

Наша новая система искусственного интеллекта помогает ученым создавать эмпирическое программное обеспечение, достигая результатов экспертного уровня в шести разнообразных и сложных задачах.
Быстрые ссылки
- Бумага
- Интерактивный веб-сайт с визуализацией деревьев.
- Делиться
В научных исследованиях тщательная оценка гипотез имеет важное значение для разработки более надежных и всесторонних ответов, но необходимая работа становится узким местом, замедляющим темпы открытий. В частности, большая часть современных научных исследований зависит от вычислительных экспериментов для моделирования, имитации и анализа сложных явлений. В этом случае оценка гипотез часто требует создания специализированного программного обеспечения, что является медленной и сложной задачей. Учитывая растущие возможности больших языковых моделей (LLM) по выполнению традиционных задач кодирования, мы задались вопросом, могут ли они аналогичным образом генерировать высококачественное специализированное программное обеспечение для оценки и итеративного улучшения научных гипотез.
Сегодня мы публикуем статью, описывающую «систему искусственного интеллекта, разработанную для помощи ученым в написании эмпирического программного обеспечения экспертного уровня», созданную с использованием Gemini. Принимая на вход четко определенную задачу и метод оценки, наша система действует как систематический исследовательский механизм оптимизации кода: она может предлагать новые методологические и архитектурные концепции, реализовывать их в виде исполняемого кода и эмпирически проверять их производительность. Затем она осуществляет поиск и итерацию по тысячам вариантов кода, используя древовидный поиск для оптимизации производительности. Мы протестировали нашу систему, используя шесть бенчмарков, представляющих различные междисциплинарные задачи, охватывающие области геномики, общественного здравоохранения, геопространственного анализа, нейронауки, прогнозирования временных рядов и численного анализа. Наша система достигает экспертного уровня производительности по всем этим бенчмаркам.
Эмпирическое программное обеспечение и задачи с возможностью оценки результатов.
Научные исследования по своей природе итеративные, часто требующие от исследователей тестирования десятков или сотен моделей или параметров для достижения прорыва. Даже для ученых с опытом программирования написание кода, отладка и оптимизация программного обеспечения отнимают невероятно много времени. Ручное написание кода для каждой новой идеи — медленный и неэффективный процесс, что делает систематическое исследование потенциальных решений практически невозможным.
В основе нашей системы лежит фундаментальная концепция эмпирического программного обеспечения. В отличие от традиционного программного обеспечения, которое часто оценивается исключительно по функциональной корректности, эмпирическое программное обеспечение разрабатывается с основной целью: максимизировать заранее определенный показатель качества. Проблема или задача, которую можно эффективно решить с помощью эмпирического программного обеспечения, называется задачей, подлежащей оценке. Такие задачи широко распространены в науке, прикладной математике и инженерии.
Как это работает
Входными данными для нашей системы является оцениваемое задание, включающее описание проблемы, метрику оценки и данные, подходящие для обучения, валидации и оценки. Пользователь также может предоставить контекст, например, идеи из внешней литературы или указания по приоритезации методологий.
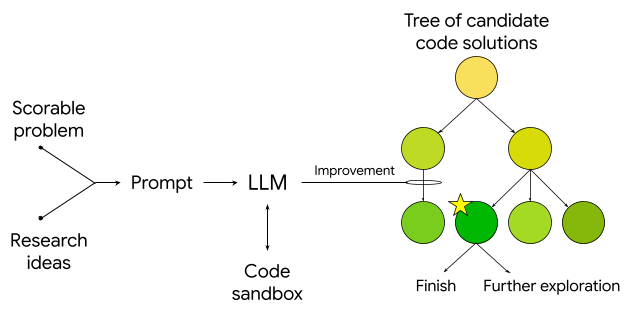
Система генерирует исследовательские идеи, включая программное воспроизведение, оптимизацию и рекомбинацию известных методов, что приводит к новым и высокопроизводительным подходам. Идеи реализуются в виде исполняемого кода, и система использует стратегию поиска по дереву с верхней границей достоверности (по аналогии с AlphaZero) для создания дерева кандидатов в программное обеспечение и определения, какие из них заслуживают дальнейшего изучения. Затем она использует LLM для переписывания кода с целью улучшения его оценки качества и может исчерпывающе и неустанно проводить поиск решений в беспрецедентном масштабе, быстро выявляя высококачественные решения и сокращая время поиска с месяцев до часов или дней. Ее результаты, в виде закодированных решений, являются проверяемыми, интерпретируемыми и воспроизводимыми.

Схема алгоритма, который передает оцениваемую задачу и исследовательские идеи в LLM, генерирующий код оценки в изолированной среде. Затем этот код используется в алгоритме поиска по дереву, где создаются новые узлы и итеративно улучшаются с помощью LLM.
Доказанная эффективность
Исторически оценка систем искусственного интеллекта, генерирующих код, фокусировалась на задачах, заимствованных из соревновательного программирования или разработки программного обеспечения, которые, хотя и ценны, не охватывают весь спектр проблем, присущих научным открытиям. Мы демонстрируем мастерство не просто в написании синтаксически корректного кода, но и в генерации новых решений шести разнообразных и сложных эталонных задач, которые расширяют границы современных вычислительных методов и человеческого опыта. Разнообразие этих эталонных задач позволяет нам коллективно оценить мастерство в таких областях, как обобщение без предварительного обучения, обработка сигналов в многомерном пространстве, количественная оценка неопределенности, семантическая интерпретация сложных данных и моделирование на системном уровне. Решения с наивысшими баллами для каждой из этих эталонных задач находятся в открытом доступе для всех, кто заинтересован в воспроизведении наших результатов, в том числе в виде интерактивного веб-сайта для изучения полных деревьев решений-кандидатов.
Геномика: пакетная интеграция данных секвенирования РНК отдельных клеток.
Секвенирование РНК отдельных клеток (scRNA-seq) — это мощная технология, обеспечивающая высокоточное представление экспрессии генов на уровне отдельных клеток. Основная проблема, возникающая при совместном анализе множества разрозненных наборов данных, заключается в устранении сложных эффектов пакетной обработки, присутствующих в разных образцах, при сохранении истинных биологических сигналов. Существует около 300 инструментов для пакетной интеграции данных scRNA-seq, и разработано множество бенчмарков для оценки показателей устранения эффектов пакетной обработки и сохранения биологической изменчивости. Используя бенчмарк пакетной интеграции OpenProblems V2.0.0, который объединяет 13 метрик в один общий балл, наша система обнаружила 40 новых методов, превзошедших лучшие методы, разработанные экспертами. Решение с наивысшим баллом показало общее улучшение на 14% по сравнению с лучшим опубликованным методом (ComBat) за счет успешного объединения двух существующих методов (ComBat и BBKNN).

Общий рейтинг методов, не являющихся контрольными, в бенчмарке OpenProblems v2.0.0. Синим цветом показаны результаты нашей системы с рекомбинацией идей и без нее, а также системы Gemini Deep Research . Нажмите , чтобы увеличить изображение.
Общественное здравоохранение: прогнозирование госпитализаций в США из-за COVID-19
Основным эталоном в США для прогнозирования COVID-19 является Центр прогнозирования COVID-19 (CovidHub), крупный совместный проект, координируемый Центрами по контролю и профилактике заболеваний (CDC). CovidHub привлекает разнообразные по методологии заявки от десятков команд экспертов. Их задача — прогнозировать новые случаи госпитализации из-за COVID-19 во всех штатах и территориях США на срок до месяца вперед. Эти прогнозы оцениваются с помощью средневзвешенной интервальной оценки (WIS), которая оценивает качество вероятностных прогнозов, суммируя эффективность модели по всем регионам для каждого еженедельного прогноза в течение сезона. Затем отдельные заявки объединяются в модель CovidHub Ensemble, которая считается золотым стандартом в США для прогнозирования госпитализаций из-за COVID-19. Наша система сгенерировала 14 моделей, которые превосходят официальную модель CovidHub Ensemble.

Таблица результатов прогнозирования COVID-19, отображающая еженедельные показатели эффективности прогнозирования команд, участвующих в проекте, упорядочена по абсолютному среднему значению WIS (число в каждой ячейке). Показатели суммированы по 52 юрисдикциям и четырем горизонтам прогнозирования. Цвет фона ячейки визуализирует эффективность относительно ансамбля CovidHub: синий цвет указывает на более низкое (лучшее) значение WIS, а красный — на более высокое (худшее) значение WIS. Наш метод, представленный в верхней строке таблицы (Google Retrospective), превосходит ансамбль CovidHub. Нажмите , чтобы увеличить изображение.
Геопространственный анализ: сегментация изображений дистанционного зондирования.
Семантическая сегментация изображений дистанционного зондирования высокого разрешения — распространенная задача в геопространственном анализе, имеющая важное значение для самых разных приложений, от мониторинга землепользования и оценки воздействия человеческой деятельности на окружающую среду до управления стихийными бедствиями. Эта задача, включающая точное присвоение меток классов отдельным пикселям изображения, требует от модели пространственного и контекстного понимания сцены, позволяющего определить не только наличие объектов, но и точное местоположение их границ.
Используя эталонный набор данных дистанционного зондирования с плотной разметкой (DLRSD), который оценивает методы с помощью среднего пересечения над объединением (mIoU), три лучших решения, сгенерированные нашей системой, немного превосходят современные передовые методы, с mIoU более 0,80. Все три решения основаны на существующих моделях, библиотеках и стратегиях. Два из них используют стандартные модели UNet++ и U-Net, но в сочетании с мощными кодировщиками, предварительно обученными на ImageNet. Третье использует SegFormer, современную архитектуру на основе Transformer. Все три решения используют обширную аугментацию во время тестирования (TTA).

Входными данными для моделей сегментации данных дистанционного зондирования является изображение ( верхний ряд ), а выходными — новое изображение, часто называемое маской сегментации, где каждому пикселю присваивается определенная метка класса. Средний ряд — это истинная маска, полученная в результате тестирования DLRSD. Нижний ряд — это маски сегментации, сгенерированные с использованием решения с наивысшим баллом нашей системы. Модели сегментации с высоким баллом будут иметь близкое визуальное сходство с истинной маской.
Нейробиология: прогнозирование нейронной активности всего головного мозга
Мы применили наш метод к бенчмарку прогнозирования активности рыбок данио (ZAPBench), недавно разработанному бенчмарку для прогнозирования активности более 70 000 нейронов во всем мозге позвоночных. Наша система обнаружила новую модель прогнозирования временных рядов, которая показала лучшие результаты, превзойдя все существующие базовые показатели. Это включает в себя вычислительно сложную модель на основе видеоданных, которая прогнозирует 3D-объемы и ранее была лучшим решением. В качестве подтверждения концепции мы также продемонстрировали, что наша система может создавать гибридные модели, включающие биофизический симулятор нейронов (Jaxley), что открывает путь к созданию более интерпретируемых прогностических моделей.
Хотя каждый из этих примеров сам по себе убедителен, наша система генерации эмпирического программного обеспечения поражает своей обобщаемостью. Мы также оценили нашу систему в контексте математики на задаче численного вычисления сложных интегралов. В этой задаче наша система сгенерировала решение, которое правильно вычислило 17 из 19 отложенных интегралов, где стандартный численный метод не сработал. Наконец, мы оценили нашу систему на общей задаче прогнозирования временных рядов, используя General Time Series Forecasting Model Evaluation (GIFT-Eval), эталонный набор данных, полученный из 28 наборов данных, охватывающих семь различных областей, с 10 различными частотами, от секунд до лет. Наша система успешно создала с нуля единую универсальную библиотеку прогнозирования, используя метод восхождения по склону с помощью одного кода на основе средней абсолютной масштабированной ошибки по всему набору данных GIFT-Eval. Подробнее см. в статье.
Заключение
Последние достижения в области линейных моделей обучения (ЛМО) уже предоставили исследователям по всему миру новые способы легкого взаимодействия со знаниями и идеями, и ЛМО все чаще используются как средство автоматизации рутинных и трудоемких аспектов научных исследований. Мы исследовали, могут ли ЛМО быть полезны для повсеместной, важной и чрезвычайно трудоемкой задачи создания специализированного программного обеспечения для оценки и итеративного улучшения научных гипотез, руководствуясь возможностью будущего, в котором ученые смогут легко, быстро и систематически исследовать сотни или тысячи потенциальных решений вопросов и проблем, которые мотивируют их исследования. Наша система быстро генерирует решения экспертного уровня, сокращая время, необходимое для изучения набора идей, с месяцев до часов или дней. Это обещает значительно сэкономить время для ученых, от студентов до профессоров, чтобы они могли сосредоточиться на действительно творческих и критических задачах, а также продолжать определять и расставлять приоритеты в фундаментальных исследовательских вопросах и социальных проблемах, в решении которых может помочь научная работа.
Благодарности
Мы благодарим и отмечаем вклад всех соавторов рукописи. Благодарим Шибла Мурада, Джона Платта, Эрику Бранд, Кэтрин Чоу, Ронит Левави Морад, Йосси Матиаса и Джеймса Маника за их поддержку и руководство.
Источник: research.google





















