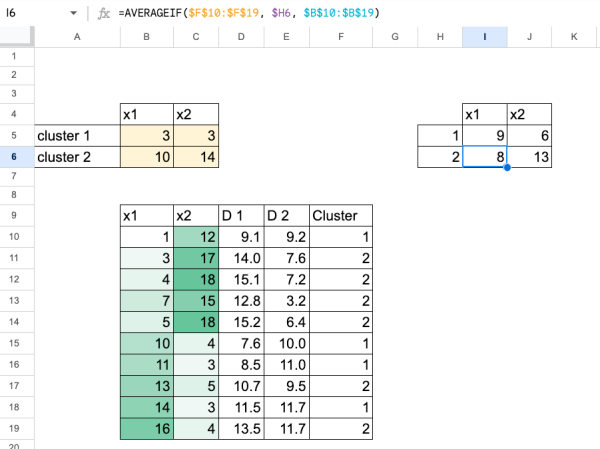
Мы реализуем это в Excel с помощью следующего цикла:
- выбрать начальные центроиды
- вычислить расстояние от каждой точки до каждого центроида
- присвоить каждой точке ближайший центроид
- пересчитать центроиды как среднее значение точек в каждом кластере
- повторяйте шаги 2–4, пока центроиды не перестанут двигаться
1. Выберите начальные центроиды
Выберите два начальных центра, например:
- с_1 = 2,5
- с_2 = 3
Они должны находиться в пределах диапазона данных (от 1 до 13).

2. Вычислить расстояния
Для каждой точки данных x:
- вычислить расстояние до c_1,
- вычислить расстояние до c_2.
Обычно мы используем абсолютное расстояние в 1D.
Теперь у нас есть два значения расстояния для каждой точки.

3. Назначить кластеры
Для каждой точки:
- сравните два расстояния,
- назначить кластер наименьшего из них (1 или 2).
В Excel это простая логика, основанная на ЕСЛИ или МИН.

4. Вычислить новые центроиды
Для каждого кластера:
- возьмите баллы, присвоенные этому кластеру,
- вычислить их среднее значение,
- это среднее значение становится новым центроидом.

5. Повторять до достижения сходимости.
Теперь в Excel, благодаря формулам, мы можем просто вставить новые значения центроидов в ячейки исходных центроидов.
Обновление происходит мгновенно, и после нескольких повторений вы увидите, что значения перестают меняться. Это означает, что алгоритм сошелся.

Мы также можем записывать каждый шаг в Excel, чтобы видеть, как центроиды и кластеры меняются с течением времени.

k-средних с двумя признаками
Теперь воспользуемся двумя характеристиками. Процесс тот же самый: мы просто используем евклидово расстояние в двумерном пространстве.
Вы можете либо скопировать и вставить новые центроиды как значения (обновив всего несколько ячеек),

или вы можете отобразить все промежуточные шаги , чтобы увидеть полную эволюцию алгоритма.

Визуализация движущихся центроидов в Excel
Чтобы сделать процесс более наглядным, полезно создать графики, показывающие движение центроидов.
К сожалению, Excel или Google Таблицы не идеальны для такого рода визуализации, и таблицы данных быстро становятся сложными для организации.
Если вы хотите увидеть полный пример с подробными графиками, вы можете прочитать эту статью, которую я написал почти три года назад, где наглядно показан каждый шаг движения центроида.

Как вы можете видеть на рисунке, рабочий лист стал совершенно неорганизованным, особенно по сравнению с предыдущей таблицей, которая была очень простой.

Выбор оптимального k: метод локтя
Итак, теперь можно попробовать k = 2 и k = 3 в нашем случае и вычислить инерцию для каждого из них. Затем мы просто сравниваем значения.
Мы даже можем начать с k=1.
Для каждого значения k:
- мы запускаем k-Means до сходимости,
- вычислить инерцию , которая представляет собой сумму квадратов расстояний между каждой точкой и назначенным ей центроидом.
В Excel:
- Для каждой точки возьмите расстояние до ее центроида и возведите его в квадрат.
- Сложите все эти квадраты расстояний.
- Это дает инерцию для этого k.
Например:
- при k = 1 центроид — это просто общее среднее значение x1 и x2,
- для k = 2 и k = 3 мы берем сходящиеся центроиды из листов, на которых вы запустили алгоритм.
Затем мы можем построить график инерции как функции k, например, для (k = 1, 2, 3).
Для этого набора данных
- от 1 до 2 инерция сильно падает,
- от 2 до 3 улучшение гораздо меньше.
«Локоть» — это значение k, после которого уменьшение инерции становится незначительным. В данном примере это означает, что k = 2 достаточно.

Заключение
Алгоритм K-средних очень интуитивно понятен, если вы увидите его пошагово в Excel.
Мы начинаем с простых центроидов, вычисляем расстояния, присваиваем точки, обновляем центроиды и повторяем. Теперь мы видим, как «машины обучаются», верно?
Что ж, это только начало: мы увидим, что разные модели «учатся» по-разному.
А вот и переход к завтрашней статье: неконтролируемая версия классификатора ближайшего центроида — это действительно k-средних .
Так что же представляет собой неконтролируемая версия LDA или QDA ? Мы ответим на этот вопрос в следующей статье.

Источник: towardsdatascience.com