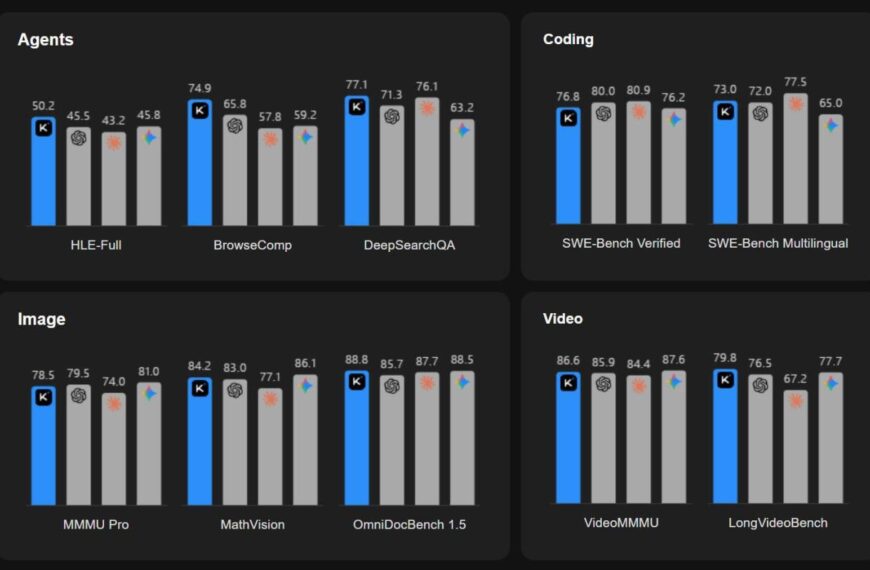
Как, зачем, что и где работает уровень доступа LLM от Amazon.
Делиться

На момент написания этого текста в начале 2026 года AWS включает в себя несколько взаимосвязанных, но при этом различных компонентов, составляющих ее агентные и LLM-абстракции.
- Bedrock — это слой модели, обеспечивающий доступ к большим языковым моделям.
- Agents for Bedrock — это управляемый уровень приложений. Другими словами, AWS запускает агенты для вас в соответствии с вашими требованиями.
- Bedrock AgentCore — это инфраструктурный уровень, позволяющий AWS запускать агентов, разработанных вами с использованием сторонних фреймворков, таких как CrewAI и LangGraph.
Помимо этих трех сервисов, AWS также предлагает Strands — библиотеку Python с открытым исходным кодом для создания агентов вне сервиса Bedrock, которые затем можно развернуть в других сервисах AWS, таких как ECS и Lambda.
Это может сбивать с толку, потому что все три сервиса, основанные на агентской модели, содержат в своих названиях термин «Bedrock», но в этой статье я сосредоточусь на стандартном сервисе Bedrock и покажу, как и зачем его использовать.
Сервис Bedrock стал доступен на AWS только в начале 2023 года. Это должно дать вам представление о причинах его внедрения. Amazon ясно видела рост популярности больших языковых моделей и их влияние на ИТ-архитектуру и процесс разработки систем. Это основная сфера деятельности AWS, и они были полны решимости не допустить, чтобы кто-то занял их место.
И хотя AWS разработала несколько собственных программ магистратуры в области прикладных наук (LLM), компания поняла, что для сохранения конкурентоспособности ей необходимо сделать доступными для пользователей самые лучшие модели, такие как модели Anthropic. И вот тут на помощь приходит Bedrock. Как они сами заявили на своем веб-сайте:
… Bedrock — это полностью управляемый сервис, предлагающий на выбор высокопроизводительные базовые модели (БМ) от ведущих компаний в области ИИ, таких как AI21 Labs, Anthropic, Cohere, Meta, Stability AI и Amazon, через единый API, а также широкий набор возможностей, необходимых для создания приложений генеративного ИИ, упрощающих разработку при сохранении конфиденциальности и безопасности.
Как получить доступ к Bedrock?
Итак, это теория, лежащая в основе Bedrock, но как получить к нему доступ и начать им пользоваться? Как и следовало ожидать, первое, что вам понадобится, — это учетная запись AWS. Я предполагаю, что она у вас уже есть, но если нет, перейдите по следующей ссылке, чтобы ее создать.
https://aws.amazon.com/account
Полезно отметить, что после регистрации новой учетной записи AWS значительная часть используемых вами сервисов будет относиться к так называемому «бесплатному уровню» AWS, а это значит, что ваши расходы должны быть минимальными в течение года после создания учетной записи — при условии, что вы не будете чрезмерно нагружать систему и запускать огромные вычислительные серверы и тому подобное.
Существует три основных способа использования сервисов AWS.
- Через консоль. Если вы новичок, это, вероятно, будет для вас предпочтительным способом, поскольку это самый простой способ начать работу.
- Через API. Если вы хорошо разбираетесь в программировании, вы можете получить доступ ко всем сервисам AWS через API. Например, для программистов на Python AWS предоставляет библиотеку boto3 . Существуют аналогичные библиотеки для других языков, таких как JavaScript и т. д.
- Через интерфейс командной строки (CLI). CLI — это дополнительный инструмент, который можно загрузить с сайта AWS и который позволяет взаимодействовать с сервисами AWS непосредственно из терминала.
Обратите внимание, что для использования двух последних методов вам необходимо настроить учетные данные для входа в систему на вашем локальном компьютере.
Что я могу сделать с Bedrock?
Вкратце, вы можете делать большинство вещей, которые можно делать с обычными моделями чата от OpenAI, Anthropic, Google и так далее. В основе Bedrock лежит ряд базовых моделей, которые вы можете использовать с ним, например:
- Мышление Кими К2. Модель глубокого рассуждения.
- Клод Опус 4.5. Для многих это лучшая магистерская программа, доступная на сегодняшний день.
- GPT-OSS. Магистр права в области открытого исходного кода от OpenAI.
И многое, многое другое. Полный список смотрите по следующей ссылке.
https://aws.amazon.com/bedrock/model-choice
Как использовать Bedrock?
Для работы с Bedrock мы будем использовать комбинацию AWS CLI и Python API, предоставляемого библиотекой boto3. Убедитесь, что у вас выполнена следующая предварительная настройка.
- Учетная запись WS.
- Инструмент командной строки AWS загружен и установлен в вашей системе.
- Для управления идентификацией и доступом (IAM) создается пользователь с соответствующими разрешениями и ключами доступа. Это можно сделать через консоль AWS.
- Настройте учетные данные пользователя через AWS CLI следующим образом. Как правило, необходимо указать три параметра. Все они будут получены на предыдущем шаге. Вам будет предложено ввести соответствующую информацию.
$ aws configure AWS Access Key ID [None]: AKIAIOSFODNN7EXAMPLE AWS Secret Access Key [None]: wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY Default region name [None]: us-west-2 Default output format [None]:
Предоставление Bedrock доступа к модели
Раньше (ещё несколько месяцев назад!) для запроса доступа к определённым моделям из Bedrock приходилось использовать консоль управления AWS, но теперь доступ предоставляется автоматически при первом вызове модели.
Обратите внимание, что для моделей Anthropic новым пользователям может потребоваться предоставить подробную информацию о сценарии использования, прежде чем они смогут получить доступ к модели. Также учтите, что доступ к лучшим моделям от Anthropic и других поставщиков будет платным, поэтому регулярно проверяйте свои счета и удаляйте доступ к моделям, который вам больше не нужен.
Однако нам все еще нужно знать название модели, которую мы хотим использовать. Чтобы получить список всех моделей, совместимых с Bedrock, мы можем использовать следующую команду AWS CLI.
aws bedrock list-foundation-models
В результате будет получен набор данных в формате JSON, содержащий список различных свойств каждой модели, примерно такой:
{ «modelSummaries»: [ { «modelArn»: «arn:aws:bedrock:us-east-2::foundation-model/nvidia.nemotron-nano-12b-v2», «modelId»: «nvidia.nemotron-nano-12b-v2», «modelName»: «NVIDIA Nemotron Nano 12B v2 VL BF16», «providerName»: «NVIDIA», «inputModalities»: [ «TEXT», «IMAGE» ], «outputModalities»: [ «TEXT» ], «responseStreamingSupported»: true, «customizationsSupported»: [], «inferenceTypesSupported»: [ «ON_DEMAND» ], «modelLifecycle»: { «status»: «ACTIVE» } }, { «modelArn»: «arn:aws:bedrock:us-east-2::foundation-model/anthropic.claude-sonnet-4-20250514-v1:0», … … …
Выберите нужную модель и запишите её идентификатор (modelID) из JSON-вывода, так как он понадобится нам позже в коде на Python. Важно отметить, что в описании модели часто встречается следующее:
… … «inferenceTypesSupported»: [ «INFERENCE_PROFILE» ] … …
Это относится только к моделям, которые:
- Крупные или пользуются высоким спросом
- Требуется зарезервированная или управляемая мощность.
- Необходимы четкие механизмы контроля затрат и пропускной способности.
Для этих моделей мы не можем просто ссылаться на идентификатор модели в нашем коде. Вместо этого нам нужно ссылаться на профиль вывода . Профиль вывода — это ресурс Bedrock, привязанный к одной или нескольким базовым LLM и региону.
Существует два способа получить профиль для вывода результатов, который вы можете использовать. Первый — создать его самостоятельно. Такие профили называются профилями приложений. Второй способ — использовать один из поддерживаемых профилей AWS. Это более простой вариант, поскольку он уже создан для вас, и вам нужно только получить соответствующий идентификатор профиля, связанный с профилем вывода результатов, чтобы использовать его в своем коде.
Если вы хотите создать профиль приложения самостоятельно, ознакомьтесь с соответствующей документацией AWS, но в моем примере кода я буду использовать поддерживаемый профиль.
Список поддерживаемых профилей в AWS можно найти по ссылке ниже:
https://docs.aws.amazon.com/bedrock/latest/userguide/inference-profiles-support.html#inference-profiles-support-system
В качестве первого примера кода я хочу использовать модель Sonnet 3.5 V2 от Клода, поэтому я щелкнул по строке выше и увидел следующее описание.

Я записал идентификатор профиля (us.anthropic.claude-3–5-sonnet-20241022-v2:0) и один из допустимых регионов-источников (us-east-1).
В двух следующих примерах кода я буду использовать открытую модель LLM от OpenAI для вывода текста и генератор изображений Titan от AWS для изображений. Ни одна из этих моделей не требует профиля вывода, поэтому вы можете просто использовать для них обычный идентификатор модели (modelID) в своем коде.
Примечание: Независимо от выбранной модели (или моделей), убедитесь, что для каждой из них в настройках региона AWS указано правильное значение.
Настройка среды разработки
Поскольку мы будем заниматься программированием, лучше изолировать свою рабочую среду, чтобы не мешать другим нашим проектам. Давайте сделаем это сейчас. Я использую Windows и менеджер пакетов UV, но вы можете использовать любой инструмент, с которым вам удобнее работать. Мой код будет запускаться в блокноте Jupyter.
uv init bedrock_demo —python 3.13 cd bedrock_demo uv add boto3 jupyter # Чтобы запустить ноутбук, введите следующее: uv run jupyter notebook
Использование Bedrock из Python
Давайте посмотрим, как работает Bedrock на нескольких примерах. Первый будет простым, и мы будем постепенно увеличивать сложность по мере продвижения.
Пример 1: Простой вопрос и ответ с использованием профиля вывода.
В этом примере используется модель Клода Соннета 3.5 V2, о которой мы говорили ранее. Как уже упоминалось, для вызова этой модели мы используем идентификатор профиля, связанный с ее профилем вывода.
import json import boto3 brt = boto3.client(«bedrock-runtime», region_name=»us-east-1″) profile_id = «us.anthropic.claude-3-5-sonnet-20241022-v2:0» body = json.dumps({ «anthropic_version»: «bedrock-2023-05-31», «max_tokens»: 200, «temperature»: 0.2, «messages»: [ { «role»: «user», «content»: [ {«type»: «text», «text»: «What is the capital of France?»} ] } ] }) resp = brt.invoke_model( modelId=profile_id, body=body, accept=»application/json», contentType=»application/json» ) data = json.loads(resp[«body»].read()) # Ответы Клода возвращаются в виде массив «content», а не «choices» OpenAI print(data[«content»][0][«text»]) # # Вывод # Столица Франции — Париж.
Обратите внимание, что использование этой модели (и других подобных ей) создает подразумеваемую подписку между вами и маркетплейсом AWS. Это не регулярная повторяющаяся плата. Она взимается только тогда, когда модель фактически используется, но лучше следить за этим, чтобы избежать неожиданных счетов. Вы должны получить электронное письмо с описанием соглашения о подписке и ссылкой для управления и/или отмены существующих подписок на модели.
Пример 2: Создание изображения
Простой пример создания образа с использованием собственной модели AWS Titan. Эта модель не связана с профилем вывода, поэтому мы можем просто сослаться на нее, используя ее идентификатор модели (modelID).
import json import base64 import boto3 brt_img = boto3.client(«bedrock-runtime», region_name=»us-east-1″) model_id_img = «amazon.titan-image-generator-v2:0» prompt = «Бегемот, едущий на велосипеде.» body = json.dumps({ «taskType»: «TEXT_IMAGE», «textToImageParams»: { «text»: prompt }, «imageGenerationConfig»: { «numberOfImages»: 1, «height»: 1024, «width»: 1024, «cfgScale»: 7.0, «seed»: 0 } }) resp = brt_img.invoke_model( modelId=model_id_img, body=body, accept=»application/json», contentType=»application/json» ) data = json.loads(resp[«body»].read()) # Titan возвращает изображения в кодировке base64 в массиве «images» img_b64 = data[«images»][0] img_bytes = base64.b64decode(img_b64) out_path = «titan_output.png» with open(out_path, «wb») as f: f.write(img_bytes) print(«Сохранено:», out_path)
На моей системе выходное изображение выглядело так.

Пример 3: Ассистент по сортировке обращений в техническую поддержку, использующий модель открытого программного обеспечения OpenAI.
Это более сложный и полезный пример. Здесь мы настроили помощника, который будет принимать сообщения о проблемах от нетехнических пользователей и выдавать дополнительные вопросы, на которые вы, возможно, захотите получить ответы от пользователя, а также наиболее вероятные причины проблемы и дальнейшие действия. Как и в нашем предыдущем примере, эта модель не связана с профилем вывода.
import json import re import boto3 from pydantic import BaseModel, Field from typing import List, Literal, Optional # —————————- # Настройка Bedrock # —————————- REGION = «us-east-2» MODEL_ID = «openai.gpt-oss-120b-1:0» brt = boto3.client(«bedrock-runtime», region_name=REGION) # —————————- # Схема вывода # —————————- Severity = Literal[«low», «medium», «high»] Category = Literal[«account», «billing», «device», «network», «software», «security», «other»] class TriageResponse(BaseModel): category: Category severity: Severity summary: str = Field(description=»One-sentence restatement of the problem.»») likely_causes: List[str] = Field(description=»Основные вероятные причины, кратко.») clarifying_questions: List[str] = Field(description=»Задавайте только то, что необходимо для продолжения.») safe_next_steps: List[str] = Field(description=»Пошаговые действия, безопасные для нетехнического пользователя.») stop_and_escalate_if: List[str] = Field(description=»Устранить тревожные сигналы, требующие обращения к специалисту/службе поддержки.») recommended_escalation_target: Optional[str] = Field( default=None, description=»Если уровень серьезности высок, к кому обратиться (например, к ИТ-администратору, в банк, к интернет-провайдеру.» ) # —————————- # Вспомогательные функции # —————————- def invoke_chat(messages, max_tokens=800, temperature=0.2) -> dict: body = json.dumps({ «messages»: messages, «max_tokens»: max_tokens, «temperature»: temperature }) resp = brt.invoke_model( modelId=MODEL_ID, body=body, accept=»application/json», contentType=»application/json» ) return json.loads(resp[«body»].read()) def extract_content(data: dict) -> str: return data[«choices»][0][«message»][«content»] def extract_json_object(text: str) -> dict: «»» Извлекает первый JSON-объект из выходных данных модели. Обрабатывает распространенные случаи, такие как блоки
Вот результат.
«категория»: «сеть», «серьезность»: «средняя», «краткое описание»: «Ноутбук показывает подключение к Wi-Fi, но не может загрузить веб-сайты, а Zoom сообщает о нестабильном соединении.» «вероятные причины»: [ «Неисправность маршрутизатора или модема», «Сбой разрешения DNS», «Локальные помехи Wi-Fi или слабый сигнал», «Конфликт IP-адресов в сети», «Брандмауэр или программное обеспечение безопасности блокирует трафик», «Сбой или ограничение скорости интернет-провайдера» ], «уточняющие вопросы»: [ «Могут ли другие устройства в той же сети Wi-Fi получить доступ к интернету?», «Проблема возникла после каких-либо недавних изменений (например, новое программное обеспечение, обновление ОС, установка VPN)?», «Вы пробовали переместиться ближе к маршрутизатору или использовать проводное Ethernet-соединение?», «Вы видите какие-либо коды ошибок или сообщения в браузере или Zoom, кроме сообщения «нестабильное соединение»?» ], «safe_next_steps»: [ «Перезагрузите маршрутизатор и модем, отключив их от сети на 30 секунд, а затем снова включите.» «На ноутбуке удалите сеть Wi-Fi, затем подключитесь снова и введите пароль.» «Запустите встроенное средство устранения неполадок сети Windows (Параметры → Сеть и Интернет → Состояние → Средство устранения неполадок сети).» «Временно отключите VPN или прокси и проверьте соединение еще раз.» «Откройте командную строку и выполните команду `ipconfig /release`, а затем `ipconfig /renew`.» «Очистите кэш DNS с помощью команды `ipconfig /flushdns`.» «Попробуйте зайти на простой веб-сайт (например, http://example.com) и обратите внимание, загружается ли он.» «Если возможно, подключите ноутбук к маршрутизатору через Ethernet, чтобы проверить, сохраняется ли проблема.» ], «stop_and_escalate_if»: [ «Ноутбук по-прежнему не может получить доступ ни к одному веб-сайту после выполнения всех шагов.» «Другие устройства в той же сети также не могут получить доступ к интернету.» «Вы получаете сообщения об ошибках, указывающие на сбой оборудования (например, адаптер Wi-Fi не найден).» «Маршрутизатор постоянно перезагружается или отображает индикаторы ошибок.» «Zoom продолжает сообщать о плохом или нестабильном соединении, несмотря на работающую проверку интернет-соединения.» ], «recommended_escalation_target»: «ИТ-администратор» }
Краткое содержание
В этой статье был представлен AWS Bedrock, управляемый шлюз AWS для создания базовых языковых моделей, а также объяснено, почему он существует и как он вписывается в общую концепцию. Стек AWS AI и его практическое применение. Мы рассмотрели обнаружение моделей, настройку регионов и учетных данных, а также ключевое различие между моделями по запросу и моделями, требующими профилей вывода — распространенный источник путаницы для разработчиков.
На практических примерах Python мы продемонстрировали генерацию текста и изображений с использованием как стандартных моделей по запросу, так и тех, которые требуют профиля вывода.
В своей основе Bedrock отражает давнюю философию AWS: абстрагирование сложности инфраструктуры без потери контроля. Вместо того чтобы навязывать единственную «лучшую» модель, Bedrock рассматривает базовые модели как управляемые компоненты инфраструктуры — взаимозаменяемые, управляемые и учитывающие региональные особенности. Это говорит о будущем, в котором Bedrock будет развиваться не столько как интерфейс чата, сколько как уровень оркестрации моделей, тесно интегрированный с IAM, сетями, контролем затрат и агентскими платформами.
Со временем можно ожидать, что Bedrock будет двигаться дальше в сторону стандартизации контрактов на выполнение задач (подписок) и более четкого разделения между экспериментальными и производственными мощностями. А благодаря сервисам Agent и AgentCore мы уже видим более глубокую интеграцию агентных рабочих процессов с Bedrock, позиционируя модели не как самостоятельные продукты, а как надежные строительные блоки в системах AWS.
Источник: towardsdatascience.com