
Введение
Каждый разработчик знает эту ситуацию. Вы сделали небольшую правку, создали Pull Request и… ждёте. Иногда ревью затягивается, потому что коллеги заняты, а иногда оно превращается в рутинный пинг-понг из-за пропущенной точки с запятой или несоответствия стайлгайду. Рутинные проверки отнимают драгоценное время и концентрацию, которые можно было бы потратить на обсуждение архитектуры и бизнес-логики.
А что, если делегировать эту первую, самую механическую линию обороны машине? Что, если бы у нас был неутомимый ассистент, который мгновенно проверял бы новый код и указывал на очевидные недочёты?
В этой статье мы с нуля создадим именно такого ассистента. Это не будет очередной «hello world» на модную тему. Это будет подробный, основанный на реальном опыте гайд по созданию Node.js-сервиса, который слушает вебхуки GitHub, отправляет код на анализ большой языковой модели (LLM) и публикует результаты в виде построчных комментариев к Pull Request.
Наш технологический стек:
Node.js: Простой, быстрый старт и идеальная асинхронная модель для I/O-bound задач, таких как ожидание ответов от внешних API.
GitHub: Де-факто стандарт для контроля версий с мощной и гибкой системой вебхуков.
OpenRouter: Универсальный шлюз к десяткам языковых моделей. Он позволяет не привязываться к одному API (например, OpenAI) и даёт доступ к отличным бесплатным моделям, на одной из которых мы и построим наш сервис.
AI-модель: Мы будем использовать qwen/qwen-2.5-72b-instruct:free — одну из бесплатных моделей, доступных на OpenRouter, которая отлично справляется с анализом кода.
Главная ценность этой статьи — в деталях. Я покажу не только «как надо», но и «как бывает». Мы вместе пройдём через все грабли, на которые я наступил в процессе: будем, отлаживать невалидные подписи вебхуков и, самое интересное, «приручать» LLM, которая не всегда следует инструкциям и возвращает JSON в самых причудливых форматах.
Эта статья — проводник в мир реальной автоматизации разработки. Пристегните ремни, мы начинаем.
Часть 1: Фундамент — Наш первый сервер.
Прежде чем ловить события из внешнего мира, нам нужно построить дом, в котором мы будем их обрабатывать. Этот «дом» — наш Node.js сервер. А его «мозг» — это функция, которая умеет общаться с языковой моделью.
Шаг 1: Идея и архитектура
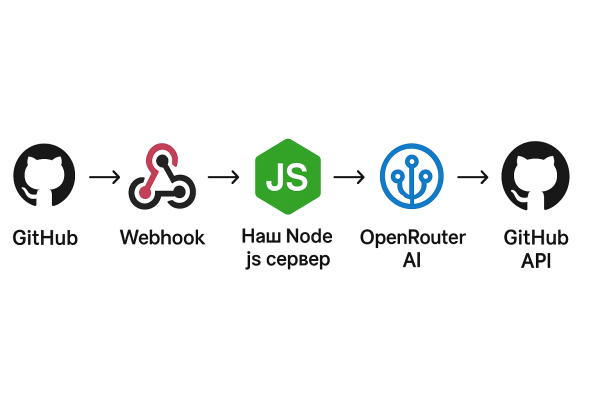
На высоком уровне наша система будет работать по следующей схеме:
 → Webhook → Наш Node.js сервер → OpenRouter AI (анализ кода) → GitHub API (публикация комментария)")
Давайте кратко обоснуем выбор технологий:
Node.js: Мы не будем усложнять проект фреймворками вроде Express или NestJS. Для нашей задачи — принять один тип POST-запроса и обработать его — достаточно встроенного в Node.js модуля http. Это делает наш сервер легковесным и избавляет от лишних зависимостей. Асинхронная природа Node.js идеально подходит для работы с внешними API, где большую часть времени мы будем просто ждать ответа.
OpenRouter: Вместо того чтобы привязываться к API одного конкретного провайдера, мы будем использовать OpenRouter. Это агрегатор, который предоставляет единый API, совместимый с API OpenAI, для доступа к десяткам моделей от разных разработчиков (Google, Anthropic, Mistral и др.). Главные плюсы это — возможность легко менять модели «на лету» и доступ к очень мощным бесплатным моделям, которые идеально подходят для нашего MVP.
Шаг 2: Создание базового Node.js сервера
Начнём с самого простого. Создадим в директории проекта файл index.js и напишем код веб-сервера, который будет слушать входящие запросы.
import http from ‘http’; const server = http.createServer((req, res) => { // Пока просто отвечаем на любой запрос res.writeHead(200, { ‘Content-Type’: ‘text/plain’ }); res.end(‘Server is alive!’); }); const port = 3000; server.listen(port, () => { console.log(`Server is listening on http://localhost:${port}`); });
Этот код использует встроенный модуль http для создания сервера. Он принимает любой запрос (req), отправляет в ответ статус 200 OK и простое текстовое сообщение.
Запустим его в терминале:
node index.js
Вы должны увидеть сообщение: Server is listening on http://localhost:3000. Наш фундамент готов.
Шаг 3: Первое обращение к AI
Теперь научим наш проект общаться с «мозгом». Для взаимодействия с API OpenRouter мы будем использовать официальную библиотеку от OpenAI, так как их API полностью совместимы.
Сначала установим её:
npm install openai
Для безопасного хранения нашего API-ключа мы будем использовать переменные окружения. Создайте в корне проекта файл .env и добавьте в него ваш ключ от OpenRouter. (сгенерировать апи ключ можно по адресу https://openrouter.ai/settings/keys)
OPENROUTER_API_KEY=»…»
Чтобы Node.js «увидел» этот файл, установим пакет dotenv:
npm install dotenv
Теперь обновим наш index.js, добавив логику для вызова AI.
import http from ‘http’; import OpenAI from ‘openai’; import ‘dotenv/config’; // Загружаем переменные из .env // НАСТРОЙКА КЛИЕНТА ДЛЯ OPENROUTER const openai = new OpenAI({ baseURL: «https://openrouter.ai/api/v1», apiKey: process.env.OPENROUTER_API_KEY, }); // АСИНХРОННАЯ ФУНКЦИЯ ДЛЯ ТЕСТА AI async function testAI() { console.log(«Отправляем тестовый запрос ИИ…»); try { const completion = await openai.chat.completions.create({ model: «qwen/qwen-2.5-72b-instruct:free», messages: [ { role: «user», content: «Ответь на главный вопрос жизни, вселенной и вообще. (The Hitchhiker’s Guide to the Galaxy)» } ], }); console.log(«Ответ ИИ:», completion.choices[0].message.content); } catch (error) { console.error(«Ощибка вызова AI:», error); } } // СЕРВЕР (остается без изменений) const server = http.createServer((req, res) => { res.writeHead(200, { ‘Content-Type’: ‘text/plain’ }); res.end(‘Server is alive!’); }); const port = 3000; server.listen(port, () => { console.log(`Server is listening on http://localhost:${port}`); // Вызываем тестовую функцию при старте сервера testAI(); });
Что мы сделали:
Импортировали dotenv/config, чтобы загрузить переменные из .env в process.env.
Инициализировали клиент openai, указав baseURL от OpenRouter и наш API-ключ.
Создали асинхронную функцию testAI, которая отправляет простой текстовый запрос модели и выводит её ответ в консоль.
Вызвали эту функцию один раз при старте сервера для проверки.
Теперь, если вы запустите node index.js, вы увидите не только сообщение о старте сервера, но и ответ от языковой модели.
Итак, наш фундамент готов: у нас есть сервер, способный принимать запросы, и «мозг», способный генерировать осмысленные ответы.
Часть 2: Подключаемся к реальному миру — Вебхуки GitHub
Наш сервер работает, AI готов к труду и обороне. Но пока они существуют в вакууме на localhost. Чтобы наш ассистент мог реагировать на события в репозитории, нам нужно научить GitHub отправлять ему уведомления. Эти уведомления называются вебхуками.
Шаг 4: Проблема локальной разработки
Здесь мы сталкиваемся с первой фундаментальной проблемой. Наш сервер работает по адресу http://localhost:3000 — этот адрес доступен только на нашем компьютере. GitHub, находясь в глобальной сети, понятия не имеет, как отправить запрос на ваш localhost. Ему нужен публично доступный URL.
Классическое решение этой задачи — ngrok. Это утилита, которая создает безопасный туннель от публичного URL к вашему локальному порту. Это отличный инструмент, но для работы с GitHub есть решение элегантнее и удобнее, интегрированное в экосистему самого GitHub.
Шаг 5: Правильный инструмент — GitHub CLI
Вместо сторонних утилит мы воспользуемся официальным инструментом — GitHub CLI (gh). Это консольная утилита, которая позволяет делать с GitHub практически всё, не выходя из терминала. Одна из её самых полезных функций для нас — перенаправление вебхуков.
Сначала установим gh. Инструкции для всех ОС есть на официальной странице. После установки нужно будет авторизоваться, выполнив gh auth login.
Далее, установим специальное расширение для работы с вебхуками:
gh extension install cli/gh-webhook
Теперь у нас есть всё необходимое. Одной командой мы можем «сказать» GitHub: «Все вебхуки, связанные с Pull Request в этом репозитории, пожалуйста, пересылай на мой локальный сервер».
Убедитесь, что ваш Node.js сервер запущен, и в новом окне терминала выполните команду:
gh webhook forward —repo=<OWNER>/<REPO> —events=pull_request —url=»http://localhost:3000/webhook»
Давайте разберём её:
—repo=<OWNER>/<REPO>: Укажите владельца и имя вашего репозитория (например, AlekseyVY/leetcode).
—events=pull_request: Мы подписываемся только на события, связанные с Pull Request.
—url=»http://localhost:3000/webhook»: Тот самый адрес, куда gh будет пересылать полученные события. Мы будем обрабатывать их по пути /webhook.
После выполнения вы должны увидеть сообщение Forwarding Webhook events from GitHub…. Поздравляю, мост между GitHub и вашим локальным сервером построен!
Шаг 6: Первая линия обороны — верификация подписи
Теперь наш сервер доступен извне. Но как нам убедиться, что запрос, пришедший на /webhook, был отправлен именно GitHub, а не каким-то злоумышленником? Для этого GitHub подписывает каждый вебхук. Он создает HMAC-хеш от тела запроса (payload), используя секретный ключ, который знаете только вы и он. Этот хеш отправляется в заголовке X-Hub-Signature-256. Наша задача — выполнить ту же операцию у себя на сервере и сравнить результаты. Если хеши совпадают — запрос подлинный. Для начала, обновим наш сервер, чтобы он обрабатывал путь /webhook и читал тело запроса. Нам понадобится пакет raw-body для корректного чтения потока.
npm install raw-body
затем создадим Секретный ключ, который мы будем использовать GITHUB_WEBHOOK_SECRET = ‘my-super-secret-123’в нашем .env. ВАЖНО: Он должен быть таким же, как и тот, что мы укажем для gh.
Теперь напишем саму функцию верификации и интегрируем её в сервер.
// index.js (добавляем новые импорты и логику) import http from ‘http’; import crypto from ‘crypto’; import getRawBody from ‘raw-body’; // … остальной код инициализации … const server = http.createServer(async (req, res) => { if (req.method === ‘POST’ && req.url === ‘/webhook’) { // Верифицируем подпись const signature = req.headers[‘x-hub-signature-256’]; const rawBody = await getRawBody(req); if (!verifySignature(signature, rawBody)) { console.error(‘Невалидная сигнатура, запрос проигнорирован.’); res.writeHead(401, { ‘Content-Type’: ‘text/plain’ }); res.end(‘Unauthorized’); return; } // Если подпись верна, пока просто логируем событие const event = req.headers[‘x-github-event’]; console.log(`Получено валидное событие вебхука: ${event}`); res.writeHead(200, { ‘Content-Type’: ‘text/plain’ }); res.end(‘Webhook received!’); return; } // Для всех остальных запросов res.writeHead(404); res.end(); }); function verifySignature(signature, payloadBody) { if (!signature) { return false; } const hmac = crypto.createHmac(‘sha256’, process.env.GITHUB_WEBHOOK_SECRET); const digest = ‘sha256=’ + hmac.update(payloadBody).digest(‘hex’); // Используем crypto.timingSafeEqual для защиты от атак по времени return crypto.timingSafeEqual(Buffer.from(signature), Buffer.from(digest)); } // … код запуска сервера …
«Ага!» момент: ловушка с «Невалидная сигнатура»
Теперь, если вы запустите сервер и создадите Pull Request, вы, скорее всего, столкнётесь с ошибкой в консоли: Невалидная сигнатура, запрос проигнорирован.. Почему? Ведь код верификации правильный.
Дело в том, что по умолчанию gh webhook forward сам генерирует случайный секрет для создаваемого на лету вебхука. А наш сервер ожидает my-super-secret-123. Секреты не совпадают. Решение простое — нужно явно указать gh, какой секрет использовать, с помощью флага —secret. Остановите предыдущую команду gh и запустите новую, правильную:
gh webhook forward —repo=<OWNER>/<REPO> —events=pull_request —url=»http://localhost:3000/webhook» —secret «my-super-secret-123»
Теперь, когда вы создадите Pull Request, ваш сервер должен будет ответить в консоли Получено валидное событие вебхука: pull_request. Мы успешно и безопасно соединили наш сервер с GitHub. Он готов принимать события и проверять их подлинность.
Часть 3: MVP 1.0 — Общий комментарий к Pull Request
На этом этапе мы создадим первую рабочую версию нашего ассистента (Minimum Viable Product). Он будет выполнять три ключевые действия:
Получать изменения кода (diff) из Pull Request.
Отправлять их на анализ AI.
Публиковать ответ модели в виде общего комментария к Pull Request.
Шаг 7: Получаем изменения кода (diff)
Вся информация о событии, включая Pull Request, приходит к нам в теле вебхука в формате JSON. Среди множества полей там есть одно, которое нам особенно интересно — pull_request.diff_url. Это прямая ссылка на .diff файл, содержащий все изменения кода в данном PR.
Чтобы получить доступ к этому файлу, нам нужно будет сделать аутентифицированный запрос к API GitHub. Для этого понадобится Personal Access Token (PAT).
Создать его можно в настройках вашего профиля GitHub:
Перейдите в Settings → Developer settings → Personal access tokens → Tokens (classic).
Нажмите Generate new token (classic).
Дайте токену имя (например, code-review-bot) и установите срок действия.
Самое важное — выберите права (scopes). Для наших задач достаточно одного: repo. Он даёт полный контроль над вашими репозиториями, включая чтение PR и написание комментариев.
Сгенерируйте токен и немедленно скопируйте его. Вы больше никогда не сможете его увидеть.
Добавим этот токен в наш .env файл:
# .env OPENROUTER_API_KEY=»…» GITHUB_WEBHOOK_SECRET=»…» GITHUB_TOKEN=»…»
Теперь напишем асинхронную функцию, которая будет скачивать diff.
// index.js (добавляем эту функцию в файл) async function getPullRequestDiff(diffUrl) { console.log(«Фетчим дифф:», diffUrl); const response = await fetch(diffUrl, { headers: { ‘Authorization’: `token ${process.env.GITHUB_TOKEN}`, ‘Accept’: ‘application/vnd.github.v3.diff’ // Важный заголовок, указывающий нужный формат } }); if (!response.ok) { throw new Error(`Ошибка получения дифф: ${response.statusText}`); } return response.text(); }
Эта функция использует встроенный в Node.js fetch для выполнения запроса, добавляя в заголовки наш PAT для аутентификации.
Шаг 8: Первый промпт для код-ревью
Теперь нам нужен промпт — инструкция, которую мы дадим языковой модели. Начнём с простого. Наша цель — получить общую оценку кода.
// index.js (обновим нашу функцию для общения с AI) async function getCodeReviewFromLLM(diff) { console.log(«Sending diff to LLM for review…»); const prompt = ` Ты — экспертный AI-код-ревьюер. Твоя задача — провести обзор следующего pull request. Пользователь предоставил файл с диффом. Пожалуйста, проанализируй его и предоставь конструктивный отзыв. Сфокусируйся на возможных ошибках, несоответствиях стилю или предложениях по улучшению. Предоставь отзыв в понятной и дружелюбной форме, используя форматирование Markdown. Вот дифф: «`diff ${diff} «` `; try { const completion = await openai.chat.completions.create({ model: «qwen/qwen-2.5-72b-instruct:free», messages: [{ role: «user», content: prompt }], }); return completion.choices[0].message.content; } catch (error) { console.error(«Ошибка вызова LLM API:», error); return «Извините, я не смог провести код-ревью на данный момент.»; } }
Шаг 9: Публикуем ответ
Получив ревью от модели, нам нужно опубликовать его в GitHub. Для этого мы будем использовать pull_request.comments_url из полезной нагрузки вебхука. Это эндпоинт для создания общих комментариев к PR.
// index.js (добавляем ещё одну функцию-хелпер) async function postReviewComment(commentsUrl, reviewText) { console.log(«Публикация комментария к review. :», commentsUrl); await fetch(commentsUrl, { method: ‘POST’, headers: { ‘Authorization’: `token ${process.env.GITHUB_TOKEN}`, ‘Accept’: ‘application/vnd.github.v3+json’, ‘Content-Type’: ‘application/json’ }, body: JSON.stringify({ body: reviewText }) }); }
Теперь соберём всё вместе в главной логике нашего сервера.
// index.js (обновляем обработчик вебхука) const server = http.createServer(async (req, res) => { if (req.method === ‘POST’ && req.url === ‘/webhook’) { // … код верификации подписи … // Парсим payload const payload = JSON.parse(rawBody.toString()); const event = req.headers[‘x-github-event’]; if (event === ‘pull_request’) { if (payload.action === ‘opened’) { const pr = payload.pull_request; console.log(`Обрабатываю PR: ${pr.title}`); // Запускаем процесс ревью const diff = await getPullRequestDiff(pr.diff_url); const review = await getCodeReviewFromLLM(diff); await postReviewComment(pr.comments_url, review); } } res.writeHead(200, { ‘Content-Type’: ‘text/plain’ }); res.end(‘Webhook processed!’); return; } // … });
Наш MVP 1.0 готов! Если сейчас создать PR, наш ассистент скачает diff, отправит его на анализ и опубликует результат в виде комментария. Но… скорее всего, вы столкнётесь с парой неприятных сюрпризов.
Шаг 10: Первые грабли и гонка состояний
Реальный мир сложнее, чем кажется, и при работе с асинхронными системами, такими как вебхуки, это проявляется особенно ярко.
Проблема «пустых» или двойных комментариев:
Симптом: Вы создаете PR и видите, что бот оставляет несколько комментариев, один из которых может быть пустым.
Причина: Событие pull_request в GitHub срабатывает не только при открытии (opened), но и при других действиях: добавлении коммитов (synchronize), переводе из черновика в готовые (ready_for_review) и т.д. Наш код реагирует на все, что приводит к хаосу.
Решение: Сделать обработку событий более строгой. Мы должны реагировать только на те действия, которые нас интересуют. Идеально для этого подходит конструкция switch.
Проблема пустого diff-файла:
Симптом: Бот оставляет комментарий, в котором жалуется на пустой diff, хотя в PR очевидно есть изменения.
Причина: API GitHub работает по принципу «согласованности в конечном счёте» (eventual consistency). Когда GitHub отправляет вебхук opened, это не гарантирует, что diff_url уже на 100% доступен и содержит данные. Наш сервер слишком быстр — он запрашивает diff раньше, чем тот успевает сгенерироваться.
Решение: Добавить небольшую искусственную задержку перед запросом diff-файла. 3-5 секунд обычно достаточно, чтобы дать API GitHub время «прийти в себя».
Вот как будет выглядеть наш улучшенный, более надёжный обработчик:
// index.js (финальная версия обработчика для MVP 1.0) // … if (event === ‘pull_request’) { const action = payload.action; console.log(`Получил событие pull_request с действием: ${action}`); switch (action) { case ‘opened’: case ‘reopened’: res.writeHead(200, { ‘Content-Type’: ‘text/plain’ }); res.end(‘Webhook accepted. Processing review in the background.’); // Запускаем «медленный» процесс в фоне handlePullRequest(payload); break; default: console.log(`Игнорирую действие «${action}».`); res.writeHead(200, { ‘Content-Type’: ‘text/plain’ }); res.end(`Action «${action}» ignored.`); break; } } // … async function handlePullRequest(payload) { try { const pr = payload.pull_request; console.log(`Обрабатываю PR: «${pr.title}»`); // РЕШЕНИЕ 2: Добавляем задержку await new Promise(resolve => setTimeout(resolve, 5000)); const diff = await getPullRequestDiff(pr.diff_url); if (diff && diff.trim()) { const review = await getCodeReviewFromLLM(diff); await postReviewComment(pr.comments_url, review); console.log(`Ревью орубликованно для PR: «${pr.title}»`); } else { console.log(«Дифф пустой. Пропускаю ревью.»); } } catch (error) { console.error(«Ошибка обработки PR:», error); } }
Обратите внимание на ещё одно улучшение: мы сначала отправляем GitHub ответ 200 OK, а уже потом запускаем handlePullRequest. Это лучшая практика для долгих задач. GitHub не любит, когда вебхуки «висят» без ответа больше нескольких секунд.
Теперь наш MVP не только работает, но и устойчив к основным проблемам реального мира. Однако общий комментарий — это хорошо, но настоящий ревьюер комментирует конкретные строки.
Часть 4: Level Up — От общих фраз к построчным комментариям
Общий комментарий — это уже неплохо, но ценность код-ревью в контексте. Замечания должны быть привязаны к конкретным строкам кода, чтобы разработчик мог сразу понять, о чём идёт речь, и начать обсуждение. Чтобы этого добиться, нам нужно научить модель возвращать структурированные данные и использовать другой, более мощный эндпоинт GitHub API.
Шаг 11: Промпт-инжиниринг для JSON
Просить модель вернуть обычный текст больше не годится. Нам нужно, чтобы на выходе мы получали данные в формате, который легко сможет «прочитать» наша программа. Идеальный кандидат — JSON.
Мы должны кардинально изменить наш промпт. Теперь его главная задача — не просто попросить сделать ревью, а строго указать, в каком формате вернуть результат.
Формат: Мы будем ожидать JSON-массив.
Элемент массива: Каждый элемент будет представлять собой один комментарий и должен быть объектом с тремя ключами:
path: путь к файлу, к которому относится комментарий.
line: номер строки в diff-файле.
body: текст самого комментария.
Вот как выглядит новый промпт:
// index.js (внутри функции getCodeReviewFromLLM) const prompt = ` Ты — высококвалифицированный AI-ревьюер кода. Твоя задача — провести ревью pull request на основе предоставленного diff-файла и вернуть свои замечания в формате JSON. Проанализируй следующие изменения. Для КАЖДОГО замечания, которое ты найдешь, укажи путь к файлу и номер строки в diff-файле, к которой относится замечание. Твой ответ ДОЛЖЕН быть валидным JSON-массивом объектов. Каждый объект должен иметь следующие ключи: — «path»: (string) Полный путь к файлу. — «line»: (number) Номер строки в diff-файле, к которой относится комментарий. — «body»: (string) Текст твоего комментария. Пример желаемого формата ответа: [ { «path»: «src/user-service.ts», «line»: 15, «body»: «Здесь лучше использовать ‘const’ вместо ‘let’, так как переменная не переназначается.» } ] Если в коде нет проблем, верни пустой массив []. Вот diff для анализа: «`diff ${diff} «` `;
Чтобы помочь модели придерживаться формата, мы также можем использовать специальный параметр в запросе к API, который явно указывает, что мы ожидаем JSON.
// index.js (обновляем вызов openai.chat.completions.create) const completion = await openai.chat.completions.create({ model: «qwen/qwen-2.5-72b-instruct:free», messages: [{ «role»: «user», «content»: prompt }], // Говорим модели, что ответ должен быть в формате JSON response_format: { type: «json_object» }, }); const responseText = completion.choices[0].message.content; // Модель может вернуть JSON внутри markdown блока, очистим это. const cleanedJson = JSON.parse(responseText.replace(/«`json/g, »).replace(/«`/g, »).trim()); // или обьект с полем comments if(‘comments’ in cleanedJson) { return cleanedJson.comments; } return JSON.parse(cleanedJson);
Теперь наша функция getCodeReviewFromLLM возвращает не просто строку, а готовый JavaScript-массив с объектами комментариев.
Шаг 12: Новый API GitHub — Pull Request Reviews
Просто отправлять комментарии больше не получится. Чтобы привязать их к строкам, нам нужно использовать более сложный механизм — Pull Request Reviews.
Ревью в GitHub — это сущность, которая может объединять:
Один общий комментарий к Pull Request.
Несколько построчных комментариев.
Статус (Approve, Request Changes или просто Comment).
Для создания ревью используется новый эндпоинт: POST /repos/{owner}/{repo}/pulls/{pull_number}/reviews.
Давайте напишем новую функцию для отправки такого ревью. Старая postReviewComment нам больше не понадобится.
// index.js (новая функция вместо postReviewComment) async function postLineByLineReview(owner, repo, pull_number, comments) { const endpoint = `https://api.github.com/repos/${owner}/${repo}/pulls/${pull_number}/reviews`; console.log(«Публикую комментарии:», endpoint); const reviewBody = { body: «AI-ассистент провел ревью кода. Пожалуйста, ознакомьтесь с комментариями.», // Общий комментарий event: «COMMENT», // Мы просто комментируем, не апрувим и не запрашиваем изменения comments: comments, // Массив наших построчных комментариев }; const response = await fetch(endpoint, { method: ‘POST’, headers: { ‘Authorization’: `token ${process.env.GITHUB_TOKEN}`, ‘Accept’: ‘application/vnd.github.v3+json’, ‘Content-Type’: ‘application/json’ }, body: JSON.stringify(reviewBody) }); if (!response.ok) { const errorBody = await response.text(); throw new Error(`Ошибка публикации комментариев: ${response.statusText} — ${errorBody}`); } }
Эта функция принимает все необходимые данные (владельца репо, имя репо, номер PR) и массив комментариев, который мы получили от LLM. Она формирует тело запроса и отправляет его в GitHub.
Осталось только обновить handlePullRequest, чтобы он вызывал новую функцию с правильными параметрами.
// index.js (обновляем handlePullRequest) async function handlePullRequest(payload) { try { const pr = payload.pull_request; const repo = payload.repository; // Получаем нужные данные из payload const owner = repo.owner.login; const repoName = repo.name; const prNumber = pr.number; // … (код с задержкой и получением diff) … if (diff && diff.trim()) { const reviewComments = await getCodeReviewFromLLM(diff); if (reviewComments && reviewComments.length > 0) { await postLineByLineReview(owner, repoName, prNumber, reviewComments); console.log(`Ревью успешно проведено для PR: «${pr.title}»`); } else { console.log(«LLM не вернула комментарии.»); } } else { console.log(«Дифф пустой, скипаю ревью.»); } } catch (error) { console.error(«Ошибк обработки PR:», error); } }
Теперь наш ассистент перешёл на новый уровень. Он не просто бросает общие фразы, а участвует в ревью почти как настоящий член команды, оставляя замечания там, где им и место — в коде.
Казалось бы, работа сделана. Но, как вы догадываетесь, именно здесь и начинается самое интересное. Языковая модель — не компилятор. Она креативна, а иногда — слишком креативна.
Часть 5: Закаляем код — Битва с непредсказуемостью LLM
Теория великолепна: мы просим модель вернуть JSON, она его возвращает, мы его парсим и отправляем. Реальность гораздо интереснее. Языковая модель это не детерминированный API, а творческий партнёр. Иногда её «творчество» ломает наш код. В этой главе мы рассмотрим реальные ошибки, с которыми столкнулись, и превратим наш скрипт в по-настоящему отказоустойчивый инструмент.
Шаг 13: Парсинг и очистка данных
Первая же попытка запустить нашего обновлённого бота привела к ошибке 422 Unprocessable Entity от API GitHub. Сообщение гласило: «Pull request review thread path is invalid».
Проблема: Мы попросили модель вернуть path и line из diff-файла. Она справилась идеально. Вот только формат diff устроен так, что пути к файлам указываются с префиксами a/ и b/. Модель вернула нам путь вида b/src/index.js. Но API GitHub ожидает «чистый» путь: src/index.js. Он не смог найти файл b/src/index.js в репозитории и отклонил запрос.
Решение: Добавить простой шаг очистки данных перед отправкой в GitHub.
// index.js (внутри handlePullRequest) // … получили reviewComments от LLM … const cleanedComments = reviewComments.map(comment => ({ …comment, // Если путь начинается с ‘b/’, убираем первые два символа. // Аналогично можно добавить и для ‘a/’, если модель вдруг решит вернуть такой путь. path: comment.path.startsWith(‘b/’) ? comment.path.substring(2) : comment.path })); // Отправляем в GitHub уже очищенные комментарии await postLineByLineReview(owner, repoName, prNumber, cleanedComments);
Просто, но эффективно. Это первый урок: никогда не доверяйте данным от LLM на 100%, всегда валидируйте и очищайте их.
Шаг 14: Делаем код «пуленепробиваемым»
Следующие несколько запусков подарили нам целый каскад ошибок TypeError и SyntaxError. Каждый раз, когда мы думали, что предусмотрели всё, модель находила новый способ нас удивить. Вот наш «хит-парад» проблем и их решений.
Проблема: Модель вернула ОБЪЕКТ {} вместо МАССИВА []
Симптом: Мы нашли одно замечание. Вместо того чтобы обернуть его в массив [{…}], модель вернула просто один объект {…}.
Ошибка: TypeError: reviewComments.map is not a function. Логично, у объектов нет метода .map().
Решение: Сделать наш парсер умнее. Если мы получили объект, нужно проверить, не является ли он сам по себе комментарием.
Проблема: Модель вернула ОБЪЕКТ С ВЛОЖЕННЫМ МАССИВОМ { «comments»: […] }
Симптом: Модель решила быть «полезной» и обернула массив в объект с ключом comments.
Ошибка: Та же самая, reviewComments.map is not a function.
Решение: Если мы получили объект, нужно не только проверить, не является ли он сам комментарием, но и поискать, нет ли внутри него ключа, значение которого — массив.
Проблема: Модель вернула ПУСТУЮ СТРОКУ «»
Симптом: Модель не нашла замечаний и вместо пустого массива [] вернула пустой ответ.
Ошибка: SyntaxError: Unexpected end of JSON input при попытке JSON.parse(«»).
Решение: Добавить проверку на пустую строку перед вызовом JSON.parse.
Проблема: API вернул ОТВЕТ БЕЗ поля choices
Симптом: Редкий случай, когда API OpenRouter вернул 200 OK, но в теле ответа отсутствовал ключ choices. Это может случиться при внутреннем таймауте у провайдера модели.
Ошибка: TypeError: Cannot read properties of undefined (reading ‘0’) при попытке доступа к completion.choices[0].
Решение: Добавить проверку на существование и непустоту completion.choices перед доступом к его элементам.
Чтобы решить все эти проблемы разом, мы написали финальную, надёжную логику парсинга в handlePullRequest и getCodeReviewFromLLM.
Вот обновлённый, закалённый в боях код:
// index.js (финальная, отказоустойчивая версия getCodeReviewFromLLM) async function getCodeReviewFromLLM(diff) { // … (промпт без изменений) … try { const completion = await openai.chat.completions.create({ /* … */ }); // РЕШЕНИЕ 4: Проверяем ‘choices’ if (!completion.choices || completion.choices.length === 0) { console.log(«LLM ответ не содержит поля ‘choices’.»); return null; } const responseText = completion.choices[0].message.content; // РЕШЕНИЕ 3: Проверяем на пустую строку if (!responseText || !responseText.trim()) { console.log(«LLM вернула пустую строку.»); return null; } const cleanedJson = responseText.replace(/«`json/g, »).replace(/«`/g, »).trim(); return JSON.parse(cleanedJson); } catch (error) { console.error(«Ошибка парсинга LLM ответа:», error); return null; // Возвращаем null в случае любой ошибки } } // index.js (финальная, отказоустойчивая версия handlePullRequest) async function handlePullRequest(payload) { // … (получение diff) … const rawResponse = await getCodeReviewFromLLM(diff); console.log(«Чистый AI ответ:», rawResponse); let commentsArray = []; // РЕШЕНИЕ 1 и 2: Гибкий парсинг if (Array.isArray(rawResponse)) { commentsArray = rawResponse; // Идеальный случай } else if (typeof rawResponse === ‘object’ && rawResponse !== null) { // Ищем массив внутри объекта let foundArray = false; for (const key in rawResponse) { if (Array.isArray(rawResponse[key])) { commentsArray = rawResponse[key]; foundArray = true; break; } } // Если массив не найден, проверяем, не является ли сам объект комментарием if (!foundArray && rawResponse.path && rawResponse.line && rawResponse.body) { commentsArray = [rawResponse]; } } if (commentsArray.length === 0) { console.log(«Не найдено валидных комментариев. Пропускаю.»); return; } // … (очистка путей и отправка) … }
Шаг 15: Отладка проблем с API OpenRouter
Иногда проблемы возникают не в нашем коде и не в модели, а в конфигурации. Я столкнулся с двумя такими ошибками от OpenRouter:
404 No endpoints found matching your data policy: Эта ошибка означает, что ваши настройки приватности в OpenRouter запрещают отправлять данные на бесплатные модели, которые могут использовать их для обучения. Решение — изменить политику на более разрешающую.
400 Invalid Model ID: Просто опечатка или использование устаревшего ID модели. Решение — проверить актуальное название на сайте OpenRouter.
Этот опыт учит нас важному правилу: всегда внимательно читать сообщения об ошибках от внешних API.
После всех этих улучшений наш код стал похож на опытного сапёра: он ожидает подвоха на каждом шагу и готов к любым сюрпризам.
Часть 6: Финальные штрихи и взгляд в будущее
Наш AI-ассистент работает, он надёжен и справляется с основной задачей. Но, как и в любом хорошем проекте, здесь всегда есть место для улучшений и новых идей. В этой заключительной части мы добавим несколько полезных штрихов и обсудим, как можно развивать этот инструмент дальше.
Шаг 16: Интернационализация
Что, если ваша команда предпочитает получать фидбэк на другом языке? С языковыми моделями это решается элементарно. Нам не нужно менять логику, добавлять файлы локализации или переписывать код. Всё, что требуется — немного изменить наш промпт.
Откроем функцию getCodeReviewFromLLM и добавим в инструкцию для модели несколько фраз на русском:
// index.js (отрывок из промпта в getCodeReviewFromLLM) const prompt = ` Ты — высококвалифицированный AI-ревьюер кода. Твоя задача — провести ревью pull request… // … (описание формата JSON) … Пожалуйста, предоставь весь твой ответ на русском языке. Если в коде нет проблем, верни пустой массив []. Вот diff для анализа: … `;
Этого достаточно. Модель поймёт контекст и переведёт свои ответы. Это яркий пример того, насколько гибкими становятся системы, построенные на LLM: изменение поведения часто сводится к изменению текста на естественном языке, а не переписыванию сложной логики.
Шаг 17: Куда двигаться дальше?
Наш MVP — это только начало. Вот несколько идей, как можно превратить его в полноценный промышленный инструмент:
Развёртывание в Kubernetes:
Сейчас мы запускаем сервер локально. Для продакшена его следует упаковать в Docker-контейнер и развернуть в Kubernetes-кластере. Это даст нам масштабируемость, отказоустойчивость и позволит легко управлять секретами (API-ключами) через нативные инструменты K8s.Интеграция с GitLab/Bitbucket:
Демонстрация была сделана на GitHub, но архитектура нашего сервиса универсальна. GitLab, Bitbucket и другие системы контроля версий предоставляют очень похожие механизмы вебхуков. Адаптация нашего сервиса для GitLab сведётся к трём вещам:Разобраться со структурой JSON-объекта, который присылает GitLab (она будет отличаться от GitHub).
Изменить эндпоинты для публикации комментариев в соответствии с API GitLab.
Реализовать их механизм верификации подписи (например, через X-Gitlab-Token). Сама логика работы с LLM останется неизменной.
Более сложные промпты:
Можно создать библиотеку промптов для разных типов файлов. Например, для .sql-файлов просить модель обращать внимание на потенциальные SQL-инъекции и производительность запросов, а для .js-файлов — на асинхронные паттерны и обработку ошибок.Анализ изображений и диаграмм:
Современные модели, такие как Google Gemini, мультимодальны — они могут анализировать не только текст, но и изображения. Можно расширить бота, чтобы он «смотрел» на скриншоты в комментариях и описывал, что на них видит, или даже анализировал загруженные в PR диаграммы архитектуры.Сбор статистики и обучение команды:
Каждый комментарий, оставленный ботом — это ценные данные. Можно сохранять их в базу данных и анализировать: какие типы ошибок встречаются в коде чаще всего? Это позволит выявить «слепые зоны» в знаниях команды и организовать целенаправленное обучение.
Заключение
Мы прошли полный путь от простой идеи до работающего и закалённого в боях MVP. Мы создали не просто «ещё одного бота», а по-настоящему полезный инструмент, который берёт на себя рутину и позволяет команде сосредоточиться на самом важном.
Главный вывод, который мы сделали: создание таких AI-инструментов — это не столько про вызов API, сколько про повышение отказоустойчивости и «приручение» мощной, но не всегда предсказуемой технологии. Каждый TypeError, каждая 422 Unprocessable Entity — это не провал, а возможность сделать систему умнее и надёжнее.
P.S. Полный код проекта доступен в этом GitHub-репозитории.
Источник: habr.com

























