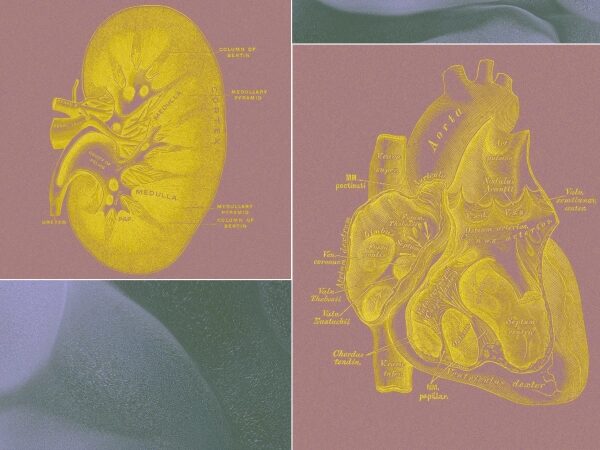
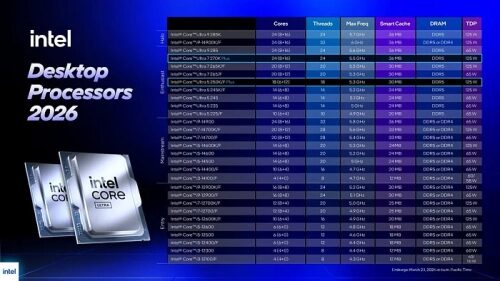
VLM выходят в реалтайм: теперь им хватает RTX 4060
FASTER — это попытка сделать визуально-языковые модели быстрыми не в теории, а в реальной работе.
Ключевой апгрейд — ускорение до уровня, где модель может реагировать в моменте.
Причём без датацентров: достаточно обычной RTX 4060.
Что сделали:
— сжали процесс выбора действий в один шаг
— убрали лишние итерации, которые тормозили отклик
— оптимизировали пайплайн под реальные задачи
Результат — модели начинают работать как реактивные системы, а не «подумал → ответил через секунду».
Зачем это нужно:
— роботы, которые реагируют на окружение сразу
— задачи вроде пинг-понга, где важны миллисекунды
— любые сценарии, где задержка убивает смысл
Да, роботы и раньше умели играть в пинг-понг.
Но это были узкоспециализированные системы.
Здесь речь про VLM общего назначения, которые внезапно начинают вести себя как «живые».
Главный сдвиг — интеллект становится не только умным, но и быстрым.
Вывод: как только модели научились думать в реальном времени, они начали подходить для физического мира. И это уже другой уровень применения.