
воспроизведение видео без звука зацикливание пауза видео без звука зацикливание включение звука видео выключение звука
Мы представляем SensorLM, новое семейство базовых моделей взаимодействия сенсоров и языка, обученных на 60 миллионах часов данных, которое связывает многомодальные сигналы носимых датчиков с естественным языком для более глубокого понимания нашего здоровья и активности.
Быстрые ссылки
- Бумага
- Делиться
Носимые устройства, от умных часов до фитнес-трекеров, стали повсеместными, непрерывно собирая огромный поток данных о нашей жизни. Они записывают частоту сердечных сокращений, считают шаги, отслеживают физическую активность и сон, и многое другое. Этот поток информации таит в себе огромный потенциал для персонализированного здоровья и благополучия. Однако, хотя мы легко можем увидеть, что происходит с нашим телом (например, частота сердечных сокращений 150 ударов в минуту), часто отсутствует важнейший контекст, объясняющий причины (например, «быстрый бег в гору» против «стрессового публичного выступления»). Этот разрыв между необработанными данными датчиков и их реальным значением является серьезным препятствием для раскрытия полного потенциала этих устройств.
Основная проблема заключается в дефиците крупномасштабных наборов данных, которые бы сопоставляли записи с датчиков с подробным описательным текстом. Ручная аннотация миллионов часов данных является непомерно дорогостоящей и трудоемкой задачей. Для решения этой проблемы и для того, чтобы данные с носимых устройств действительно «говорили сами за себя», нам нужны модели, способные изучать сложные взаимосвязи между сигналами датчиков и человеческим языком непосредственно на основе этих данных.
В статье «SensorLM: Изучение языка носимых датчиков» мы представляем SensorLM — семейство базовых моделей языка датчиков, которое заполняет этот пробел. Предварительно обученная на беспрецедентных 59,7 миллионах часов мультимодальных данных с датчиков от более чем 103 000 человек, модель SensorLM учится интерпретировать и генерировать детализированные, удобочитаемые описания на основе многомерных данных с носимых устройств, устанавливая новый уровень в понимании данных с датчиков.
воспроизведение видео без звука зацикливание пауза видео без звука зацикливание включение звука видео выключение звука
SensorLM преобразует сложные многомодальные данные с носимых датчиков в осмысленные описания на естественном языке, охватывающие статистические, структурные и семантические аспекты.
Обучение моделей SensorLM
Для создания набора данных с датчиков, необходимого для SensorLM, мы отобрали почти 2,5 миллиона человеко-дней обезличенных данных от 103 643 человек из 127 стран. Эти данные были собраны в период с 1 марта по 1 мая 2024 года с устройств Fitbit или Pixel Watch, при этом участники дали согласие на использование своих обезличенных данных для исследований, направленных на расширение общих знаний в области здравоохранения и науки.
Для преодоления проблемы с аннотированием мы разработали новый иерархический конвейер, который автоматически генерирует описательные текстовые подписи путем вычисления статистических данных, выявления тенденций и описания событий на основе самих данных с датчиков. Этот процесс позволил нам создать самый большой из известных на сегодняшний день набор данных о языке, передаваемом с датчиков, на порядки превосходящий по объему наборы данных, использованные в предыдущих исследованиях.

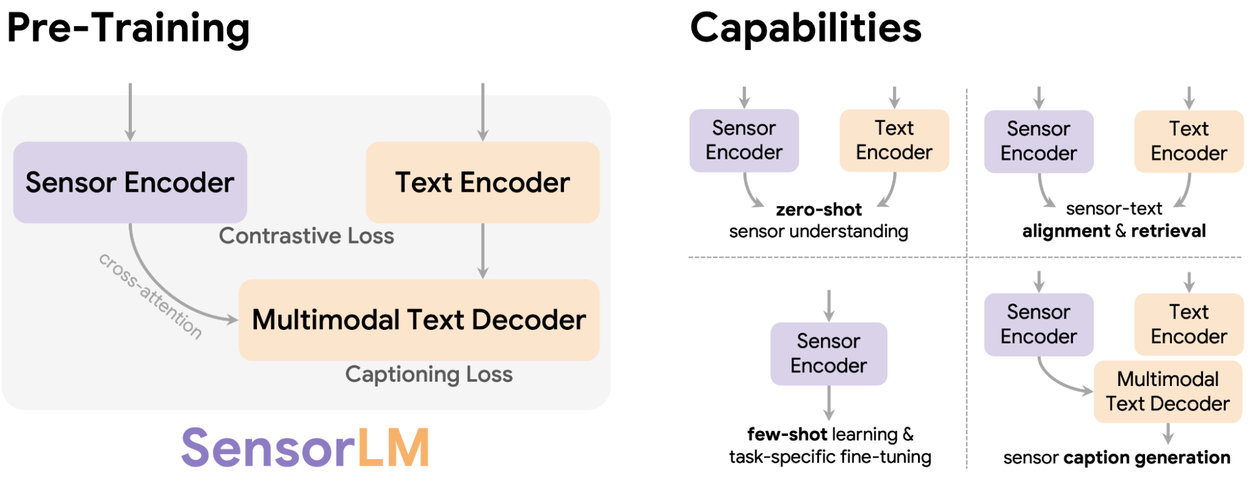
Предварительное обучение SensorLM открывает новые возможности для персонализированного анализа, такие как понимание данных с датчиков без предварительного обучения, выравнивание и поиск текста на основе данных с датчиков, обучение с использованием небольшого количества примеров и генерация подписей к изображениям с датчиков.
Архитектура SensorLM основана на известных стратегиях многомодального предварительного обучения и объединяет их, например, с помощью контрастивного обучения и генеративного предварительного обучения.
- Контрастное обучение : модель учится сопоставлять сегмент данных датчика с соответствующим текстовым описанием из набора вариантов. Это позволяет ей различать различные виды деятельности и состояния (например, отличать «легкое плавание» от «силовой тренировки»).
- Генеративное предварительное обучение : модель учится генерировать текстовые подписи непосредственно из данных датчика. Это позволяет ей создавать подробные, контекстно-зависимые описания, понимая многомерные сигналы датчика.
Интегрируя эти подходы в единую, целостную структуру, SensorLM развивает глубокое, мультимодальное понимание взаимосвязи между сигналами датчиков и языком.
Ключевые возможности и модели масштабирования
Мы оценили SensorLM на широком спектре реальных задач в области распознавания человеческой активности и здравоохранения. Результаты демонстрируют значительный прогресс по сравнению с предыдущими передовыми моделями.
Распознавание и поиск активности
SensorLM демонстрирует превосходные результаты в задачах с ограниченным объемом размеченных данных. Он обеспечивает замечательную классификацию активности без предварительного обучения, точно классифицируя данные по 20 видам активности без какой-либо тонкой настройки, и отлично справляется с обучением в условиях ограниченного количества примеров, быстро обучаясь всего на нескольких примерах. Это делает модель легко адаптируемой к новым задачам и пользователям с минимальным объемом данных. Кроме того, SensorLM обеспечивает мощный кросс-модальный поиск, позволяя осуществлять кросс-модальное понимание между данными датчиков и языковыми описаниями. Это позволяет запрашивать описания, используя входные данные датчиков, или находить конкретные шаблоны датчиков с помощью естественного языка, что облегчает анализ, проводимый экспертами (более подробные результаты можно найти в статье).

В задачах распознавания активности человека без предварительного обучения SensorLM демонстрирует высокие показатели распознавания без предварительного обучения в различных режимах (измеренные по AUROC ), в то время как базовые модели LLM показывают результаты, близкие к случайным.
Генеративные возможности
Помимо своих возможностей классификации, SensorLM демонстрирует впечатляющие возможности генерации подписей. Используя только многомерные сигналы датчиков с носимого устройства, SensorLM может создавать иерархические и контекстно релевантные подписи. Экспериментальные результаты показывают, что сгенерированные подписи были более связными и фактически корректными, чем те, которые были созданы мощными неспециализированными LLM.

Эффективность захвата текста с помощью SensorLM и базовых моделей, измеренная с помощью BERTScore (точность, полнота, F1).

Слева: Входные данные с носимого датчика. Справа: Истинное описание и описания, сгенерированные различными моделями. SensorLM генерирует связные и точные подписи непосредственно из данных датчика, обеспечивая большую детализацию и точность, чем универсальные языковые модели.
Поведение масштабирования
Наши эксперименты также показали, что производительность SensorLM стабильно улучшается с увеличением объема данных, размера модели и вычислительной мощности, что соответствует установленным законам масштабирования. Этот устойчивый рост свидетельствует о том, что мы лишь слегка затронули потенциал крупномасштабного предварительного обучения сенсорных языков, указывая на высокую ценность дальнейших исследований в этой парадигме.

В ходе систематических экспериментов по масштабированию моделей SensorLM мы показываем, что увеличение вычислительных ресурсов ( слева ), данных ( посередине ) и размера модели ( справа ) неизменно улучшает производительность при распознавании активности без предварительного обучения.
Заключение
Наше исследование закладывает основу для понимания данных с носимых датчиков с помощью естественного языка, что стало возможным благодаря новой иерархической системе создания подписей и крупнейшему на сегодняшний день набору данных о взаимодействии сенсоров и языка. Семейство моделей SensorLM представляет собой значительный шаг вперед в обеспечении понятности и возможности использования персональных данных о здоровье. Обучая ИИ понимать язык нашего тела, мы можем выйти за рамки простых метрик и перейти к действительно персонализированным выводам.
В перспективе мы планируем масштабировать данные предварительного обучения на новые области, включая метаболическое здоровье и детальный анализ сна, чтобы решить сложные задачи, связанные с потребительскими медицинскими устройствами. Мы видим, что SensorLM приведет к созданию будущего поколения цифровых консультантов по здоровью, инструментов клинического мониторинга и персональных приложений для поддержания хорошего самочувствия, которые смогут предлагать рекомендации посредством запросов, взаимодействия и генерации информации на естественном языке. Любые будущие продукты или приложения, созданные на основе этого фундаментального исследования, могут потребовать дополнительной оценки любых клинических и нормативных аспектов, которые могут быть применимы.
Благодарности
Описанное здесь исследование является результатом совместной работы Google Research, Google Health, Google DeepMind и партнерских команд. В работе приняли участие следующие исследователи: Ювэй Чжан, Кумар Аюш, Сиюань Цяо, А. Али Хейдари, Гириш Нараянсвами, Максвелл А. Сюй, Ахмед Метвалли, Шон Сюй, Джейк Гаррисон, Сюхай Сюй, Тим Альтхофф, Юн Лю, Пушмит Коли, Цзининг Чжан, Марк Малхотра, Шветак Патель, Сесилия Масколо, Синь Лю, Дэниел Макдафф и Ючже Ян. Мы также хотели бы поблагодарить участников, предоставивших свои данные для этого исследования.
Источник: research.google




















