Модификация алгоритма Борута, которая значительно сокращает объем вычислений, сохраняя при этом высокую чувствительность.
Делиться

Эта статья – плод совместных усилий. Особая благодарность Эстевану Прадо, чей опыт помог доработать как технические концепции, так и повествовательную часть.
Введение
Отбор признаков остаётся одним из самых важных и в то же время ресурсоёмких этапов машинного обучения. При работе с многомерными наборами данных определение того, какие признаки действительно способствуют предсказательной силе, может определить, получится ли интерпретируемая и эффективная модель, а не переобученная и медленная.
В этой статье я представляю жадный алгоритм Борута — модификацию алгоритма Борута [1], которая в наших тестах сокращает время вычислений в 5–40 раз, при этом математически доказуемо сохраняя или улучшая полноту. С помощью теоретического анализа и имитационных экспериментов я демонстрирую, как простое ослабление критерия подтверждения обеспечивает гарантированную сходимость за O(-log α) итераций, где α — уровень достоверности биномиальных тестов, по сравнению с неограниченным временем выполнения ванильного алгоритма.
Алгоритм Boruta давно пользуется популярностью у специалистов по данным благодаря своему подходу «всех релевантных» признаков и статистической структуре. В отличие от минимально-оптимальных методов, таких как метод минимальной избыточности и максимальной релевантности (mRMR) и рекурсивное исключение признаков (RFE), которые ищут наименьший набор признаков для прогнозирования, Boruta стремится выявить все признаки, несущие полезную информацию. Это философское различие имеет огромное значение, например, когда целью является понимание явления, а не просто построение прогнозов.
Однако тщательность алгоритма Борута сопряжена с высокими вычислительными затратами. В реальных приложениях с сотнями или тысячами признаков сходимость алгоритма может потребовать чрезмерно много времени. Именно здесь на сцену выходит жадный алгоритм Борута.
Понимание ванильного алгоритма Боруты
Прежде чем рассмотреть модификацию, давайте вспомним, как работает базовый алгоритм Боруты.
Гениальность Boruta заключается в его элегантном подходе к определению важности признаков. Вместо того, чтобы полагаться на произвольные пороговые значения или p-значения, полученные непосредственно из модели, он создаёт конкурентоспособный бенчмарк, используя теневые признаки.
Вот процесс:
- Создание теневых признаков: для каждого признака в наборе данных Boruta создаёт «теневую» копию, случайным образом перемешивая его значения. Это разрушает любую связь исходного признака с переменной отклика (или целевой переменной), сохраняя при этом его распределение.
- Вычисление важности: алгоритм случайного леса обучается на объединённом наборе данных, и для всех признаков вычисляются значения важности. Хотя алгоритм Boruta изначально был предложен для оценки случайного леса, он может работать с любым другим ансамблем на основе деревьев, предоставляющим оценки важности признаков (например, Extra Trees [2], XGBoost [3], LightGBM [4]).
- Регистрация совпадений: для каждого объекта, не являющегося тенью, Борута проверяет, превышает ли его важность максимальную важность теней. Объектам, не являющимся тенями, но важнейшим, чем максимальная тень, присваивается статус «совпадения», а менее важным — статус «отсутствия совпадений».
- Статистическое тестирование: на основе списков совпадений и несовпадений для каждого из нетеневых объектов Борута выполняет биномиальный тест, чтобы определить, значительно ли его важность превышает максимальную важность среди теневых объектов за несколько итераций.
- Принятие решения: характеристики, которые стабильно превосходят лучшую теневую характеристику, помечаются как «подтверждённые». Характеристики, которые стабильно отстают от неё, «отклоняются». Характеристики посередине (те, которые статистически не отличаются от лучшей теневой характеристики) остаются «предварительно проверенными».
- Итерация: шаги 2–5 повторяются до тех пор, пока все признаки не будут классифицированы как подтверждённые или отклонённые. В этой статье я говорю, что алгоритм Боруты «сошелся», когда все признаки либо подтверждены, либо отклонёны, или когда достигнуто максимальное количество итераций.
Биномиальный тест: критерий решения Боруты
В базовой версии алгоритма Boruta используется строгий статистический подход. После нескольких итераций алгоритм выполняет биномиальный тест для совпадений для каждого из нетеневых признаков:
- Нулевая гипотеза: признак не лучше , чем лучший теневой признак (50% вероятность превзойти тени по случайности).
- Альтернативная гипотеза: данный признак лучше, чем лучший теневой признак.
- Критерий подтверждения: если значение p биномиального теста ниже α (обычно между 0,05–0,01), признак подтверждается.
Этот же процесс применяется и для отклонения объектов:
- Нулевая гипотеза: признак лучше , чем лучшая тень (50% вероятность того, что он не превзойдет тень по случайности).
- Альтернативная гипотеза: данный объект не лучше наилучшего теневого объекта.
- Критерий отклонения: если значение p биномиального теста ниже α, признак отклоняется.
Этот подход является статистически обоснованным и консервативным; однако он требует множества итераций для накопления достаточного количества доказательств, особенно для признаков, которые являются значимыми, но лишь незначительно лучше шума.
Проблема сходимости
Стандартный алгоритм Боруты сталкивается с двумя основными проблемами сходимости:
Длительное время выполнения: Поскольку биномиальный тест требует множества итераций для достижения статистической значимости, алгоритму могут потребоваться сотни итераций для классификации всех признаков, особенно при использовании малых значений α для высокой достоверности. Более того, нет никаких гарантий или оценок сходимости, то есть нет способа определить, сколько итераций потребуется для того, чтобы все признаки были отнесены к категориям «подтверждённые» или «отклонённые».
Предварительные характеристики: даже после достижения максимального количества итераций некоторые характеристики могут оставаться в категории «предварительные», оставляя аналитику неполную информацию.
Эти проблемы побудили к разработке жадного алгоритма Борута.
Алгоритм жадного Борута
Жадный алгоритм Борута вносит фундаментальное изменение в критерий подтверждения, которое значительно повышает скорость сходимости, сохраняя при этом высокую полноту.
Название алгоритма связано с его жадным подходом к подтверждению. Подобно жадным алгоритмам, принимающим локально оптимальные решения, жадный алгоритм Борута немедленно принимает любой многообещающий признак, не дожидаясь накопления статистических данных. Этот компромисс отдаёт предпочтение скорости и чувствительности, а не специфичности.
Смягченное подтверждение
Вместо того чтобы требовать статистическую значимость с помощью биномиального теста, жадный Boruta подтверждает любой признак, который превзошел максимальную теневую важность хотя бы один раз за все итерации, сохраняя при этом тот же критерий отбраковки.
Обоснование этого смягчения заключается в том, что при отборе «всех релевантных» признаков, как следует из названия, мы обычно отдаём приоритет сохранению всех релевантных признаков, а не удалению всех нерелевантных. Дальнейшее удаление нерелевантных признаков может быть выполнено с помощью алгоритмов отбора «минимально-оптимальных» признаков на последующих этапах конвейера машинного обучения. Следовательно, это смягчение практически обосновано и даёт ожидаемые результаты от алгоритма отбора «всех релевантных» признаков.
Это, казалось бы, простое изменение имеет несколько важных последствий:
- Поддерживаемая полнота: поскольку мы ослабляем критерий подтверждения (упрощая подтверждение признаков), мы никогда не сможем получить полноту ниже, чем у ванильного метода Boruta. Любой признак, подтверждённый ванильным методом, будет подтверждён и жадной версией. Это легко доказать, поскольку признак не может быть признан более важным, чем лучшая тень в биномиальном тесте без единого совпадения.
- Гарантированная сходимость за K итераций: как будет показано ниже, это изменение позволяет вычислить, сколько итераций потребуется, пока все признаки не будут либо подтверждены, либо отклонены.
- Более быстрая сходимость: как прямое следствие вышеизложенного, жадному алгоритму Борута требуется гораздо меньше итераций, чем обычному алгоритму Борута, для сортировки всех признаков. В частности, минимальное количество итераций, необходимое обычному алгоритму для сортировки «первой партии» признаков, равно минимальному количеству итераций, за которое жадная версия завершает работу.
- Упрощение гиперпараметров: ещё одним следствием гарантированной сходимости является то, что некоторые параметры, используемые в стандартном алгоритме Боруты, такие как max_iter (максимальное количество итераций), early_stopping (логическое значение, определяющее, следует ли алгоритму остановиться раньше, если за несколько итераций не наблюдается никаких изменений) и n_iter_no_change (минимальное количество итераций без изменений, после которых срабатывает ранняя остановка), могут быть полностью удалены без потери гибкости. Это упрощение повышает удобство использования алгоритма и упрощает управление процессом выбора признаков.
Модифицированный алгоритм
Алгоритм «Жадный Борута» следует следующему процессу:
- Создание теневых признаков: аналогично стандартному Boruta. Теневые признаки создаются на основе каждого признака набора данных.
- Вычисление важности: точно так же, как и в оригинальной версии Boruta. Оценки важности признаков вычисляются на основе любого ансамблевого алгоритма машинного обучения на основе дерева.
- Регистрация попаданий: Точно так же, как в оригинальной версии Boruta. Назначает попадания объектам, не являющимся тенями, но более важным, чем самый важный теневой объект.
- Статистическое тестирование: на основе списков несовпадений для каждого нетеневого объекта, Greedy Boruta выполняет биномиальный тест, чтобы определить, не превышает ли его важность значительно максимальную важность среди теневых объектов за несколько итераций.
- Принятие решения [Изменено]: признаки, имеющие хотя бы одно совпадение, подтверждаются. Признаки, которые стабильно показывают худшие результаты по сравнению с лучшей тенью, «отвергаются». Признаки с нулевым совпадением остаются «предварительными».
- Итерация: шаги 2–5 повторяются до тех пор, пока все признаки не будут классифицированы как подтвержденные или отклоненные.
Эта жадная версия основана на оригинальной реализации boruta_py [5] с несколькими изменениями, поэтому большинство вещей остались такими же, как в этой реализации, за исключением изменений, упомянутых выше.
Статистический анализ гарантии сходимости
Одним из самых элегантных свойств жадного алгоритма Борута является его гарантированная сходимость в течение определенного числа итераций, которое зависит от выбранного значения α.
Благодаря смягченному критерию подтверждения мы знаем, что любой признак с одним или несколькими совпадениями подтверждается, и нам не нужно проводить биномиальные тесты для подтверждения. И наоборот, мы знаем, что каждый пробный признак имеет ноль совпадений . Этот факт значительно упрощает уравнение, представляющее биномиальный тест, необходимый для отклонения признаков.
Более конкретно, биномиальный тест упрощается следующим образом. Учитывая описанный выше односторонний биномиальный тест для отклонения в стандартном алгоритме Боруты, где H₀ = p₀ и H₁ = p < p₀, p-значение рассчитывается следующим образом:

Эта формула суммирует вероятности наблюдения k успехов для всех значений от k = 0 до наблюдаемого x. Теперь, учитывая известные значения в этом сценарии (p₀ = 0,5 и x = 0), формула упрощается до:

Чтобы отвергнуть H₀ на уровне значимости α, нам необходимо:

Подставим наше упрощенное p-значение:

Берем обратную величину (и обращаем неравенство):

Логарифмируем обе части по основанию 2:

Таким образом, требуемый размер выборки составляет:

Это означает, что жадный алгоритм Борута выполняет не более ⌈ log₂(1/α)⌉ итераций до тех пор, пока все признаки не будут отсортированы как «подтверждённые» или «отклонённые» и не будет достигнута сходимость. Это означает, что сложность жадного алгоритма Борута составляет O(-log α).
Другим следствием отсутствия совпадений для всех предварительных признаков является тот факт, что мы можем дополнительно оптимизировать алгоритм, не проводя никаких статистических тестов между итерациями.
Более конкретно, зная α, можно определить максимальное количество итераций K, необходимое для отклонения переменной. Таким образом, для каждой итерации < K, если у переменной есть совпадение, это подтверждается, а если нет, то это предположение (поскольку p-значение для всех итераций < K будет больше α). Затем, ровно на итерации K, все переменные, имеющие 0 совпадений, можно перевести в категорию отклоненных без проведения биномиальных тестов, поскольку мы знаем, что на этом этапе все p-значения будут меньше α.
Это также означает, что для заданного α общее число итераций, выполняемых жадным алгоритмом Борута, равно минимальному числу итераций, необходимых для базовой реализации, чтобы подтвердить или отклонить любую функцию!
Наконец, важно отметить, что реализация boruta_py использует коррекцию FDR (коэффициент ложного обнаружения), чтобы учесть повышенную вероятность ложноположительных результатов при проверке нескольких гипотез. На практике требуемое значение K не совсем соответствует приведенному выше уравнению, но сложность по отношению к α по-прежнему логарифмическая.
В таблице ниже указано количество требуемых итераций для различных значений α с учетом примененной коррекции:

Имитационное моделирование экспериментов
Для эмпирической оценки жадного алгоритма Борута я провёл эксперименты с использованием синтетических наборов данных, истинные значения которых известны. Такой подход позволяет точно измерить производительность алгоритма.
Методология
Генерация синтетических данных: я создал наборы данных с известным набором важных и неважных признаков, используя функцию make_classification из sklearn, что позволяет напрямую вычислять метрики эффективности выборки. Более того, эти наборы данных включают «избыточные признаки» — линейные комбинации информативных признаков, которые несут предсказательную информацию, но не являются строго необходимыми для прогнозирования. В парадигме «всех релевантных» признаков эти признаки в идеале должны быть идентифицированы как важные, поскольку они содержат сигнал, даже если этот сигнал избыточный. Поэтому при оценке информативные и избыточные признаки рассматриваются вместе как «набор релевантных данных» при вычислении полноты.
Метрики: Оба алгоритма оцениваются по:
- Воспоминание (чувствительность): Какая доля действительно важных признаков была определена правильно?
- Специфичность: Какая доля действительно неважных характеристик была правильно отклонена?
- Оценка F1: гармоническое среднее значение точности и полноты, балансирующее между правильной идентификацией важных признаков и избеганием ложных срабатываний.
- Время вычислений: время выполнения по часам
Эксперимент 1 – Изменение α
Характеристики набора данных
X_orig, y_orig = sklearn.make_classification( n_samples=1000, n_features=500, n_informative=5, n_redundant=50, # МНОГО избыточных признаков, коррелирующих с информативными n_repeated=0, n_clusters_per_class=1, flip_y=0.3, # Некоторый шум меток class_sep=0.0001, random_state=42 )
Это представляет собой «сложную» задачу отбора признаков из-за высокой размерности (500 переменных), малого размера выборки (1000 образцов), небольшого количества релевантных признаков (разреженная задача, где около 10% признаков хоть как-то релевантны) и довольно высокого уровня шума меток. Важно создать такую «сложную» задачу для эффективного сравнения производительности методов, в противном случае оба метода достигают почти идеальных результатов всего за несколько итераций.
Используемые гиперпараметры
В этом эксперименте мы оцениваем, как алгоритмы работают с различными значениями α, поэтому мы оценили оба метода, используя значения α из списка [0,00001, 0,0001, 0,001, 0,01, 0,1, 0,2].
Что касается гиперпараметров алгоритмов Boruta и Greedy Boruta, оба используют sklearn ExtraTreesClassifier в качестве оценщика со следующими параметрами:
ExtraTreesClassifier( n_estimators: 500, max_thought: 5, n_jobs: -1, max_features: 'log2' )
Классификатор Extra Trees был выбран в качестве оценщика из-за его быстрого времени подгонки и того факта, что он более стабилен при рассмотрении задач оценки важности признаков [2].
Наконец, ванильный Boruta не использует раннюю остановку (этот параметр не имеет смысла в контексте Greedy Boruta).
Количество испытаний
Чистый алгоритм Боруты настроен на выполнение максимум 512 итераций, но с условием ранней остановки. Это означает, что если за X итераций (n_iter_no_change) не обнаружено никаких изменений, выполнение останавливается. Для каждого α значение n_iter_no_change определяется следующим образом:

Ранняя остановка включена, поскольку осторожный пользователь ванильного алгоритма Борута установил бы ее, если бы время выполнения алгоритма было достаточно велико, и это было бы более разумным использованием алгоритма в целом.
Эти пороги ранней остановки были выбраны для баланса между вычислительными затратами и вероятностью сходимости: меньшие пороги для больших значений α (где сходимость происходит быстрее) и большие пороги для меньших значений α (где для накопления статистической значимости требуется больше итераций). Это отражает то, как практический пользователь настраивал бы алгоритм, чтобы избежать неоправданно длительного времени выполнения.
Результаты: сравнение производительности

Ключевой вывод: как показано на крайней левой панели рисунка 1, жадный метод Boruta обеспечивает полноту, превышающую или равную полноте ванильного метода Boruta во всех экспериментальных условиях. Для двух наименьших значений α полнота одинакова, а для остальных значений жадный метод Boruta демонстрирует немного большую полноту, что подтверждает, что смягченный критерий подтверждения не пропускает признаки, которые мог бы обнаружить ванильный метод.
Наблюдаемый компромисс: Жадный алгоритм Борута демонстрирует умеренно более низкую специфичность в некоторых условиях, подтверждая, что ослабленный критерий действительно приводит к увеличению числа ложноположительных результатов. Однако величина этого эффекта меньше ожидаемой, в результате чего в этом наборе данных с 500 переменными выбираются всего 2–6 дополнительных признаков. Такой повышенный уровень ложноположительных результатов приемлем для большинства нисходящих конвейеров по двум причинам: (1) абсолютное количество дополнительных признаков невелико (2–6 признаков в этом наборе данных с 500 признаками) и (2) последующие этапы моделирования (например, регуляризация, перекрёстная проверка или выбор минимально-оптимальных признаков) могут отфильтровать эти признаки, если они не влияют на эффективность прогнозирования.
Ускорение: Жадный алгоритм Boruta стабильно требует в 5–15 раз меньше времени по сравнению с обычной реализацией, причём ускорение увеличивается при более консервативных значениях α. При α = 0,00001 улучшение приближается к 15-кратному. Также ожидается, что даже меньшие значения α приведут к ещё большему ускорению. Важно отметить, что для большинства сценариев с α < 0,001 обычная реализация Boruta «не сходится» (не все функции подтверждены или отклонены), и без ранней остановки алгоритм работал бы гораздо дольше.
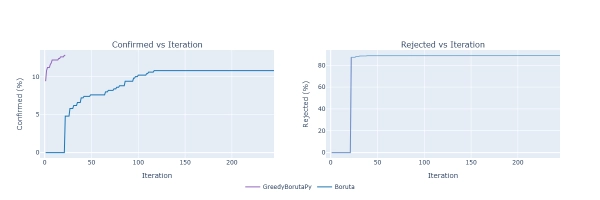
Сходимость: Мы также можем оценить, насколько быстро каждый из методов «сходится», проанализировав состояние переменных на каждой итерации, как показано на графике ниже:

В этом сценарии, используя α = 0,00001, мы можем наблюдать поведение, упомянутое выше: первое подтверждение/отклонение ванильного алгоритма происходит на последней итерации жадного алгоритма (отсюда полное перекрытие линий на графике отклонения).
Из-за логарифмического роста максимального числа итераций жадного алгоритма Boruta в терминах α, мы также можем исследовать экстремальные значения для α при использовании жадной версии:

Эксперимент 2 – Исследование максимального количества итераций
Параметры
В этом эксперименте использовались те же набор данных и гиперпараметры, что и в предыдущем, за исключением α, которое было зафиксировано на уровне α = 0,00001, а максимальное количество итераций (для ванильного алгоритма) менялось от запуска к запуску. Максимальное количество проанализированных итераций составило [16, 32, 64, 128, 256, 512]. Кроме того, ранняя остановка была отключена в этом эксперименте, чтобы продемонстрировать одну из слабых сторон ванильного алгоритма Боруты.
Важно отметить, что для этого эксперимента имеется только одна точка данных для жадного метода Борута, поскольку максимальное количество итераций само по себе не является параметром в модифицированной версии, поскольку оно однозначно определяется используемым α.
Результаты: сравнение производительности

Мы снова наблюдаем, что жадный алгоритм Boruta достигает более высокой полноты, чем ванильный алгоритм Boruta, при этом демонстрируя несколько меньшую специфичность, на протяжении всего количества рассмотренных итераций. В этом сценарии мы также наблюдаем, что жадный алгоритм Boruta достигает уровня полноты, аналогичного ванильному алгоритму, примерно за 4 раза быстрее.
Более того, поскольку в ванильном алгоритме нет «гарантии сходимости» при заданном количестве итераций, пользователь должен определить максимальное количество итераций, которое алгоритм будет выполнять. На практике сложно определить это количество, не зная истинного значения для важных признаков и возможного сопутствующего количества итераций, необходимого для ранней остановки. Учитывая эту сложность, чрезмерно консервативный пользователь может запустить алгоритм слишком много итераций без существенного улучшения качества отбора признаков.
В данном конкретном случае использование максимального количества итераций, равного 512, без преждевременной остановки, позволяет достичь полноты, очень похожей на ту, что была достигнута при 64, 128 и 256 итерациях. Сравнивая жадную версию с 512 итерациями ванильного алгоритма, мы видим 40-кратное ускорение при несколько большей полноте.
Когда использовать Жадного Боруту?
Жадный алгоритм Борута особенно ценен в определенных сценариях:
- Многомерные данные в условиях ограниченного времени: при работе с наборами данных, содержащими сотни или тысячи признаков, вычислительные затраты стандартного алгоритма Boruta могут быть непомерно высокими. Если для разведочного анализа или быстрого прототипирования требуются быстрые результаты, Greedy Boruta предлагает привлекательный компромисс между скоростью и точностью.
- Цели отбора всех релевантных признаков: если ваша цель соответствует изначальной философии «всех релевантных» признаков Боруты — поиску каждого признака, дающего некоторую информацию, а не минимального оптимального набора, — то высокая полнота алгоритма «Жадный Борута» — именно то, что вам нужно. Алгоритм отдаёт предпочтение включению, что уместно, когда удаление признаков требует больших затрат (например, в задачах научного открытия или причинно-следственного вывода).
- Рабочие процессы итеративного анализа: на практике выбор признаков редко бывает единовременным решением. Специалисты по анализу данных часто экспериментируют с различными наборами признаков и моделями, используя итерации. Жадный алгоритм Boruta обеспечивает быструю итерацию, предоставляя быстрые начальные результаты, которые можно уточнить в ходе последующего анализа. Кроме того, для дальнейшего снижения размерности набора признаков можно использовать другие методы выбора признаков.
- Несколько дополнительных признаков допустимы: строгий статистический анализ в базовом алгоритме Boruta ценен, когда ложные срабатывания обходятся особенно дорого. Однако во многих приложениях добавление нескольких дополнительных признаков предпочтительнее пропуска важных. Жадный алгоритм Boruta идеально подходит, когда нисходящий конвейер может обрабатывать немного большие наборы признаков, но выигрывает от более быстрой обработки.
Заключение
Алгоритм «Жадный Борута» — это расширение/модификация хорошо зарекомендовавшего себя метода отбора признаков, обладающего существенно другими свойствами. Ослабляя критерий подтверждения со статистической значимости до единственного совпадения, мы достигаем:
- В исследованных сценариях время выполнения в 5–40 раз быстрее по сравнению со стандартным Boruta.
- Равный или больший уровень полноты , гарантирующий, что никакие важные особенности не будут упущены.
- Гарантированное совпадение со всеми классифицированными признаками.
- Сохранена интерпретируемость и теоретическая обоснованность.
Компромисс — умеренное увеличение доли ложноположительных результатов — приемлем во многих реальных приложениях, особенно при работе с многомерными данными в условиях ограничений по времени.
Для практиков жадный алгоритм Борута представляет собой ценный инструмент для быстрого отбора высокополнотных признаков в разведочном анализе с возможностью использования более консервативных методов при необходимости. Для исследователей он демонстрирует, как продуманные модификации существующих алгоритмов могут дать значительные практические преимущества благодаря тщательному учёту реальных требований приложений.
Алгоритм наиболее эффективен, когда ваша философия направлена на поиск «всех релевантных» признаков, а не на поиск минимального набора, когда скорость имеет значение, а ложные срабатывания допустимы или могут быть отфильтрованы в ходе последующего анализа. В этих распространённых сценариях жадный алгоритм Boruta представляет собой убедительную альтернативу стандартному алгоритму.
Ссылки
[1] Курса, М.Б. и Рудницки, В.Р. (2010). Выбор признаков с помощью пакета Boruta. Журнал статистического программного обеспечения, 36(11), 1–13.
[2] Гертс П., Эрнст Д. и Вехенкель Л. (2006). Чрезвычайно рандомизированные деревья. Машинное обучение, 63(1), 3–42.
[3] Чен, Т. и Гестрин, К. (2016). XGBoost: масштабируемая система оптимизации деревьев. Труды 22-й Международной конференции ACM SIGKDD по поиску знаний и анализу данных, 785–794.
[4] Кэ, Г., Мэн, К., Финли, Т., Ван, Т., Чен, В., Ма, В., Йе, К. и Лю, Т.-Й. (2017). LightGBM: Высокоэффективное дерево решений с градиентным бустингом. Достижения в области нейронных информационных систем 30 (NIPS 2017), 3146–3154.
[5] Реализация BorutaPy: https://github.com/scikit-learn-contrib/boruta_py
Источник: towardsdatascience.com