
Использование синтетических данных, обеспечивающих конфиденциальность, в федеративном обучении может улучшить как небольшие, так и большие языковые модели, что находит практическое применение в Gboard для улучшения пользовательского опыта набора текста.
Быстрые ссылки
- Основной документ
- Статья о ранних синтетических данных
- Статья об алгоритме DP-FL
- Делиться
Недавний успех моделей машинного обучения основан не только на больших объемах, но и на высоком качестве данных. Для обучения как больших, так и малых языковых моделей (ЯМ) используется парадигма предварительного обучения на массивах данных, собранных в интернете, и последующего обучения на меньших объемах высококачественных данных. Для больших моделей последующее обучение оказалось жизненно важным для адаптации моделей к намерениям пользователя, а последующее обучение малых моделей для адаптации к предметной области пользователя дало значительные результаты, например, улучшение ключевых показателей производительности мобильных приложений для набора текста на 3–13%.
Однако в сложных системах обучения языковых моделей существуют потенциальные риски для конфиденциальности, такие как запоминание конфиденциальных данных инструкций пользователя. Синтетические данные, обеспечивающие конфиденциальность, предоставляют один из способов доступа к данным о взаимодействии пользователя для улучшения моделей, систематически минимизируя при этом риски для конфиденциальности. Благодаря возможностям генерации больших языковых моделей (LLM), можно создавать синтетические данные, имитирующие данные пользователя, без риска их запоминания. Затем эти синтетические данные можно использовать в обучении модели так же, как и общедоступные данные, что упрощает обучение модели с сохранением конфиденциальности.
Gboard использует как небольшие языковые модели (ЛМ), так и большие языковые модели (ЛМ) для улучшения опыта набора текста у миллиардов пользователей. Небольшие ЛМ поддерживают основные функции, такие как ввод текста с помощью свайпа, прогнозирование следующего слова (NWP), интеллектуальное составление текста, интеллектуальное автодополнение и подсказки; ЛМ поддерживают расширенные функции, такие как проверка орфографии. В этом посте мы делимся результатами наших исследований за последние несколько лет по генерации и использованию синтетических данных для улучшения ЛМ для мобильных приложений набора текста. Мы фокусируемся на подходах, соблюдающих принципы конфиденциальности как минимизации данных, так и анонимизации данных, и показываем, как они оказывают реальное влияние на небольшие и большие модели в Gboard. В частности, в нашей недавней статье «Синтез и адаптация данных для коррекции ошибок для мобильных приложений с большими языковыми моделями» обсуждаются достижения в области сохранения конфиденциальности синтетических данных для ЛМ в производственной среде, основанные на наших непрерывных исследованиях, описанных ниже [1, 2, 3, 4, 5].
воспроизведение видео без звука зацикливание пауза видео без звука зацикливание включение звука видео выключение звука
Функции автодополнения, исправления и прогнозирования в Gboard, работающие на основе небольших языковых моделей декодера, а также расширенная функция проверки орфографии для исправления ошибок, работающая на основе языковых моделей LLM.
Обучение на основе общедоступных и частных данных на практике.
В нашем блоге 2024 года обсуждались лучшие практики обучения с сохранением конфиденциальности на пользовательских данных для адаптации небольших языковых моделей к области ввода текста на мобильных устройствах. Применяется федеративное обучение (ФО) с дифференциальной конфиденциальностью (ДП), благодаря чему пользовательские данные, хранящиеся на собственном устройстве, имеют минимальный доступ (т.е., ограниченный контроль доступа) во время обучения и не запоминаются обученными моделями. Предварительное обучение на веб-данных улучшает производительность приватного постобучения, что позволяет внедрять ДП на уровне пользователя в производство. В рамках сегодняшнего блога мы рассматриваем пользовательские данные, генерируемые в приложениях, как приватные данные, а доступные веб-данные и модели, обученные на них, как общедоступную информацию (где мы применяем стратегию многоуровневой защиты конфиденциальности для смягчения опасений по поводу потенциальной утечки информации из общедоступных данных).
Сегодня все языковые модели Gboard, обученные на пользовательских данных, используют федеративное обучение с гарантией дифференциальной конфиденциальности, включая ключевые модели декодеров и модели NWP 2024 года. Этот важный этап достигнут благодаря запуску десятков новых языковых моделей, обученных с использованием федеративного обучения и дифференциальной конфиденциальности (языковые модели DP-FL), и замене всех старых моделей, использующих только федеративное обучение. С 2024 года исследования в этой области продолжаются быстрыми темпами: мы используем новый алгоритм DP, BLT-DP-FTRL, который обеспечивает оптимальный баланс между конфиденциальностью и полезностью, а также простоту развертывания; мы применяем архитектуру модели SI-CIFG для эффективного обучения на устройстве и совместимости с DP; и мы используем синтетические данные из языковых моделей для улучшения предварительного обучения. Приверженность обучению с сохранением конфиденциальности для улучшения небольших языковых моделей не только принесла существенные преимущества пользователям, но и помогла улучшить языковые модели в мобильных приложениях для набора текста, используя синтетические данные.
Использование синтетических данных из общедоступных программ магистратуры для повышения эффективности частного обучения.
В статье «Использование синтетических данных для синтеза данных для частных приложений на устройствах» мы описываем наш подход к использованию синтетических данных для предварительного обучения небольших языковых моделей, которые впоследствии проходят постобучение с помощью динамического программирования и функционального программирования. Мы используем мощные языковые модели, обученные на общедоступных данных, для синтеза высококачественных и предметно-ориентированных данных, которые напоминают данные о вводе текста пользователями, без доступа к каким-либо частным данным пользователей. Этот подход включает в себя тщательно разработанные подсказки, которые инструктируют языковые модели (1) фильтровать большие общедоступные наборы данных для выбора текста, характерного для взаимодействия мобильных пользователей (пример подсказки: «Вероятно ли, что эта тема обсуждается людьми по мобильным телефонам?»); и (2) преобразовывать выбранный текст в разговорный формат (подсказка: «Преобразуйте эту статью в диалог, который вы можете отправить по мобильному телефону»); или (3) напрямую генерировать текст, похожий на диалог, на основе конкретных и искусственных сценариев (подсказка: «Представьте, что вы — пользователь, обменивающийся сообщениями с семьей по мобильному телефону. Сгенерируйте чат»).
Полученные синтетические данные объединяют общедоступные знания, полученные языковыми моделями на основе веб-данных, со знаниями разработчиков, специфичными для мобильных приложений. Синтетические данные не раскрывают пользовательские данные, к которым не обращались во время создания, и их можно проверить перед использованием в обучении. Как показала оценка в Gboard, предварительное обучение на этих синтетических данных обеспечивает относительное улучшение точности прогнозирования погоды на 22,8% по сравнению с предварительным обучением на базовых данных, полученных путем веб-сканирования, и стабильно обеспечивает более быструю сходимость и немного более высокую точность прогнозирования погоды при последующем обучении. Неудивительно, что последующее обучение с сохранением конфиденциальности с использованием DP-FL на пользовательских данных значительно улучшает модель и по-прежнему имеет решающее значение при запуске этих небольших языковых моделей для улучшения пользовательского опыта ввода текста.

Обучение небольших моделей на пользовательских данных в системе, в настоящее время поддерживающей кросс-устройственное федеративное обучение и централизованную дифференциальную конфиденциальность с использованием доверенного сервера. Обученные модели развертываются на мобильных устройствах. Использование синтетических данных для публичного предварительного обучения улучшает как компромисс между конфиденциальностью и полезностью, так и вычислительную эффективность.
Адаптивные к предметной области синтетические данные из LLM и для LLM
Синтетические данные, адаптированные к области мобильных приложений, легко использовать в любом конвейере обучения. Помимо обучения небольших языковых моделей в частном порядке, они также полезны для улучшения и развертывания больших языковых моделей в этой области. В статье «Синтез и адаптация данных для коррекции ошибок в мобильных приложениях с большими языковыми моделями» мы расширяем наши синтетические данные для ввода текста, чтобы улучшить коррекцию ошибок в больших языковых моделях для мобильных приложений. Не имея доступа к пользовательским данным, мы используем Gemini для включения знаний о распространенных грамматических и орфографических ошибках с помощью подсказок, таких как «Вот некоторые распространенные грамматические ошибки: …Теперь примените эти грамматические ошибки к исходным предложениям и сгенерируйте неграмматические предложения». Подсказка Gemini берет наши синтетические данные, имитирующие ввод текста пользователем на мобильных устройствах, для внесения ошибок и создания набора данных пар «ошибка — ошибка». Мы также предлагаем Gemini дополнительно проверить корректность очищенного текста (подсказка: «Наконец, исправьте грамматические ошибки в сгенерированных неграмматичных предложениях. Не изменяйте предложения, кроме исправления грамматических ошибок»), что особенно эффективно при обобщении подхода на языки, отличные от английского. Синтетические наборы данных используются для переноса знаний об исправлении ошибок LLM на более мелкие, эффективные и целенаправленные модели для мобильных приложений. Эти методы способствуют проверке орфографии в новом API GenAI ML Kit.
Модуль защиты конфиденциальности для улучшения качества синтетических данных
Хотя использование общедоступных языковых моделей (ЛМ) является мощным инструментом, область данных мобильных пользователей имеет уникальные характеристики, которые сложно охватить, используя только общедоступные данные и знания разработчиков, как показали исследования как небольших, так и больших предварительно обученных языковых моделей в Gboard. Обучение моделей на основе данных пользователей является многообещающим подходом для дальнейшей адаптации модели-генератора к частной области. Однако обучение ЛМ на мобильных устройствах создает нагрузку на существующие системы федеративного обучения, которые могут иметь ограниченные вычислительные и коммуникационные ресурсы.
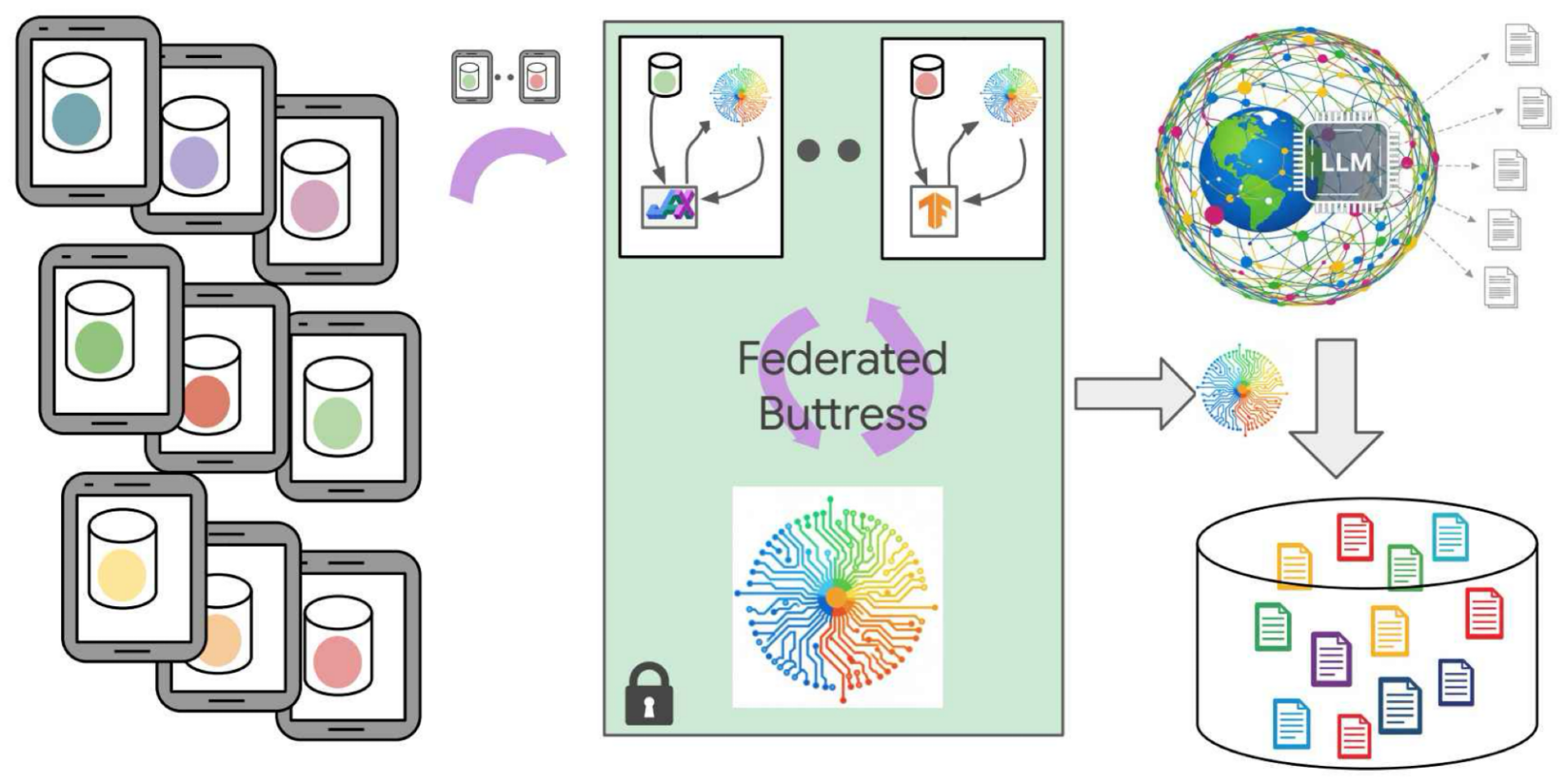
Для обеспечения строгой минимизации данных и анонимизации мы собираем сигналы, обеспечивающие конфиденциальность пользовательских данных, с помощью DP-FL, чтобы направлять генерацию синтетических данных. В наших ранних исследованиях мы использовали небольшие языковые модели (ЛМ) в Gboard для сбора информации о предметной области. Мы называем эти небольшие ЛМ «тонко настроенными с помощью модулей поддержки DP-FL», чтобы отразить их роль в поддержке ЛМ в генерации репрезентативных синтетических данных для различных задач. Более конкретно, мы разработали модель перевзвешивания на основе начальных оценок небольших ЛМ, которая учится прогнозировать производительность ЛМ в мобильных приложениях на основе офлайн-оценки. Затем мы адаптируем синтетические данные, используя модель перевзвешивания: образцы, которые модель перевзвешивания определяет как более репрезентативные для частной предметной области, получают более высокие веса. Перевзвешенный набор синтетических данных помогает лучше настроить проверенную ЛМ Gboard.

Достижения в области частного обучения используются для обучения небольшого опорного модуля вместо непосредственного улучшения моделей, специфичных для конкретной задачи (небольших моделей). Опорный модуль комбинируется с общедоступными LLM для генерации синтетических данных, обеспечивающих конфиденциальность. Синтетические данные представляют собой компонуемый ресурс, который связывает общедоступные знания и конфиденциальную информацию и может использоваться в стандартном конвейере обучения для улучшения как небольших, так и больших моделей.
Обсуждение и дальнейшие шаги
Применение синтетических данных как для небольших, так и для крупных моделей оказывается эффективным для мобильных приложений. Помимо эффективного использования общедоступных знаний в генераторах LLM, синтетические данные потенциально упрощают всю техническую инфраструктуру, поскольку сгенерированные синтетические данные могут использоваться для обучения различных моделей, включая LLM. Синтетические данные могут быть проверены для отладки при разработке приложений и подвергнуты аудиту на предмет защиты конфиденциальности. На протяжении всего производственного процесса мы также применяем многоуровневую стратегию защиты и используем методы обнаружения персональных данных на уровне отрасли и меры защиты на уровне моделей на нескольких этапах.
Более того, использование сигналов пользователей, обеспечивающих конфиденциальность, с помощью облегченных опорных модулей является перспективным направлением для дальнейшего улучшения возможностей LLM в специализированных областях. Исследования в области синтетических данных, обеспечивающих конфиденциальность, быстро развиваются. Благодаря разработке новых систем FL с доверенными средами выполнения для повышения производительности и новых алгоритмов, сочетающих облегченные модули DP с генераторами, точно настроенными на DP [1, 2], качество синтетических данных, обеспечивающих конфиденциальность, из децентрализованных данных может быть значительно улучшено для обслуживания различных приложений на мобильных устройствах.
Благодарности
Авторы выражают особую благодарность Шаньшань У за её технический вклад в создание синтетических данных для приложений Gboard. Мы благодарим Брендана Макмахана и Дэниела Рамаджа за отзывы о самой статье в блоге и поддержку руководства; Юаньбо Чжана и Дэниела Рамаджа за вдохновение и сотрудничество в исследовании; Закари Гарретта, Хайчэна Суня и Шумина Чжая за дополнительные обсуждения и поддержку. Мы благодарим Шаофэна Ли за помощь в создании анимированных фигур, а также команды Google, которые помогли с разработкой алгоритмов, внедрением инфраструктуры и поддержкой в производственной среде.
Источник: research.google