
Набор данных и конвейер для сравнительного анализа с использованием синтетических персон для понимания и оптимизации производительности LLM в отношении тропических и инфекционных заболеваний (TRINDs).
Быстрые ссылки
- Бумага
- Делиться
Крупные языковые модели (КГМ) продемонстрировали потенциал для решения медицинских и медико-санитарных задач, охватывающих различные медицинские тесты и различные форматы и источники информации. Действительно, мы находимся в авангарде усилий по расширению возможностей применения КГМ в здравоохранении и медицине, что подтверждается нашей недавней работой над Med-Gemini, MedPaLM, AMIE, Multimodal Medical AI, а также выпуском новых инструментов и методов оценки производительности моделей в различных контекстах. Особенно в условиях ограниченных ресурсов КГМ могут служить ценными инструментами поддержки принятия решений, повышая точность клинической диагностики, доступность и многоязычную поддержку принятия клинических решений, а также обучение в сфере здравоохранения, особенно на уровне сообщества. Однако, несмотря на их успех на существующих медицинских эталонах, остается некоторая неопределенность относительно того, насколько хорошо эти модели обобщаются на задачи, связанные с изменением распределения типов заболеваний, региональными медицинскими знаниями и контекстными вариациями симптомов, языка, местоположения, языкового разнообразия и локализованных культурных контекстов.
Тропические и инфекционные заболевания (ТРИЗ) являются примером такой подгруппы заболеваний, не имеющих широкого распространения. ТРИЗ широко распространены в беднейших регионах мира, поражая 1,7 миллиарда человек во всем мире, при этом непропорционально сильно затрагивая женщин и детей. Проблемы в профилактике и лечении этих заболеваний включают ограничения в эпидемиологическом надзоре, ранней диагностике, точном первичном диагнозе , лечении и вакцинации. Линейные модели поведения (ЛМП) для ответов на вопросы, связанные со здоровьем, потенциально могут обеспечить ранний скрининг и эпидемиологический надзор на основе симптомов, местоположения и факторов риска человека. Однако было проведено лишь ограниченное количество исследований для понимания эффективности ЛМП в отношении ТРИЗ, и существует мало наборов данных для строгой оценки ЛМП.
Для решения этой проблемы мы разработали синтетические персоны — то есть наборы данных, представляющие профили, сценарии и т. д., которые можно использовать для оценки и оптимизации моделей, — а также методологии сравнительного анализа для подгрупп заболеваний, выходящих за рамки стандартного распределения. Мы создали набор данных TRINDs, состоящий из более чем 11 000 персон, созданных вручную и с помощью LLM, представляющих широкий спектр тропических и инфекционных заболеваний с учетом демографических, контекстных, географических, языковых, клинических и потребительских характеристик. Часть этой работы была недавно представлена на семинарах NeurIPS 2024 по генеративному искусственному интеллекту для здравоохранения и достижениям в области базовых медицинских моделей.
воспроизведение видео без звука зацикливание пауза видео без звука зацикливание включение звука видео выключение звука
Обзор разработки набора данных TRINDs и сравнительного анализа.
Создание синтетических персон TRINDs для оценки кандидатов на получение степени магистра права.
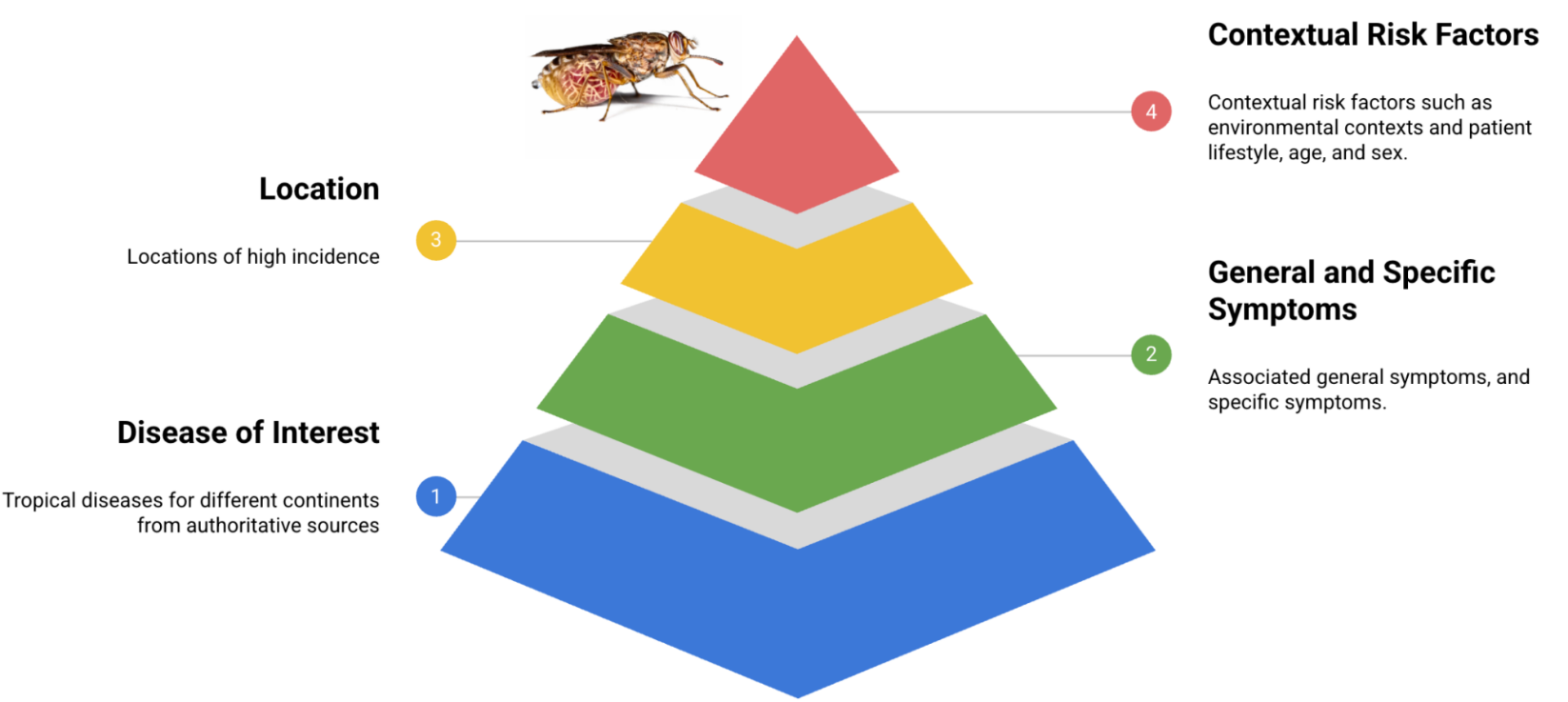
Мы изучили авторитетные источники, включая ВОЗ, ПАНО и CDC, которые публикуют достоверную информацию о различных заболеваниях, и использовали полученные данные для создания первоначального набора шаблонов профилей пациентов для каждого заболевания. Эти профили включают общие симптомы, прямые характеристики и конкретные симптомы. Они также включают контекст, образ жизни и факторы риска, которые были проверены врачами для подтверждения точности и клинической значимости формата профилей. В настоящее время эти первоначальные шаблоны охватывают 50 заболеваний.

Основные компоненты набора данных TRINDs.
Мы используем метод LLM-подсказок для расширения исходного набора синтетических персон, включив в него демографические и семантические клинические и потребительские данные (см. ниже), в результате чего общее количество персон достигло более 11 000. Кроме того, мы вручную перевели исходный набор на французский язык, чтобы оценить, как изменения в распределении языков влияют на производительность модели. Затем мы разработали авторегрессионный алгоритм на основе LLM, который оценивает ответ как правильный, если истинные значения и прогнозируемый диагноз совпадают или имеют существенное сходство.

Примеры исходного образа персонажа и его дополнений к LLM.
Оценка
Результаты экзаменов LLM на TRINDS по сравнению с USMLE
Мы оцениваем точность моделей Gemini (Gemini 1.5) в идентификации заболевания, указанного на основе описаний персон. Мы демонстрируем, что на этом наборе данных наблюдаются сдвиги в распределении производительности моделей по сравнению с эталонными наборами данных на основе USMLE, при этом на наборе данных TRINDs наблюдается более низкая производительность по сравнению с заявленной производительностью на американских наборах данных.
Значимость контекста
Мы систематически проводим оценки с использованием набора данных, чтобы понять влияние различных контекстов, типов (клинические и потребительские), демографических характеристик (возраст, раса, пол) и семантических стилей. Мы изучаем, как комбинации симптомов, факторов риска, местоположения и демографических данных влияют на точность LLM для обеспечения точной диагностики при полном или частичном контексте. Оценки показывают, что включение местоположения и факторов риска в сочетании со специфическими и общими симптомами приводит к наилучшим результатам, что предполагает, что одних симптомов может быть недостаточно для точных ответов.

Эффективность модели на контекстных комбинациях симптомов (общих и специфических), местоположения, факторов риска и демографических характеристик. S = симптомы, L = местоположение, A = характеристики, R = факторы риска, gS = общие симптомы, sS = специфические симптомы, FP = полная характеристика личности со всем контекстом. Погрешности указаны в 95% доверительном интервале. Примечание: точность FP также значительно выше, чем у S, SA и gSLAR.
Результаты в зависимости от расы, пола и гипотетического местоположения
Мы изучили влияние включения формулировки, указывающей на расу, например, «Я — чернокожий» или «Пациент — азиат по расовой принадлежности» . Мы также заменили гендерные обозначения и оценили влияние использования женской, мужской и небинарной лексики на результаты. Мы не обнаружили статистически значимой разницы в результатах в зависимости от расы и пола. Мы также изучили влияние указания мест с низкой частотой инцидентов (контрфактическое местоположение) на результаты, описанное в статье.

Результаты применения LLM в подгруппах по расе и полу в исследованиях TRIND не демонстрируют существенных различий. Погрешность = 95% доверительный интервал.
Оценка и оценка работы экспертов-людей
Мы привлекли 7 экспертов с более чем 10-летним опытом работы в области TRIND и общественного здравоохранения для ответа на открытые вопросы с краткими ответами (SAQ) и вопросы с множественным выбором (MCQ). Мы оценили результаты работы пяти лучших экспертов, а также сгенерировали показатели эффективности LLM на том же подмножестве данных. Это позволило смоделировать различные сценарии проведения экспертных круглых столов.

Сравнение результатов работы LLM (Gemini) с результатами пяти лучших экспертов, которые характеризовались четырьмя показателями: 1) средний балл по всем экспертам (Exp_Total); 2) максимальный балл, если большинство голосов было верным (Exp_Majority); 3) максимальный балл, если хотя бы один эксперт дал правильный ответ (Exp_Any); и 4) максимальный балл только в том случае, если все эксперты дали правильный ответ (Exp_All), что позволило нам изучить различные сценарии принятия решений экспертами. Погрешности указаны в 95% доверительном интервале.
Хотя специалисты с дипломом магистра права (LLM) показали худшие результаты на экзамене TRIND, чем на USMLE, они превзошли лучшего эксперта и большинство сценариев с различными комбинациями экспертов, за исключением сценария Exp_Any, который является более подходящим критерием для сравнения, поскольку отражает ситуацию, когда эксперты в области общественного здравоохранения, каждый из которых специализируется в определенной области, собираются вместе для принятия решений.
Показатели эффективности при различных заболеваниях
Мы обнаружили, что модели LLM, как правило, более точно определяют распространенные заболевания (например, ВИЧ) или заболевания со специфическими симптомами и факторами риска (например, бешенство). Некоторые заболевания, такие как заражение ленточными червями, более подвержены неточной маркировке, если указаны только симптомы. Кроме того, некоторые заболевания (например, бешенство) более устойчивы к контрфактическим условиям, чем другие.

На рисунке показана эффективность LLM в отношении тропических и инфекционных заболеваний при различных комбинациях контекстов ( слева ), комбинациях контекстов с контрфактическим местоположением ( в центре ) и эффективности работы эксперта ( справа ). Комбинации контекстов сокращены, как указано выше.
Повышение эффективности обучения на уровне магистратуры посредством обучения в контексте.
Мы настраиваем LLM (Gemini 1.5) с помощью контекстного обучения, используя простые многократные подсказки и начальный набор из 50 вопросов (по одному на каждое заболевание), содержащих все симптомы, локализации и факторы риска. Это улучшает производительность как при демографическом, так и при семантическом дополнении, демонстрируя, что этот пробел можно устранить с помощью целенаправленной настройки и что начальные наборы данных могут быть использованы для оптимизации производительности LLM.

Результаты на наборах данных, дополненных демографическими ( слева ) и семантическими ( справа ) данными, до и после контекстной настройки. Всего = 10 570, клинические демографические данные (n=2635), потребительские демографические данные (n=2635), клинические семантические данные (n=2650) и потребительские семантические данные (n=2650). Погрешность = 95% доверительный интервал.
Оценка потенциала инструментов на основе LLM для скрининга заболеваний.
Мы разработали пользовательский интерфейс для скрининга заболеваний TRINDs, работающий на версии Gemini, оптимизированной для этой задачи. Он позволяет пользователям легко вводить свои демографические данные, местоположение, информацию об образе жизни и факторах риска, а затем выбирать симптомы из исчерпывающего списка и получать диагноз. Мы подключили инструмент к API Our World in Data для отображения показателей заболеваемости.
воспроизведение видео без звука зацикливание пауза видео без звука зацикливание включение звука видео выключение звука
Пользовательский интерфейс и примеры использования инструмента на основе LLM для скрининга тропических и инфекционных заболеваний.
На данном раннем этапе оценки экспертов (приведены ниже) показывают, что интерфейс, несмотря на кажущуюся простоту в реализации, имеет потенциал стать весьма эффективным и удобным справочным инструментом по инфекционным заболеваниям, полезным как для врачей, так и для исследователей.

Экспертная оценка инструмента TRINDs.
Подразумеваемое
Для медицинских работников наши результаты подчеркивают потенциал инструментов на основе языков многоязычия в качестве ценных инструментов поддержки принятия решений в условиях ограниченных ресурсов. Однако эти инструменты должны дополнять, а не заменять клиническое суждение. Их следует уравновешивать непрерывной оценкой и регулярно обновлять, чтобы учитывать временные изменения в реальных условиях и обеспечивать надежность в различных клинических ситуациях. Учитывая чувствительность результатов, связанных со здоровьем, крайне важно оценивать языки многоязычия на предмет точности, контекстуальности и культурной релевантности. С учетом этих соображений, перевод описанного здесь подхода в клинический инструмент потребует дальнейшей валидации и стандартных процессов нормативного регулирования. Будущие направления исследований включают расширение критериев оценки для охвата многоязычности и мультимодальности.
Благодарности
Мы хотели бы выразить благодарность авторам и участникам этой работы: Мерси Асиеду, Ненаду Томасеву, Тие Тиясиричокчай, Чинтану Гхате, Аве Диенг, Кэтрин Хеллер, Мариане Перрони, Дивлин Джеджи, Хизер Коул-Льюис. Благодарим наших внешних экспертов Олуватосина Аканде, Джеффри Сиво, Стива Адуданса, Сильвануса Эйткинса, Одианосена Эхиахамена и Эрика Ндомби. Благодарим Мариан Кроак за ее поддержку и руководство.
Источник: research.google