
Заполнение пробелов в данных: подход машинного обучения к идентификации пыльцы в экологии и биотехнологии
Делиться

Авторы : Антони Ольбрыш, Кароль Струнявский, Томаш Вержбицкий
Оглавление
- Введение
- Доступные наборы данных изображений пыльцы
- Новый набор изображений пыльцы
- Извлечение отдельных изображений пыльцы
- Тонкая настройка YOLOv12
- Экспорт наборов данных по индивидуальной пыльце
- Наборы данных по индивидуальной пыльце — краткий анализ
- Классификация отдельных изображений пыльцы
- Обзор показателей оценки модели
- Индивидуальная классификация пыльцы с использованием стандартных моделей
- Индивидуальная классификация пыльцы с помощью сверточных нейронных сетей
- Индивидуальная классификация пыльцы с помощью Vision Transformers
- Сравнение показателей для различных моделей
- Выводы
- Подтверждение
1. Введение
Классификация пыльцы – интересная область визуального распознавания изображений, имеющая широкий спектр применения в экологии и биотехнологии, например, для изучения популяций растений, изменения климата и структуры пыльцы. Несмотря на это, эта тема относительно мало изучена, поскольку существует лишь небольшое количество наборов данных, содержащих изображения такой пыльцы, а те, что имеются, часто некачественные или иным образом недостаточны для обучения полноценного визуального классификатора или детектора объектов, особенно для изображений, содержащих смесь различных видов пыльцы. Помимо предоставления сложной модели визуальной идентификации, наш проект направлен на восполнение этого пробела с помощью специально разработанного набора данных. Визуальная классификация пыльцы часто бывает сложна для решения без машинного зрения, поскольку современные биологи зачастую не способны различать пыльцу разных видов растений, основываясь только на изображениях. Это делает задачу быстрого и эффективного распознавания собранной пыльцы чрезвычайно сложной, если источник пыльцевых частиц заранее неизвестен.
1.1 Доступные наборы данных изображений пыльцы
В этом разделе описываются параметры нескольких свободно доступных наборов данных и сравниваются со свойствами нашего пользовательского набора.
Набор данных 1
Ссылка: https://www.kaggle.com/datasets/emresebatiyolal/pollen-image-dataset
Количество классов: 193
Изображений в классе: 1–16
Качество изображения: Разделенные, четкие изображения, иногда с маркировкой
Цвет изображения: Разный
Примечания: Набор данных, по-видимому, состоит из несоответствующих изображений, полученных из разных источников. Несмотря на обширность классов, каждый из них содержит всего несколько фотографий, что недостаточно для обучения любой модели распознавания изображений.
Набор данных 2
Ссылка: https://www.kaggle.com/datasets/andrewmvd/pollen-grain-image-classification
Количество классов: 23
Изображений на класс: 35, 1 класс 20
Качество изображения: четкое разделение, слегка размытое, текст на изображениях отсутствует.
Цвет изображения: неокрашенный, равномерный
Примечания: Локализованный, хорошо подготовленный набор данных для классификации пыльцы бразильской саванны. Постоянный источник изображений, однако количество изображений в каждом классе может создавать проблемы при достижении высокой точности.
Набор данных 3
Ссылка: https://www.kaggle.com/datasets/nataliakhanzhina/pollen20ldet
Количество занятий: 20
Изображений по классу: Чрезмерно
Качество изображения: понятные изображения с отдельными и объединенными изображениями пыльцы.
Цвет изображения: окрашенный, равномерный
Примечания: Огромное количество хорошо размеченных, согласованных и высококачественных изображений делает этот набор данных высочайшего качества. Однако имеющаяся окраска может представлять проблему в некоторых приложениях. Кроме того, увеличение и способность пыльцы пересекаться могут создавать проблемы в случаях смешанной пыльцы.
2. Новый набор данных изображений пыльцы
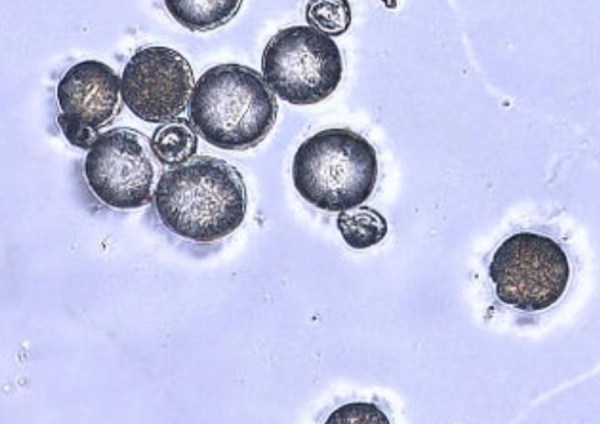
Наш набор данных представляет собой коллекцию высококачественных микроскопических изображений 4 различных классов пыльцы распространённых плодовых растений: европейского крыжовника, жимолости обыкновенной, чёрной смородины и ирги. Эти виды растений ранее не были представлены ни в одном из наборов данных, поэтому наш набор данных добавляет новые данные для визуальной классификации пыльцы.
Каждый класс содержит 200 изображений нескольких пыльцевых зёрен, каждое из которых без красителя. Изображение получено в сотрудничестве с Национальным институтом садоводческих исследований в Скерневице, Польша.
Количество классов: 5 (4 пыльцы + смешанные)
Изображений на класс: ~200
Качество изображения: четкие изображения, изображения содержат множественные фрагменты пыльцы, присутствуют смешанные изображения.
Цвет изображения: неокрашенный, равномерный
Наш набор данных ориентирован на локально доступную пыльцу, сбалансированность классов и обилие изображений для обучения без добавления красителя, что может сделать классификатор непригодным для некоторых задач. Кроме того, предлагаемое нами решение содержит изображения со смесью различных типов пыльцы, что облегчает обучение моделей обнаружения для полевых исследований. Примеры изображений из набора данных представлены на рисунках 1–4.




Полный набор данных можно получить у соответствующего автора по обоснованному запросу. Этапы получения данных включают подготовку образцов и получение микроскопических изображений, подготовленных профессором Агнешкой Марасек-Чиолаковской и г-жой Александрой Махляньской из Отдела прикладной биологии Национального института садоводческих исследований, за что мы им очень благодарны. Их усилия оказались неоценимыми для успеха нашего проекта.
3. Извлечение отдельных изображений пыльцы
Сначала мы извлекли изображения отдельных пыльц из фотографий в наших наборах данных, чтобы обучить различные модели распознавать пыльцу. На каждой из этих фотографий было изображено несколько видов пыльцы, а также другие формы жизни и загрязнения, что значительно затрудняло определение видов пыльцы. Мы использовали модель YOLOv12 — передовую модель обнаружения объектов в реальном времени, ориентированную на внимание, разработанную Ultralytics.
3.1 Тонкая настройка YOLOv12
Благодаря инновационной природе YOLOv12, его можно обучать даже на крошечных наборах данных. Мы столкнулись с этим явлением на собственном опыте. Чтобы подготовить наш собственный набор данных, мы вручную разметили местоположение пыльцы на десяти изображениях в каждом из четырёх классов нашего набора данных с помощью CVAT, а затем экспортировали метки в файлы .txt, соответствующие отдельным изображениям. Затем мы организовали наши данные в формате, подходящем для YOLOv12: мы разделили наши данные на обучающий набор (7 пар изображение-метка на класс, всего 28) и проверочный набор (3 пары изображение-метка на класс, всего 12). Мы добавили файл .yaml, указывающий на наш набор данных. Можно заметить, что набор данных был действительно очень маленьким. Полученное изображение в режиме прогнозирования с обнаруженными отдельными пыльцами и доверительным наложением представлено на рис. 5. Мы также загрузили модель (YOLO12s) с веб-сайта YOLOv12. Затем мы начали обучение.

Модель показала очень высокую точность обнаружения пыльцы, но нужно было учесть ещё один фактор: её достоверность. Для каждой обнаруженной пыльцы модель также выводила значение, характеризующее точность её прогноза. Нам нужно было решить, использовать ли более низкий порог достоверности (больше изображений, но выше риск появления некорректных или не пыльцевых фотографий) или более высокий (меньше изображений, но ниже вероятность обнаружения не пыльцы). В итоге мы остановились на двух пороговых значениях: 0,8 и 0,9, чтобы оценить, какой из них лучше подходит для обучения моделей классификации.
3.2 Экспорт наборов данных по индивидуальной пыльце
Для этого мы запустили прогнозирование модели на всех изображениях, специфичных для класса, в нашем наборе данных. Это сработало очень хорошо, но после экспорта мы столкнулись с другой проблемой: некоторые фотографии были обрезаны, даже при более высоких пороговых значениях. По этой причине мы добавили ещё один шаг перед экспортом отдельных пыльц: мы исключили изображения с непропорциональным соотношением сторон (см. пример на рис. 6). А именно, 0,8, то есть деление меньшего размера на больший.

Затем мы изменили размер всех изображений до 224×224 — стандартного размера входных изображений для моделей глубокого обучения.
3.3 Наборы данных по индивидуальной пыльце — краткий анализ
В итоге мы получили два набора данных, один с порогом достоверности 0,8, а другой — с 0,9:
- Порог 0,8:
- крыжовник — 7788 изображений
- ягода жимолости — 3582 изображения
- черная смородина — 4637 изображений
- ирга — 4140 изображений
Всего — 20147 изображений
- Порог 0,9:
- крыжовник — 2301 изображение
- ягода жимолости — 2912 изображений
- черная смородина — 2438 изображений
- ирга — 1432 изображения
Всего — 9083 изображения
Беглый взгляд на цифры показывает, что набор данных с порогом 0,9 более чем вдвое меньше набора с порогом 0,8. Оба набора данных не сбалансированы : набор с порогом 0,8 — из-за крыжовника, а набор с порогом 0,9 — из-за ирги.
YOLOv12 оказался эффективным инструментом для сегментации наших изображений на два набора изображений с одной пыльцой, несмотря на некоторые трудности. Новые наборы данных могут быть несбалансированными, но их размер должен компенсировать этот недостаток, главным образом благодаря широкому представлению каждого класса. Они обладают большим потенциалом для обучения моделей классификации в будущем, но нам ещё предстоит убедиться в этом самим.
4. Классификация отдельных изображений пыльцы
4.1 Обзор показателей оценки модели
Для правильного подхода к обучению моделей необходимо разработать метрики для измерения их эффективности, будь то классические модели, работающие со статистическими признаками, или более сложные подходы, такие как свёрточные нейронные сети или видеотрансформеры. За годы работы было разработано множество методов для решения этих задач — от статистических показателей, таких как F1, точность или полнота, до более визуальных метрик, таких как GradCAM, которые позволяют глубже понять внутреннюю работу модели. В этой статье рассматриваются методы оценки, используемые нашими моделями, без излишних подробностей.
Отзывать
Полнота определяется как отношение числа точных догадок одного класса к общему числу догадок этого класса (см. уравнение 1). Она измеряет процент изображений, помеченных как класс, принадлежащих ему. Работа с отдельными классами делает этот показатель функциональным как для сбалансированных, так и для несбалансированных наборов данных.

Уравнение 1 — Формула для припоминания.
Точность
В отличие от полноты, точность — это процент правильно угаданных элементов среди всех элементов класса (см. уравнение 2). Она измеряет процент элементов класса, которые были угаданы правильно. Эта метрика работает аналогично полноте.

Уравнение 2 — Формула точности.
Оценка F1
Оценка F1 — это просто среднее гармоническое значение точности и полноты (см. уравнение 3). Она помогает объединить точность и полноту в одно краткое измерение. Следовательно, она отлично работает даже на несбалансированных наборах данных.

Уравнение 3 — Формула для F1.
Матрица путаницы
Матрица ошибок — это визуальный показатель, сравнивающий количество предположений для одного класса с фактическим количеством изображений в этом классе. Она помогает проиллюстрировать ошибки, допускаемые моделью, которая может испытывать трудности только с определёнными маршрутами (см. рис. 7).

GradCAM
GradCAM — это метод измерения производительности сверточной нейронной сети (CNN), визуализирующий области изображения, влияющие на прогноз. Для этого метод вычисляет градиенты из одного свёрточного слоя и формирует карту активации, которая визуально накладывается поверх изображения. Это значительно помогает понять и объяснить «причины», по которым модель относит конкретное изображение к определённому классу (см. пример на рис. 8).

Эти метрики — лишь некоторые из огромного множества методов измерения и визуализации, используемых в машинном обучении. Тем не менее, они доказали свою эффективность для оценки эффективности модели. В следующих статьях метрики будут рассматриваться по мере внедрения и использования новых классификаторов в проекте.
4.2 Индивидуальная классификация пыльцы с использованием стандартных моделей
После предварительной обработки изображений мы могли перейти к следующему этапу: классификации отдельных пыльц по видам. Мы опробовали три подхода: стандартные простые классификаторы, основанные на признаках, извлечённых из изображений, свёрточные нейронные сети и Vision Transformers. В этой статье описывается наша работа со стандартными моделями, включая классификатор kNN, SVM, MLP и случайный лес.
Извлечение признаков
Чтобы наши классификаторы заработали, нам сначала нужно было получить признаки, на которых они могли бы основывать свои прогнозы. Мы остановились на двух основных типах признаков. Один из них — статистические показатели, основанные на наличии пикселей определённого цвета (из модели RGB) на конкретном изображении, такие как среднее значение, стандартное отклонение, медиана, квантили, асимметрия и эксцесс — мы извлекли их для каждого цветового слоя. Второй — признаки GLCM (матрицы совпадений уровней серого): контрастность, несходство, однородность, энергия и корреляция. Они были получены из изображений, преобразованных в оттенки серого, и мы извлекли каждый из них под разными углами. Каждое изображение содержало 21 статистический признак и 20 признаков, основанных на GLCM, что в сумме составляет 41 признак на изображение.
k-ближайших соседей (kNN)
kNN — это классификатор, который использует пространственное представление данных для их классификации путём обнаружения k ближайших соседей объекта для прогнозирования его метки. Этот классификатор быстр, но другие методы его превосходят.
Метрики kNN:
0.8 Набор данных:
Ф1: 0,6454
Точность: 0,6734
Отзыв: 0,6441
0.9 Набор данных:
Ф1: 0,6961
Точность: 0,7197
Напоминание: 0,7151
Машина опорных векторов (SVM)
Как и kNN, SVM представляет данные в виде точек в многомерном пространстве. Однако вместо поиска ближайших соседей он пытается алгоритмически разделить данные гиперплоскостью. Это даёт лучшие результаты, чем kNN, но вносит элемент случайности и всё ещё уступает другим решениям.
Метрики SVM:
0.8 Набор данных:
Ф1: 0,6952
Точность: 0,7601
Отзыв: 0,7025
0.9 Набор данных:
Ф1: 0,8556
Точность: 0,8687
Отзыв: 0,8597
Многослойный персептрон (MLP)
Многослойный персептрон — это модель, вдохновлённая человеческим мозгом и его нейронами. Она пропускает входные данные через сеть слоёв нейронов с индивидуальными весами, которые изменяются в процессе обучения. При хорошей оптимизации эта модель иногда может достигать отличных результатов для стандартного классификатора. Однако распознавание пыльцы не вошло в их число — результаты оказались хуже, чем у других решений, и нестабильны.
Метрики MLP:
0.8 Набор данных:
Ф1: 0,8131
Точность: 0,8171
Отзыв: 0,8173
0.9 Набор данных:
Ф1: 0,7841
Точность: 0,8095
Отзыв: 0,7940
Случайный лес
Модель случайного леса славится своей объяснимостью: она основана на деревьях решений, которые классифицируют данные на основе пороговых значений, которые людям гораздо проще анализировать, чем, например, весовые коэффициенты в нейронных сетях. Случайный лес показал себя довольно хорошо и стабильно: мы обнаружили, что оптимальное количество деревьев — 200. Тем не менее, он уступил более сложным классификаторам.
Показатели RF:
0.8 Набор данных:
Ф1: 0,8211
Точность: 0,8210
Отзыв: 0,8233
0.9 Набор данных:
Ф1: 0,8150
Точность: 0,8202
Отзыв: 0,8216
Классические модели продемонстрировали разную эффективность: некоторые оказались хуже ожидаемых, в то время как другие показали довольно хорошие результаты. Однако это ещё не всё. Нам ещё предстоит опробовать более сложные модели глубокого обучения, такие как свёрточные нейронные сети и Vision Transformers. Мы ожидаем, что они покажут значительно более высокую эффективность.
4.3 Индивидуальная классификация пыльцы с помощью сверточных нейронных сетей
Классические модели, такие как многослойные перцепторы (MLP), случайные леса (Random Forest) или опорные векторы (SVM), при классификации отдельных пыльц давали результаты от посредственных до довольно хороших. Однако следующим подходом, который мы решили попробовать, стали свёрточные нейронные сети (CNN). Эти модели генерируют признаки путём обработки изображений и известны своей эффективностью.
Вместо того, чтобы обучать сверточные нейронные сети с нуля, мы использовали метод трансферного обучения: взяли предварительно обученные модели, а именно ResNet50 и ResNet152, и подстроили их под наш набор данных. Такой подход значительно ускоряет обучение и снижает ресурсоёмкость. Он также позволяет проводить гораздо более эффективную классификацию, поскольку модели уже прошли профессиональное обучение на больших наборах данных. Перед обучением нам также пришлось нормализовать изображения.
Что касается метрик, мы использовали Grad-CAM — метод, который пытается выделить области изображения, наиболее повлиявшие на прогноз модели, в дополнение к стандартным метрикам, таким как оценка F1, точность и полнота. Мы также включили матрицы ошибок, чтобы проверить, испытывают ли наши сверточные нейронные сети трудности с каким-либо конкретным классом.
ResNet50
ResNet50 — это архитектура сверточных нейронных сетей, разработанная Microsoft Research Asia в 2015 году, что стало значительным шагом на пути к созданию гораздо более глубоких и эффективных нейронных сетей. Это остаточная сеть (отсюда и название ResNet), использующая пропуски связей для обеспечения прямого потока данных. Это, в свою очередь, смягчает проблему исчезающего градиента.
Мы ожидали, что эта модель будет работать хуже, чем ResNet152. Наши ожидания быстро разбились в пух и прах, поскольку модель дала прогнозы на том же уровне, что и ResNet152, для обоих наборов данных, что отражено в перечисленных ниже метриках и метриках путаницы (см. рис. 9 и рис. 10), а также в визуализации с помощью Grad-Cam (см. рис. 11).
Метрики ResNet50:
0.8 Набор данных:
Ф1: 0,98
Точность: 0,98
Отзыв: 0,98
0.9 Набор данных:
Ф1: 0,99
Точность: 0,99
Отзыв: 0,99



Что касается Grad-CAM, он не дал никакой ценной информации о внутренней работе модели — выделенные области включали фон и, казалось бы, случайные области. Благодаря очень высокой точности сеть, по-видимому, замечает закономерности, неразличимые человеческим глазом.
ResNet152
ResNet152, также являющаяся разработкой исследователей Microsoft, представляет собой остаточную сеть и архитектуру CNN со значительными возможностями глубины и глубокого обучения, намного превосходящими возможности ResNet50.
Поэтому наши ожидания от этой модели были выше, чем от ResNet50. Мы были разочарованы, обнаружив, что она показала результаты, сравнимые с ResNet50. Результаты оказались превосходными (см. рис. 12 и рис. 13 с матрицами неточностей и рис. 14 с визуализацией с помощью Grad-Cam).
Метрики ResNet152:
0.8 Набор данных:
Ф1: 0,98
Точность: 0,98
Отзыв: 0,98
0.9 Набор данных:
Ф1: 0,99
Точность: 0,99
Отзыв: 0,99



Grad-CAM также не оказался полезен для ResNet152 — мы столкнулись с загадочной природой моделей глубокого обучения, которые достигают высокой точности, но не могут быть легко объяснены.
Мы были удивлены, что более сложная модель ResNet152 не превзошла ResNet50 на наборе данных 0,9. Обе модели показали самые высокие результаты среди всех протестированных нами моделей — они превзошли классические модели, при этом разница между лучшей классической моделью и сверточным нейронным сеткой превысила 10 процентных пунктов. Пришло время протестировать самую инновационную модель — Vision Transformer.
4.4 Индивидуальная классификация пыльцы с помощью Vision Transformers
Для индивидуальной классификации пыльцы мы опробовали простые модели, которые обеспечивали различный уровень производительности — от недостаточного до удовлетворительного. Затем мы внедрили свёрточные нейронные сети, которые превзошли их по производительности. Теперь пришло время опробовать инновационную модель, известную как Vision Transformer.
Трансформеры, как правило, берут начало в знаменитой статье 2017 года «Внимание — это всё, что вам нужно» исследователей Google, но изначально они использовались преимущественно для обработки естественного языка. В 2020 году архитектура трансформера была применена в компьютерном зрении, что привело к появлению ViT — Vision Transformer. Его превосходная производительность ознаменовала начало конца господства свёрточных нейронных сетей в этой области.
Наш подход здесь был аналогичен подходу, использованному при обучении сверточных нейронных сетей. Мы импортировали предобученную модель vit-base-patch16–224-in21k, обученную на ImageNet-21k. Затем мы нормализовали изображения из нашего набора данных, провели их тонкую настройку и записали результаты метрических и матриц неточностей (см. рис. 15 и рис. 16).
vit-base-patch16–224-in21k результаты:
0.8 Набор данных:
Ф1: 0,98
Точность: 0,98
Отзыв: 0,98
0.9 Набор данных:
Ф1: 1.00
Точность: 1,00
Отзыв: 1.00


В наборе данных 0,8 Vision Transformer продемонстрировал уровень производительности, не превосходящий Residual Networks, и столкнулся с аналогичными проблемами — ошибочно классифицировал крыжовник как чёрную смородину. Однако в наборе данных 0,9 он показал практически идеальный результат. Мы стали свидетелями триумфа инноваций над устаревшими решениями, что побудило нас сохранить модель и выбрать её в качестве предпочтительной для более сложных задач.
4.5 Сравнение показателей для различных моделей
Для наших задач по классификации пыльцы мы использовали множество моделей: традиционные, включая kNN, SVM, MLP и Random Forest; свёрточные нейронные сети (ResNet50 и ResNet152) и Vision Transformer (vit-base-patch16–224-in21k). Данная статья содержит обзор и рейтинг производительности (см. табл. 1).

Рейтинг
6. kNN (k-ближайших соседей)
Самый простой классификатор. Как и ожидалось, он быстро обучился, но показал худшие результаты.
5. MLP (многослойный персептрон)
Архитектура модели основана на строении нервной системы человека. Многослойный перцептивный алгоритм (MLP) превзошёл другие стандартные модели, чего мы не ожидали.
4. RF (Случайный лес)
Классификатор Random Forest продемонстрировал наибольшую согласованность среди всех моделей, но его метрики были далеки от идеальных.
3. SVM (машина опорных векторов)
Неожиданный победитель среди типичных классификаторов. Его эффективность была случайной, но показала хорошие результаты для стандартного классификатора на наборе данных 0,9.
2. ResNet50 и ResNet152 (остаточные сети)
Обе архитектуры достигли одинаково высоких результатов благодаря своей сложности, значительно превзойдя возможности любого стандартного классификатора на обоих наборах данных.
1. ViT (Трансформатор зрения)
Самое инновационное решение, которое мы опробовали, превзошло классические модели и сравнялось с остаточными сетями на наборе данных 0,8. Однако настоящим испытанием стал набор данных 0,9, где сверточные нейронные сети достигли непревзойденной точности 0,99. К нашему удивлению, результаты Vision Transformer оказались настолько высокими, что их пришлось округлить до 1,00 — идеального результата. Его результаты — настоящее свидетельство силы инноваций.
Примечание: в отчёте о классификации метрики модели округлены. Они не равны точно 1, поскольку это означало бы, что все изображения без исключения были классифицированы правильно. Мы остановились на этом значении, поскольку лишь незначительная часть изображений (0,27%) была классифицирована неверно.
Сравнивая различные классификаторы в области визуального распознавания пыльцы, мы смогли лично ознакомиться с историей и развитием машинного обучения. Мы протестировали модели с разной степенью инновационности, начиная с простейших классификаторов и Vision Transformer, основанного на внимании, и заметили, как их результаты улучшались по мере повышения их новизны. На основании этого сравнения мы единогласно выбрали ViT в качестве модели для работы с пыльцой.
5. Выводы
Задача визуальной классификации пыльцы, которая долгое время была недоступна биологам по всему миру и находилась за пределами человеческих возможностей, наконец-то стала возможной благодаря машинному обучению. Все модели, представленные в нашей публикации, продемонстрировали потенциал для классификации пыльцы с разной степенью точности. Некоторые модели, такие как сверточные нейронные сети (CNN) или Vision Transformer, достигли практически совершенства, распознавая пыльцу с точностью, недоступной человеку.
Чтобы лучше понять, почему это достижение настолько впечатляет, мы проиллюстрируем его на рис. 17.

Весьма вероятно, что большинство читателей не смогут правильно классифицировать эти изображения по четырём упомянутым ранее классам. С другой стороны, наши модели распознают их практически с идеальной точностью, достигнув максимального значения F1 более 99%.
Возникает вопрос, для чего можно использовать такой классификатор и зачем его вообще обучали. Этот подход можно применять в самых разных областях: от отслеживания популяций растений до измерения уровня аллергенов в воздухе в локальном масштабе. Мы создали модели не только для того, чтобы палинологи могли использовать их инструмент для классификации собираемой пыльцы, но и чтобы предоставить другим энтузиастам машинного обучения исследовательскую платформу для дальнейшего развития и демонстрации постоянно расширяющихся возможностей применения этой области.
На этом мы завершаем публикацию. Мы искренне надеемся, что читатель найдет эту информацию полезной для своих исследований и что наши статьи вдохновят его на новые идеи для проектов, использующих эту технологию.
6. Благодарности
Мы выражаем искреннюю благодарность профессору Агнешке Марасек-Чиолаковской из Национального института садоводческих исследований в Скерневице, Польша, за подготовку образцов и получение их микроскопических изображений с помощью микроскопа Keyence VHX-5000. Авторы обладают полными, неограниченными авторскими правами на набор данных, использованный в данном исследовании, и все изображения, использованные в данной статье.
Источник: towardsdatascience.com

























