
50 оттенков Директ-Лейк
Делиться

ОТКАЗ ОТ ОТВЕТСТВЕННОСТИ: Цель этой статьи — НЕ дать ответ на вопрос: «Что лучше — Import или Direct Lake?», поскольку на него невозможно ответить, поскольку не существует универсального решения… Хотя Import (по-прежнему) должен быть выбором по умолчанию в большинстве случаев, существуют определённые сценарии, в которых вы можете выбрать Direct Lake. Главная цель статьи — подробно рассказать о том, как работает режим Direct Lake, и пролить свет на различные концепции Direct Lake.
Если вы хотите узнать больше о сравнении Import (и DirectQuery) с Direct Lake и о том, когда следует выбирать один из них, я настоятельно рекомендую вам посмотреть следующее видео: https://www.youtube.com/watch?v=V4rgxmBQpk0
Теперь мы можем начать…
Не знаю, как вы, а я, когда смотрю фильмы и вижу захватывающие дух сцены, всегда задаюсь вопросом: как им удалось ЭТО сделать?! Какие трюки они вытащили из рукава, чтобы добиться такого результата?
И у меня такое же чувство, когда я наблюдаю за Direct Lake в действии! Тем из вас, кто, возможно, не слышал о новом режиме хранения семантических моделей Power BI или интересуется, что общего у Direct Lake и Аллена Айверсона, рекомендую начать с моей предыдущей статьи.
Цель этой статьи — пролить свет на то, что происходит за кулисами, как эта «штука» на самом деле работает, а также дать вам подсказку о некоторых нюансах, которые следует учитывать при работе с семантическими моделями Direct Lake.
Режим хранения Direct Lake устраняет недостатки режимов Import и DirectQuery, обеспечивая производительность, аналогичную режиму Import, без дублирования данных и задержек данных, поскольку данные извлекаются непосредственно из дельта-таблиц во время выполнения запроса.
Звучит как мечта, правда? Давайте попробуем рассмотреть различные концепции, которые позволят этой мечте стать реальностью…
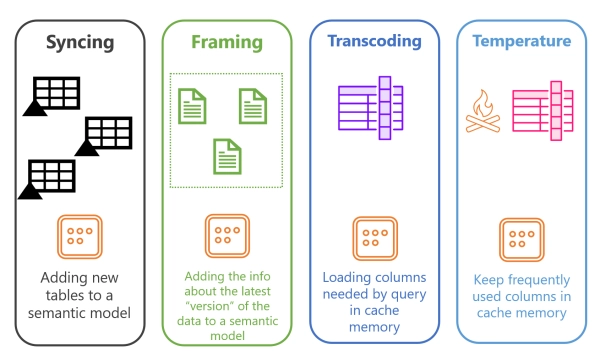
Фрейминг (он же Direct Lake «обновление»)
Самый частый вопрос, который я слышу от клиентов в последнее время: как обновить семантическую модель Direct Lake? Это справедливый вопрос. Они годами используют режим импорта, а Direct Lake обещает «производительность, подобную режиму импорта»… Значит, должен быть аналогичный процесс для поддержания актуальности данных, верно?
Ну, ja-in… (Что это, чёрт возьми, такое?), слышу я, вы уже задаётесь вопросом😀). У немцев есть идеальное слово (одно из многих, если честно) для обозначения чего-то, что может быть и «да», и «нет» ( ja = ДА, ne in = НЕТ). Крис Уэбб уже написал отличный пост в блоге на эту тему, поэтому я не буду повторяться (почитайте блог Криса, это один из лучших ресурсов для изучения Power BI). Моя идея — проиллюстрировать процесс, происходящий в фоновом режиме, и подчеркнуть некоторые нюансы, на которые могут повлиять ваши решения.
Но, обо всем по порядку…
Синхронизация данных
После создания Lakehouse в Microsoft Fabric вы автоматически получите два дополнительных объекта: конечную точку SQL Analytics для запросов к данным в Lakehouse (да, вы можете написать T-SQL для чтения данных из Lakehouse) и семантическую модель по умолчанию, содержащую все таблицы из Lakehouse. Что же происходит, когда в Lakehouse появляется новая таблица? Ну, это зависит от обстоятельств 🙂
Если открыть окно «Параметры» для конечной точки SQL Analytics и перейти к свойству «Семантическая модель Power BI по умолчанию», вы увидите следующую опцию:

Этот параметр позволяет определить, что происходит при поступлении новой таблицы в хранилище. По умолчанию эта таблица НЕ БУДЕТ автоматически включена в семантическую модель по умолчанию. И это первый момент, важный для «обновления» данных в режиме Direct Lake.
Сейчас в моём Lakehouse есть четыре дельта-таблицы: DimCustomer, DimDate, DimProduct и FactOnlineSales. Поскольку я отключил автоматическую синхронизацию между Lakehouse и семантической моделью, в семантической модели по умолчанию сейчас нет ни одной таблицы!

Это означает, что сначала мне нужно добавить данные в мою семантическую модель по умолчанию. После того, как я открою конечную точку SQL Analytics и выберу создание нового отчёта, мне будет предложено добавить данные в семантическую модель по умолчанию:

Хорошо, давайте посмотрим, что произойдёт, если в Lakehouse появится новая таблица? Я добавил в Lakehouse новую таблицу: DimCurrency.

Но когда я выбираю создание отчета на основе семантической модели по умолчанию, таблица DimCurrency недоступна:

Я включил опцию автоматической синхронизации, и через несколько минут таблица DimCurrency появилась в представлении объектов семантической модели по умолчанию:

Таким образом, эта опция синхронизации позволяет вам решить, будет ли новая таблица из lakehouse автоматически добавлена в семантическую модель или нет.
Синхронизация = Добавление новых таблиц в семантическую модель
Но что происходит с самими данными? То есть, если данные в дельта-таблице изменятся, нужно ли нам обновлять семантическую модель, как это приходилось делать при использовании режима импорта, чтобы в отчётах Power BI отображались актуальные данные?
Самое время познакомить вас с концепцией фрейминга. Но прежде давайте быстро рассмотрим, как хранятся наши данные изнутри. Я уже подробно рассказывал о формате файлов Parquet, поэтому здесь важно лишь отметить, что наша дельта-таблица DimCustomer состоит из одного или нескольких файлов Parquet (в данном случае двух), тогда как delta_log обеспечивает версионирование — отслеживание всех изменений, произошедших в таблице DimCustomer.

Я создал очень простой отчёт для изучения того, как работает фрейминг. В отчёте указаны имя и адрес электронной почты клиента Аарона Адамса:

Теперь я изменю адрес электронной почты в источнике данных с aaron48 на aaron048:

Давайте перезагрузим данные в Fabric lakehouse и проверим, что произошло с таблицей DimCustomer в фоновом режиме:

Появился новый файл parquet, одновременно в delta_log была создана новая версия.
Как только я вернусь к своему отчету и нажму кнопку «Обновить»…

Это произошло потому, что мои настройки по умолчанию для обновления семантической модели были настроены на включение обнаружения изменений в дельта-таблице и автоматического обновления семантической модели:

Что произойдёт, если я отключу эту опцию? Давайте проверим… Я верну адрес электронной почты aaron48 и перезагружу данные в Lakehouse. Во-первых, в delta_log есть новая версия файла, такая же, как и в предыдущем случае:

А если я сделаю запрос к озерному дому через конечную точку SQL Analytics, вы увидите последние включенные данные (aaron48):

Но если я перейду к отчету и нажму «Обновить»… я все еще увижу aaron048!

Поскольку я отключил автоматическое распространение последних данных из Lakehouse (OneLake) в семантическую модель, у меня есть только два варианта сохранить мою семантическую модель (и, следовательно, мой отчет) нетронутой:
- Снова включите опцию «Обновлять данные Direct Lake».
- Обновите семантическую модель вручную. Под «ручным» я подразумеваю именно ручное обновление, нажав кнопку «Обновить сейчас» или выполнив обновление программно (например, с помощью блокнотов Fabric или REST API) в рамках процесса оркестровки.
Почему вы хотите оставить эту опцию отключенной (как я сделал в последнем примере)? Ваша семантическая модель обычно состоит из нескольких таблиц, представляющих собой уровень обслуживания для конечного пользователя. И вам не обязательно, чтобы данные в отчёте обновлялись последовательно (таблица за таблицей), но, вероятно, после того, как вся семантическая модель будет обновлена и синхронизирована с исходными данными.
Этот процесс синхронизации семантической модели с последней версией дельта-таблицы называется фреймингом .

На иллюстрации выше вы видите файлы, которые в данный момент «обрамлены» в контексте семантической модели. После того, как новый файл попадает в хранилище (OneLake), для включения последнего файла в семантическую модель необходимо выполнить следующие действия.
Семантическая модель должна быть «рефреймирована» для включения последних данных. Этот процесс имеет ряд последствий, о которых вам следует знать. Во-первых, и это самое важное, при каждом фрейминге все данные, хранящиеся в памяти (речь идёт о кэш-памяти), извлекаются из кэша. Это имеет первостепенное значение для следующего понятия, которое мы обсудим, — транскодирования.
Далее, при фрейминге не происходит «реального» обновления данных…
В отличие от режима импорта, где запуск процесса обновления буквально помещает снимок физических данных в семантическую модель, фрейминг обновляет только метаданные! Таким образом, данные остаются в дельта-таблице OneLake (в семантическую модель Direct Lake данные не загружаются), мы лишь сообщаем нашей семантической модели: эй, там новый файл, забирайте его отсюда, когда вам понадобятся данные для отчёта… Это одно из ключевых различий между режимами Direct Lake и импорта.
Поскольку «обновление» Direct Lake — это всего лишь обновление метаданных, обычно это малозатратная операция, которая не должна занимать слишком много времени и ресурсов. Даже если у вас таблица с миллиардом строк, не забывайте: вы не обновляете миллиард строк в своей семантической модели, а обновляете только информацию об этой гигантской таблице…
Транскодирование — магия кэширования по требованию
Отлично, теперь, когда вы знаете, как синхронизировать данные из дома на озере с вашей семантической моделью (синхронизация) и как включить последние «данные о данных» в семантическую модель (фрейминг), пришло время понять, что на самом деле происходит за кулисами, когда вы запускаете свою семантическую модель в действие!
В этом и заключается преимущество Direct Lake, верно? Производительность режима импорта, но без копирования данных. Итак, давайте рассмотрим концепцию транскодирования…
Проще говоря: перекодирование представляет собой процесс загрузки частей дельта-таблицы (когда я говорю частей, я имею в виду определенные столбцы) или всей дельта-таблицы в кэш-память!
Позвольте мне остановиться здесь и рассмотреть приведенное выше предложение в контексте режима импорта:
- Загрузка данных в память (кэш) обеспечивает молниеносную производительность режима импорта.
- В режиме импорта, если вы не включили функцию семантической модели большого формата, вся семантическая модель сохраняется в памяти (она должна соответствовать ограничениям памяти), тогда как в режиме Direct Lake в памяти сохраняются только те столбцы, которые необходимы запросам !
Проще говоря: пункт первый означает, что после загрузки столбцов Direct Lake в память всё происходит абсолютно так же, как в режиме импорта (единственное потенциальное отличие может заключаться в том, как данные сортируются VertiPaq и как они сортируются в дельта-таблице)! Пункт второй означает, что объём кэш-памяти семантической модели Direct Lake может быть значительно меньше, а в худшем случае — таким же, как в режиме импорта (обещаю вскоре показать). Очевидно, что этот меньший объём памяти имеет свою цену — время ожидания первой загрузки визуального объекта, содержащего данные, которые необходимо «перекодировать» по запросу из OneLake в семантическую модель.
Прежде чем мы перейдём к примерам, вы, возможно, задаётесь вопросом: как это работает? Как данные, хранящиеся в дельта-таблице, могут быть прочитаны движком Power BI так же, как они были сохранены в режиме импорта?
Ответ таков: существует процесс, называемый транскодированием , который выполняется «на лету» при запросе данных Power BI. Этот процесс не слишком затратен, поскольку данные в файлах Parquet хранятся практически так же, как в VertiPaq (столбцовой базе данных, лежащей в основе Power BI и AAS). Кроме того, если данные записываются в дельта-таблицы с использованием алгоритма v-ordering (собственного алгоритма Microsoft для перестановки и сортировки данных для повышения производительности чтения), транскодирование делает данные из дельта-таблиц точно такими же, как если бы они хранились в собственном формате AAS.
Позвольте мне показать вам, как работает пагинация на практике. В этом примере я буду использовать набор медицинских данных, предоставленный Грегом Бомонтом (лицензия MIT. Зайдите на GitHub Грега, там полно потрясающих ресурсов). Таблица фактов содержит около 220 миллионов строк, а моя семантическая модель представляет собой хорошо продуманную схему «звезда».
Импорт против Direct Lake
Идея следующая: у меня есть две идентичные семантические модели (одинаковые данные, одни и те же таблицы, одни и те же связи и т. д.) — одна находится в режиме импорта, а другая — в Direct Lake.

Сейчас я открою Power BI Desktop и подключусь к каждой из этих семантических моделей, чтобы создать на их основе идентичный отчёт. Мне нужен инструмент Performance Analyzer в Power BI Desktop, чтобы захватывать запросы и анализировать их позже в DAX Studio.
Я создал очень простую страницу отчёта, содержащую только одну табличную визуализацию, которая показывает общее количество записей за год. В обоих отчётах я начинаю с пустой страницы, чтобы убедиться, что данные из кэша не извлекаются. Давайте сравним первый запуск каждой визуализации:

Как вы можете заметить, режим импорта работает немного лучше при первом запуске, вероятно, из-за накладных расходов на перекодирование при первой «разбивке» данных в режиме Direct Lake. Теперь я создам срез года в обоих отчётах, переключусь между разными годами и снова сравню производительность:

Разницы в производительности практически нет (данные были дополнительно протестированы с помощью функции Benchmark в DAX Studio)! Это означает, что после загрузки столбца из семантической модели Direct Lake в память он ведёт себя точно так же, как в режиме импорта.
Но что произойдёт, если мы включим в область действия дополнительный столбец? Давайте проверим эффективность обоих отчётов после того, как я добавлю показатель «Общая стоимость лекарств» в таблицу:

И в этом сценарии Import легко превосходит Direct Lake! Не забывайте, что в режиме Import вся семантическая модель загружалась в память, тогда как в Direct Lake загружались только необходимые запросу столбцы. В этом примере, поскольку общая стоимость лекарств не входила в исходный запрос, она не загружалась в память. После того, как пользователь включил её в отчёт, Power BI пришлось потратить некоторое время на перекодирование этих данных «на лету» из OneLake в VertiPaq и их размещение в памяти.
Объем памяти
Итак, мы также упомянули, что объём памяти, занимаемый семантическими моделями Import и Direct Lake, может существенно различаться. Позвольте мне вкратце объяснить, о чём я говорю. Сначала я проверю данные семантической модели в режиме Import с помощью VertiPaq Analyzer в DAX Studio:

Как видите, размер семантической модели составляет почти 4,3 ГБ! А если посмотреть на самые дорогие столбцы…

Столбцы «Tot_Drug_Cost» и «65 or Older Total» занимают почти 2 ГБ всей модели! Так что теоретически, даже если эти столбцы никто не использует в отчёте, они всё равно займут свою долю оперативной памяти (если только вы не включите опцию «Большая семантическая модель»).
Теперь я проанализирую семантическую модель DIrect Lake, используя тот же подход:

Ого, это в 4 раза меньше памяти! Давайте быстро проверим самые затратные столбцы в модели…

Давайте ненадолго остановимся здесь и рассмотрим результаты, представленные на иллюстрации выше. Столбец «Tot_Drug_Cst» занимает практически всю память этой семантической модели — поскольку мы использовали его в нашей табличной визуализации, он был выгружен в память. Но посмотрите на все остальные столбцы, включая «65 or Older Total», который раньше занимал 650 МБ в режиме импорта! Теперь это 2,4 КБ! Это всего лишь метаданные! Пока мы не используем этот столбец в отчёте, он не будет занимать оперативную память.
Это означает, что если мы говорим об ограничениях памяти в Direct Lake, мы имеем в виду максимальный лимит памяти на запрос ! Только если запрос превысит лимит памяти, установленный для вашего SKU Fabric, он перейдет на Direct Query (конечно, при условии, что ваша конфигурация соответствует настройке поведения резервного копирования по умолчанию):

Это ключевое различие между режимами Import и DIrect Lake. Возвращаясь к нашему предыдущему примеру, мой отчёт Direct Lake будет отлично работать с самым низким артикулом F (F2).
«Тебе то жарко, то холодно… Ты внутри, то снаружи…»
Есть известная песня Кэти Перри «Hot N Cold», где в припеве поётся: «Ты горяч, потом холоден… Ты внутри, потом ты снаружи…» Это идеально описывает, как колонны обрабатываются в режиме Direct Lake! Последнее, что я хочу вам рассказать, — это «температура» колонны.
Эта концепция имеет первостепенное значение при работе в режиме Direct Lake, поскольку на основе температуры столбцов движок решает, какие столбцы остаются в памяти, а какие возвращаются в OneLake.
Чем чаще запрашивается столбец, тем выше его температура! Чем выше температура столбца, тем больше вероятность, что он останется в памяти.
Марк Лелийвелд уже написал отличную статью на эту тему, поэтому я не буду повторять все детали, которые Марк прекрасно объяснил. Здесь я просто хочу показать вам, как проверить температуру определённых столбцов вашей семантической модели Direct Lake, и поделиться советами и приёмами, как поддерживать этот «огонь» 🙂
ВЫБЕРИТЕ ИЗМЕРЕНИЕ_ИМЯ, ИДЕНТИФИКАТОР_СТОЛБА, РАЗМЕР_СЛОВАРЯ, ТЕМПЕРАТУРА_СЛОВАРЯ, ПОСЛЕДНИЙ_ДОСТУП_К_СЛОВАРЮ ИЗ $SYSTEM.DISCOVER_STORAGE_TABLE_COLUMNS УПОРЯДОЧИТЬ ПО ТЕМПЕРАТУРА_СЛОВАРЯ ОПИСАНИЕ
Приведенный выше запрос к DMV Discover_Storage_Table_Columns может дать вам краткую подсказку о том, как работает концепция «Горячие N Холодные» в Direct Lake:

Как вы можете заметить, движок поддерживает словари столбцов взаимосвязей «теплыми» благодаря распространению фильтра. Есть также столбцы, которые мы использовали в визуальном представлении нашей таблицы: Year, Tot Drug Cst и Tot Clms. Если я ничего не делаю с отчётом, температура будет медленно снижаться со временем. Но давайте выполним некоторые действия в отчёте и снова проверим температуру:

Я добавил показатель «Общее количество претензий» (на основе столбца «Общее количество претензий») и изменил год в срезе. Давайте теперь посмотрим на температуру:

Ого, температура этих трёх столбцов в 10 раз выше, чем у столбцов, не используемых в отчёте. Таким образом, движок гарантирует, что наиболее часто используемые столбцы останутся в кэш-памяти, что обеспечивает наилучшую производительность отчёта для конечного пользователя.
Теперь возникает справедливый вопрос: что произойдет, когда все мои конечные пользователи уйдут домой в 5 часов вечера, и никто не прикоснется к семантическим моделям Direct Lake до следующего утра?
Что ж, первому пользователю придётся «пожертвовать» ради всех остальных и немного подождать первого запуска, а затем все смогут воспользоваться «тёплыми» столбцами, готовыми в кэше. Но что, если первый пользователь — ваш менеджер или генеральный директор?! No bueno:)
У меня хорошие новости: есть способ предварительно разогреть кэш, загрузив наиболее часто используемые столбцы заранее, сразу после обновления данных в OneLake. Мой друг Сандип Павар написал пошаговое руководство о том, как это сделать (Semantic Link в помощь), и вам обязательно стоит рассмотреть возможность внедрения этого метода, если вы хотите избежать негативного опыта для первого пользователя.
Заключение
Direct Lake — это действительно революционная функция, представленная в Microsoft Fabric. Однако, поскольку это совершенно новое решение, оно опирается на совершенно новый мир концепций. В этой статье мы рассмотрели некоторые из них, которые я считаю наиболее важными.
В заключение, поскольку я визуал, я подготовил иллюстрацию всех рассмотренных нами концепций:

Спасибо за прочтение!
Источник: towardsdatascience.com

























