От локального расстояния к глобальной вероятности
Делиться

После двух дней работы с k-NN (k-NN-регрессором и k-NN-классификатором) мы знаем, что подход k-NN очень наивен. Он хранит весь обучающий набор данных в памяти, использует только исходные данные о расстояниях и не анализирует никакую структуру данных.
Мы уже начали совершенствовать классификатор k-NN, и в сегодняшней статье мы реализуем эти различные модели:
- GNB: Гауссовский наивный байесовский
- LDA: линейный дискриминантный анализ
- QDA: квадратичный дискриминантный анализ
Во всех этих моделях распределение считается гауссовым. Поэтому в конечном итоге мы также увидим подход к получению более персонализированного распределения.
Если вы читали мою предыдущую статью, вот несколько вопросов для вас:
- Какова связь между LDA и QDA?
- Какова связь между GBN и QDA?
- Что произойдет, если данные вообще не являются гауссовыми?
- Каков метод получения персонализированного дистрибутива?
- Что линейно в LDA? Что квадратично в QDA?
При чтении статьи вы можете использовать эту таблицу Excel/Google.

Ближайшие центроиды: что на самом деле представляет собой эта модель
Давайте сделаем краткий обзор того, с чего мы начали вчера.
Мы представили простую идею: когда мы вычисляем среднее значение каждого непрерывного признака внутри класса, этот класс сворачивается в одну единственную репрезентативную точку.
Это дает нам модель ближайших центроидов.
Каждый класс суммируется по его центроиду — среднему значению всех его характеристик.
Теперь давайте подумаем об этом с точки зрения машинного обучения.
Обычно мы разделяем процесс на две части: этап обучения и этап настройки гиперпараметров.
Для ближайших центроидов мы можем нарисовать небольшую «карточку модели», чтобы понять, что эта модель на самом деле собой представляет:
- Как обучается модель? Вычисляя один средний вектор на класс. Ничего лишнего.
- Обрабатывает ли он пропущенные значения? Да. Центроид можно вычислить, используя все доступные (непустые) значения.
- Имеет ли значение масштаб? Да, безусловно, поскольку расстояние до центра масс зависит от единиц измерения каждого объекта.
- Какие гиперпараметры? Нет.
Мы сказали, что классификатор k-NN, возможно, не является настоящей моделью машинного обучения, поскольку он не является реальной моделью.
Что касается ближайших центроидов, то это не совсем модель машинного обучения, поскольку её невозможно настроить. Так что насчёт переобучения и недообучения?
Модель настолько проста, что она не может запоминать шум так же, как это делает k-NN.
Таким образом, метод ближайших центроидов будет давать недостаточную подгонку только в том случае, если классы сложны или недостаточно разделены, поскольку один центроид не может охватить их полную структуру.
Понимание формы класса с помощью одной особенности: добавление дисперсии
В этом разделе мы будем использовать только один непрерывный признак и 2 класса.
До сих пор мы использовали только один статистический показатель для каждого класса: среднее значение.
Давайте теперь добавим вторую часть информации: дисперсию (или, что то же самое, стандартное отклонение).
Это говорит нам о том, насколько «разбросан» каждый класс вокруг своего среднего значения.
Сразу возникает естественный вопрос: какую дисперсию нам следует использовать?
Наиболее интуитивный ответ — вычислить одну дисперсию для каждого класса , поскольку каждый класс может иметь различный разброс.
Но есть и другая возможность: мы могли бы вычислить одну общую дисперсию для обоих классов , обычно как средневзвешенное значение дисперсий классов.
Поначалу это кажется немного неестественным, но позже мы увидим, что эта идея напрямую ведет к LDA.
Итак, таблица ниже дает нам все, что нам нужно для этой модели, фактически, для обеих ее версий (LDA и QDA).
- количество наблюдений в каждом классе (для взвешивания классов)
- среднее значение каждого класса
- стандартное отклонение каждого класса
- и общее стандартное отклонение для обоих классов
С помощью этих значений вся модель полностью определена.

Теперь, когда у нас есть стандартное отклонение, мы можем построить более точное расстояние: расстояние до центроида , деленное на стандартное отклонение .
Зачем мы это делаем?
Потому что это дает расстояние, которое масштабируется в зависимости от того, насколько изменчив класс.
Если класс имеет большое стандартное отклонение, то неудивительно, что он находится далеко от своего центроида.
Если класс имеет очень малое стандартное отклонение, то даже небольшое отклонение становится значимым.
Эта простая нормализация превращает наше евклидово расстояние в нечто более осмысленное, представляющее форму каждого класса.
Это расстояние было введено Махаланобисом, поэтому мы называем его расстоянием Махаланобиса.
Теперь мы можем выполнить все эти расчеты прямо в файле Excel.

Формулы просты, и благодаря условному форматированию мы можем наглядно увидеть, как изменяется расстояние до каждого центра и как масштабирование влияет на результаты.

Теперь давайте построим несколько графиков, всегда в Excel.
На диаграмме ниже показана вся последовательность действий: как мы начинаем с расстояния Махаланобиса, переходим к вероятности при каждом распределении классов и, наконец, получаем прогноз вероятности.

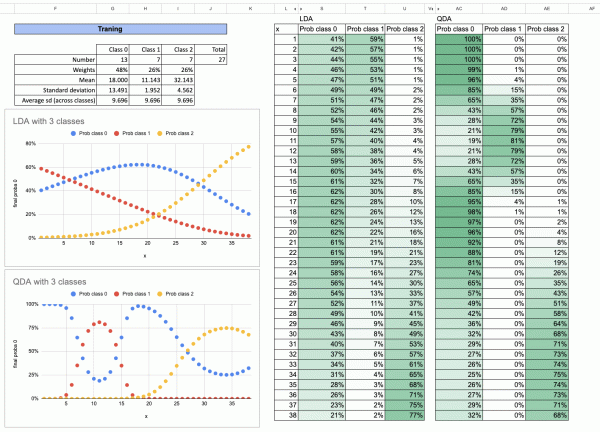
LDA против QDA, что мы видим?
Разницу можно легко увидеть, взглянув всего на одну особенность.
В методе LDA разделение по оси x всегда делится на две части. Поэтому метод называется линейным дискриминантным анализом.
Для QDA , даже с одним признаком, модель создаёт две точки отсечения на оси x. В более высоких измерениях это становится искривлённой границей, описываемой квадратичной функцией . Отсюда и название «квадратичный дискриминантный анализ».

И вы можете напрямую изменять параметры, чтобы увидеть, как они влияют на границу принятия решения.
Изменения средних значений или дисперсий изменят границу, и Excel позволяет легко визуализировать эти эффекты.
Кстати, напоминает ли вам форма кривой вероятности LDA какую-то модель, которую вы наверняка знаете? Да, она выглядит точно так же.
Вы уже догадываетесь, какой именно, да?
Но теперь возникает вопрос: действительно ли это одна и та же модель? И если нет, то чем они отличаются?

Мы также можем рассмотреть случай с тремя классами. Вы можете попробовать это самостоятельно в качестве упражнения в Excel.
Вот результаты. Для каждого класса мы повторяем одну и ту же процедуру. А для окончательного прогноза вероятности мы просто суммируем все вероятности и вычисляем долю каждой из них.

Опять же, этот подход используется и в другой известной модели.
Знаете, какая из них? Большинству людей она гораздо более знакома, и это показывает, насколько тесно связаны эти модели.
Когда вы понимаете один из них, вы автоматически гораздо лучше понимаете и остальные.
Форма класса в 2D: только дисперсия или также ковариация?
В одном случае мы не говорим о зависимости, поскольку её нет. В данном случае QDA ведёт себя точно так же, как наивный гауссовский байесовский алгоритм. Поскольку мы обычно допускаем, чтобы каждый класс имел свою собственную дисперсию, что совершенно естественно.
Разница станет очевидной при переходе к двум или более признакам. В этом случае мы будем различать случаи, в которых модель учитывает ковариацию между признаками.
Наивный гауссовский байесовский алгоритм делает одно очень сильное упрощающее предположение:
Эти функции независимы. Отсюда и слово «наивный» в названии.
Однако LDA и QDA не делают этого предположения. Они допускают взаимодействие между объектами, и именно это порождает линейные или квадратичные границы в более высоких измерениях.
Давайте выполним упражнение в Excel!
Гауссовский наивный байесовский алгоритм: без ковариации
Начнем с простейшего случая: гауссовский наивный байесовский алгоритм.
Таким образом, нам вообще не нужно вычислять какую-либо ковариацию, поскольку модель предполагает, что признаки независимы.
Чтобы проиллюстрировать это, рассмотрим небольшой пример с тремя классами.

QDA: каждый класс имеет свою собственную ковариацию
Для QDA теперь нам необходимо рассчитать ковариационную матрицу для каждого класса.
И как только мы его получим, нам также необходимо вычислить его обратную величину, поскольку она напрямую используется в формуле для расстояния и правдоподобия.
Таким образом, по сравнению с гауссовым наивным байесовским алгоритмом приходится вычислять еще несколько параметров.

LDA: все классы имеют одинаковую ковариацию
Для LDA все классы используют одну и ту же ковариационную матрицу, что сокращает количество параметров и делает границу решения линейной.
Несмотря на простоту модели, она остается весьма эффективной во многих ситуациях, особенно когда объем данных ограничен.

Индивидуальные распределения классов: за пределами гауссовского предположения
До сих пор мы говорили только о гауссовых распределениях. Это сделано для простоты. Мы также можем использовать другие распределения. Поэтому даже в Excel это очень легко изменить.
В действительности данные обычно не следуют идеальной гауссовой кривой.
Для исследования набора данных мы практически всегда используем эмпирические графики плотности. Они дают мгновенное визуальное представление о распределении данных.
А в качестве непараметрического метода часто используется ядерная оценка плотности (KDE) .
НО на практике KDE редко используется в качестве полноценной модели классификации. Он не очень удобен, а его предсказания часто зависят от выбора полосы пропускания.
И что интересно, эта идея ядер еще вернется, когда мы будем обсуждать другие модели.
Поэтому, хотя мы показываем его здесь в основном для исследования, это важный строительный блок в машинном обучении.

Заключение
Сегодня мы пошли по естественному пути, который начинается с простых средних значений и постепенно приводит к полным вероятностным моделям.
- Ближайшие центроиды сжимают каждый класс в одну точку.
- Наивный гауссовский байесовский алгоритм добавляет понятие дисперсии и предполагает независимость признаков.
- QDA дает каждому классу собственную дисперсию или ковариацию
- LDA упрощает форму, разделяя ковариацию.
Мы даже увидели, что можем выйти за рамки гауссовского мира и исследовать индивидуальные распределения.
Все эти модели объединены одной идеей: новое наблюдение принадлежит тому классу, на который оно больше всего похоже.
Разница заключается в том, как мы определяем сходство: по расстоянию, по дисперсии, по ковариации или по полному распределению вероятностей.
Для всех этих моделей мы можем легко выполнить два шага в Excel:
- Первый шаг — оценить параметры, которые можно рассматривать как обучение модели.
- шаг вывода, который заключается в расчете расстояния и вероятности для каждого класса

Еще одна вещь
Прежде чем закончить статью, давайте составим небольшую картографию моделей с дистанционным обучением.
У нас есть две основные семьи:
- локальные модели расстояний
- глобальные модели расстояний
Для локального расстояния нам уже известны два классических значения:
- регрессор k-NN
- классификатор k-NN
Оба метода прогнозируют, анализируя соседей и используя локальную геометрию данных.
Что касается глобального расстояния , все модели, которые мы изучали сегодня, относятся к классификационному миру.
Почему?
Поскольку глобальное расстояние требует центров, определяемых классами .
Мы измеряем, насколько близко новое наблюдение к каждому прототипу класса?
А как насчет регрессии ?
Кажется, что для регрессии понятие глобального расстояния не существует, или это действительно так?
Ответ – да, существует…

Источник: towardsdatascience.com