
Почему специализированные модели по-прежнему обладают 30-кратным преимуществом в скорости в производственных условиях?
Делиться

Выпуск Segment Anything Model 3 (SAM3) от Meta произвел настоящий фурор в сообществе компьютерного зрения. Социальные сети были справедливо завалены похвалами за его производительность. SAM3 — это не просто незначительное обновление; он представляет Promptable Concept Segmentation (PCS), архитектуру языка зрения, которая позволяет пользователям сегментировать объекты, используя подсказки на естественном языке. От возможностей 3D-моделирования (SAM3D) до встроенной функции отслеживания видео, это, несомненно, шедевр универсального искусственного интеллекта.
Однако в мире искусственного интеллекта промышленного уровня ажиотаж часто размывает грань между возможностью создания моделей без предварительного обучения и практическим превосходством. После релиза многие утверждали, что обучение на детекторах домов больше не требуется. Как инженер, который годами внедрял модели в полевых условиях, я испытывал знакомый скептицизм. Хотя модель фундамента — это универсальный инструмент, вы же не будете использовать её для вырубки леса, если у вас есть бензопила. В этой статье исследуется вопрос, который часто затрагивается в научных работах, но редко проверяется в условиях производственной среды.
Может ли небольшая, специализированная модель, обученная на ограниченных данных и с вычислительным бюджетом в 6 часов, превзойти огромную универсальную модель, такую как SAM3, в полностью автономном режиме?
Тем, кто работает в сфере компьютерного зрения, инстинктивный ответ — да. Но в индустрии, движимой данными, одной интуиции недостаточно, поэтому я решил это доказать.
Что нового в SAM3?

Прежде чем перейти к тестам производительности, необходимо понять, почему SAM3 считается таким прорывом. SAM3 — это мощная базовая модель, содержащая 840,50975 миллионов параметров. Такой масштаб имеет свою цену: вывод результатов требует больших вычислительных затрат. На графическом процессоре NVIDIA P100 это занимает примерно ~1100 мс на изображение.
В то время как предшественник SAM фокусировался на параметре «Где» (интерактивные щелчки, поля и маски), SAM3 представляет компонент «Видение-Язык», который позволяет осуществлять логическое мышление с помощью текстовых подсказок с открытым словарем.
Короче говоря, SAM3 превращается из интерактивного помощника в систему, работающую без предварительного задания . Ей не нужен заранее определенный список меток; она работает на лету. Это делает ее идеальным инструментом для редактирования изображений и ручной аннотации. Но остается вопрос: действительно ли этот мощный универсальный «мозг» превосходит по производительности узкоспециализированного специалиста, когда задача узкая, а среда автономна?
Контрольные показатели
Чтобы сравнить SAM3 с моделями, обученными в рамках определенной предметной области, я выбрал в общей сложности пять наборов данных, охватывающих три области: обнаружение объектов, сегментация экземпляров и обнаружение значимых объектов. Для обеспечения объективности и реалистичности сравнения я определил следующие критерии для процесса обучения.
- Справедливые условия для SAM3 : Категории набора данных должны быть распознаваемы SAM3 без дополнительных настроек. Мы хотим протестировать SAM3 на его сильных сторонах. Например, SAM3 может точно отличить акулу от кита. Однако требовать от него различать синего кита и финвала может быть несправедливо.
- Минимальная настройка гиперпараметров : я использовал начальные приближения для большинства параметров с минимальной или вообще без тонкой настройки. Это имитирует сценарий быстрого старта для инженера.
- Строгий бюджет вычислительных ресурсов : специализированные модели обучались в течение максимум 6 часов. Это удовлетворяет условию использования минимальных и доступных вычислительных ресурсов.
- Точность подсказок : Для каждого набора данных я тестировал подсказки SAM3 на 10 случайно выбранных изображениях. Я окончательно определял подсказку только после того, как убеждался, что SAM3 правильно распознает объекты на этих образцах. Если вы сомневаетесь, вы можете выбрать случайные изображения из этих наборов данных и протестировать мои подсказки в демоверсии SAM3, чтобы подтвердить этот непредвзятый подход.
В следующей таблице показано средневзвешенное значение отдельных метрик для каждого случая. Если вы спешите, эта таблица дает общее представление о компромиссе между производительностью и скоростью. Все результаты работы WandDB можно посмотреть здесь.

Давайте рассмотрим нюансы каждого варианта использования и выясним, почему цифры выглядят именно так.
Обнаружение объектов
В данном случае мы проводим сравнительный анализ наборов данных, используя только ограничивающие рамки. Это наиболее распространенная задача в производственных средах.
Для оценки мы используем стандартные метрики COCO , вычисляемые с помощью IoU на основе ограничивающих рамок . Чтобы определить общего победителя на разных наборах данных, я использую взвешенную сумму этих метрик. Наибольший вес я присвоил mAP (средняя точность), поскольку она дает наиболее полное представление о балансе точности и полноты модели. Хотя веса помогают нам выбрать общего победителя, вы можете увидеть, как каждая модель показывает себя по сравнению с другими в каждой отдельной категории.
1. Глобальное обнаружение пшеницы
Первый пост, который я увидел в LinkedIn, касающийся производительности SAM3, был посвящен именно этому набору данных. Именно этот пост подтолкнул меня к идее провести сравнительный анализ, а не основывать свое мнение на нескольких отдельных примерах.
Этот набор данных занимает особое место в моей памяти, потому что это был мой первый конкурс, в котором я участвовал в 2020 году. В то время я был начинающим инженером, только что окончившим специализацию по глубокому обучению у Эндрю Нга. У меня было больше мотивации, чем навыков программирования, и я по глупости решил реализовать YOLOv3 с нуля. Моя реализация оказалась катастрофой: показатель полноты составил около 10%, и я не смог отправить ни одной успешной заявки. Однако из этой неудачи я извлек больше уроков, чем из любого обучающего материала. Повторное использование этого набора данных стало приятным путешествием в прошлое и наглядным способом увидеть, насколько я вырос.
Для разделения данных на обучающую и проверочную выборки я случайным образом разделил предоставленные данные в соотношении 90 к 10, чтобы гарантировать, что обе модели будут оцениваться на одних и тех же изображениях. В итоге получилось 3035 изображений для обучения и 338 изображений для проверки .
Я использовал Ultralytics YOLOv11-Large и задал предварительно обученные веса COCO в качестве отправной точки, после чего обучал модель в течение 30 эпох с гиперпараметрами по умолчанию. Процесс обучения занял всего 2 часа 15 минут .









Исходные данные показывают, что SAM3 отстает от YOLO на 17% в целом , но визуальные результаты рассказывают более сложную историю. Прогнозы SAM3 иногда оказываются точными, тесно коррелируя с состоянием колоса пшеницы.
Напротив, модель YOLO предсказывает несколько большие прямоугольники, охватывающие ости (щетинки волосков). Поскольку аннотации набора данных включают эти ости, модель YOLO технически более корректна в соответствии с конкретным сценарием использования, что объясняет ее лидерство по высоким показателям IoU. Это также объясняет, почему SAM3, по-видимому, доминирует над YOLO в категории «Малые объекты» ( преимущество в 132% ). Чтобы обеспечить справедливое сравнение, несмотря на это несоответствие ограничивающих прямоугольников, следует рассмотреть AP50 . При пороговом значении IoU 0,5 SAM3 проигрывает на 12,4%.
Хотя моя модель YOLOv11 с трудом справлялась с самыми мелкими колосьями пшеницы (эту проблему можно было решить, добавив высокоточную головку обнаружения P2), специализированная модель все же выиграла в большинстве категорий в реальных условиях эксплуатации.
| Метрическая система | yolov11-large | SAM3 | % Изменять |
|---|---|---|---|
| АП | 0.4098 | 0,315 | -23.10 |
| АП50 | 0.8821 | 0.7722 | -12.40 |
| АП75 | 0.3011 | 0.1937 | -35.60 |
| АП малый | 0,0706 | 0,0649 | -8.00 |
| AP средний | 0.4013 | 0.3091 | -22.90 |
| АП большой | 0,464 | 0.3592 | -22.50 |
| AR 1 | 0,0145 | 0,0122 | -15.90 |
| AR 10 | 0.1311 | 0.1093 | -16.60 |
| AR 100 | 0,479 | 0,403 | -15.80 |
| AR маленький | 0,0954 | 0.2214 | +132 |
| AR средний | 0.4617 | 0.4002 | -13.30 |
| AR большой | 0.5661 | 0.4233 | -25.20 |
В скрытом тестовом наборе данных для сравнения специализированная модель также значительно превзошла SAM3.
| Модель | Общедоступный рейтинг LB | Частный LB-рейтинг |
|---|---|---|
| yolov11-large | 0,677 | 0.5213 |
| SAM3 | 0.4647 | 0.4507 |
| Изменять | -31.36 | -13.54 |
Детали выполнения:
- SAM3 Задание: пшеница, цветок, колос, зеленый колос, колос, зеленый колос
- Учебный блокнот YOLOv11
- SAM3 Hidden Set Benchmark
- Тест производительности скрытого набора YOLOv11
2. Обнаружение оружия с помощью систем видеонаблюдения
Я выбрал этот набор данных для сравнительной оценки SAM3 на изображениях, полученных в ходе видеонаблюдения, и для ответа на важный вопрос: имеет ли смысл использовать базовую модель, когда данных крайне мало?
Набор данных состоит всего из 131 изображения, полученного с камер видеонаблюдения в шести разных местах. Поскольку изображения с одной и той же камеры сильно коррелируют, я решил разделить данные на уровне сцены, а не на уровне изображения. Это гарантирует, что набор данных для валидации будет содержать исключительно ранее не встречавшиеся среды, что является лучшей проверкой устойчивости модели. Я использовал четыре сцены для обучения и две для валидации, в результате чего получилось 111 обучающих изображений и 30 изображений для валидации .
Для решения этой задачи я использовал YOLOv11-Medium . Чтобы предотвратить переобучение на таком малом размере выборки, я сделал несколько конкретных инженерных решений:
- Замораживание базовой модели : Я заморозил всю базовую модель, чтобы сохранить предварительно обученные признаки COCO. Если разморозить только 111 изображений, это, вероятно, приведет к повреждению весов и нестабильному обучению.
- Регуляризация : я увеличил коэффициент затухания весов и использовал более интенсивное расширение данных, чтобы заставить модель обобщать результаты.
- Корректировка скорости обучения : Я снизил как начальную, так и конечную скорость обучения, чтобы обеспечить плавную сходимость головной части модели к новым признакам.









Весь процесс обучения занял всего 8 минут на 50 эпох. Несмотря на то, что я планировал этот эксперимент как вероятную победу SAM3, результаты оказались неожиданными. Специализированная модель превзошла SAM3 во всех категориях, уступив YOLO в целом на 20,50% .
| Метрическая система | yolov11-medium | SAM3 | Изменять |
|---|---|---|---|
| АП | 0.4082 | 0.3243 | -20.57 |
| АП50 | 0,831 | 0.5784 | -30.4 |
| АП75 | 0.3743 | 0.3676 | -1.8 |
| AP_small | – | – | – |
| AP_medium | 0,351 | 0,24 | -31.64 |
| AP_large | 0,5338 | 0.4936 | -7.53 |
| AR_1 | 0,448 | 0,368 | -17.86 |
| AR_10 | 0,452 | 0,368 | -18.58 |
| AR_100 | 0,452 | 0,368 | -18.58 |
| AR_small | – | – | – |
| AR_medium | 0.4059 | 0.2941 | -27.54 |
| AR_large | 0,55 | 0,525 | -4.55 |
Это говорит о том, что для решения конкретных задач с высокими ставками, таких как обнаружение оружия, даже небольшое количество изображений, относящихся к конкретной области, может обеспечить более высокую базовую оценку, чем массивная универсальная модель.
Детали выполнения:
- Подсказка SAM3: ружье, винтовка, оружие
- Блокнот для сравнения обучающих материалов YOLOv11 и SAM3
Сегментация экземпляров
В этом примере мы проводим сравнительный анализ наборов данных с использованием масок сегментации на уровне экземпляров и полигонов. Для оценки мы используем стандартные метрики COCO , вычисленные с помощью IoU на основе масок . Аналогично разделу об обнаружении объектов, я использую взвешенную сумму этих метрик для определения окончательного рейтинга.
Существенной проблемой при оценке эффективности сегментации экземпляров является то, что многие высококачественные наборы данных предоставляют только семантические маски. Для создания справедливой тестовой среды для SAM3 и YOLOv11 я выбрал наборы данных, где объекты имеют четкие пространственные промежутки между собой. Я разработал конвейер предварительной обработки для преобразования этих семантических масок в метки на уровне экземпляров путем идентификации отдельных связанных компонентов. Затем я отформатировал их в виде набора данных COCO Polygon. Это позволило нам измерить, насколько хорошо модели различают отдельные объекты, а не просто идентифицируют объекты .
1. Сегментация трещин в бетоне
Я выбрал этот набор данных, потому что он представляет собой серьезную проблему для обеих моделей. Трещины имеют крайне неправильную форму и разветвленные пути, которые, как известно, очень трудно точно запечатлеть. В результате окончательного разделения осталось 9603 изображения для обучения и 1695 изображений для валидации .
Исходные метки для трещин были чрезвычайно мелкими. Для эффективного обучения на таких тонких структурах мне потребовалось бы использовать очень высокое разрешение входных данных, что было нецелесообразно в рамках моих вычислительных ресурсов. Для решения этой проблемы я применил морфологическое преобразование для утолщения масок. Это позволило модели изучать структуры трещин с более низким разрешением, сохраняя при этом приемлемые результаты. Для обеспечения справедливого сравнения я применил точно такое же преобразование к выходным данным SAM3. Поскольку SAM3 выполняет вывод с высоким разрешением и обнаруживает мелкие детали, утолщение его масок гарантировало, что мы сравниваем сопоставимые данные при оценке.
Я обучил модель YOLOv11-Medium-Seg в течение 30 эпох . Я сохранил настройки по умолчанию для большинства гиперпараметров, что привело к общему времени обучения в 5 часов 20 минут .









Специализированная модель превзошла SAM 3 с общей разницей в результатах в 47,69% . Наиболее примечательно, что SAM 3 испытывала трудности с полнотой, отставая от модели YOLO более чем на 33% . Это говорит о том, что, хотя SAM 3 может идентифицировать трещины в общем смысле, ей не хватает специфической чувствительности, необходимой для составления исчерпывающих карт сетей трещин в автономном режиме.
Однако визуальный анализ показывает, что к этому существенному разрыву в 47,69 % следует отнестись с осторожностью. Даже после постобработки SAM 3 создает более тонкие маски, чем модель YOLO, и, вероятно, SAM3 получает штрафные баллы за тонкую сегментацию. Хотя YOLO все равно выиграет этот тест, более точная метрика с поправкой на маску, вероятно, приблизит фактическую разницу в производительности к 25%.
| Метрическая система | yolov11-medium | SAM3 | Изменять |
|---|---|---|---|
| АП | 0.2603 | 0.1089 | -58.17 |
| АП50 | 0.6239 | 0.3327 | -46.67 |
| АП75 | 0.1143 | 0,0107 | -90.67 |
| AP_small | 0,06 | 0,01 | -83.28 |
| AP_medium | 0.2913 | 0.1575 | -45.94 |
| AP_large | 0.3384 | 0.1041 | -69.23 |
| AR_1 | 0.2657 | 0.1543 | -41.94 |
| AR_10 | 0.3281 | 0.2119 | -35.41 |
| AR_100 | 0.3286 | 0.2192 | -33.3 |
| AR_small | 0,0633 | 0,0466 | -26.42 |
| AR_medium | 0.3078 | 0.2237 | -27.31 |
| AR_large | 0.4626 | 0.2725 | -41.1 |
Детали выполнения:
- SAM3 Подсказка: трещина, излом
- Блокнот для сравнения обучающих материалов YOLOv11 и SAM3
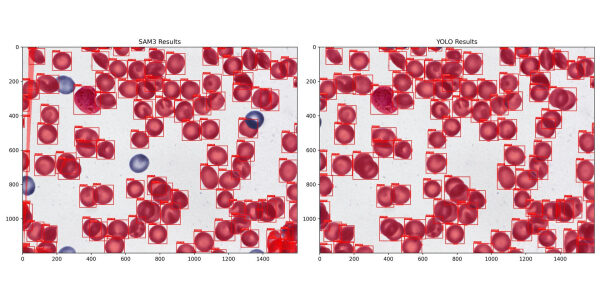
2. Сегментация клеток крови
Я включил этот набор данных для тестирования моделей в медицинской области. На первый взгляд, это казалось явным преимуществом для SAM3. Изображения не требуют сложной обработки с высоким разрешением, а клетки, как правило, имеют четкие, ясные границы, что как раз и является тем, в чем обычно преуспевают базовые модели. По крайней мере, такова была моя гипотеза.
Аналогично предыдущей задаче, мне нужно было преобразовать семантические маски в формат сегментации экземпляров в стиле COCO. Изначально меня беспокоило наличие соприкасающихся клеток . Если несколько клеток были сгруппированы в один блок маски, моя предварительная обработка рассматривала бы их как один экземпляр. Это могло бы создать смещение, при котором модель YOLO училась бы предсказывать кластеры, в то время как SAM3 правильно идентифицировала бы отдельные клетки, но получала бы за это штрафные баллы. При более внимательном рассмотрении я обнаружил, что в наборе данных были небольшие промежутки в несколько пикселей между соседними клетками. Используя обнаружение контуров, я смог разделить их на отдельные экземпляры. Я намеренно избегал морфологического расширения, чтобы сохранить эти промежутки, и обеспечил идентичность конвейера вывода SAM3. Набор данных был разделен на 1169 обучающих изображений и 159 изображений для валидации .
Я обучал модель YOLOv11-Medium в течение 30 эпох . Единственное существенное изменение по сравнению с настройками по умолчанию заключалось в увеличении параметра weight_decay для более агрессивной регуляризации. Обучение прошло невероятно эффективно и заняло всего 46 минут .









Несмотря на мою первоначальную уверенность в победе SAM3, специализированная модель снова превзошла базовую модель на 23,59% в целом . Даже когда правила визуализации, казалось бы, благоприятствуют универсальной модели, специализированное обучение позволяет меньшей модели улавливать специфические нюансы предметной области, которые SAM3 упускает. Как видно из приведенных выше результатов, SAM3 пропускает довольно много экземпляров ячеек.
| Метрическая система | yolov11-Medium | SAM3 | Изменять |
|---|---|---|---|
| АП | 0,6634 | 0,5254 | -20.8 |
| АП50 | 0.8946 | 0.6161 | -31.13 |
| АП75 | 0.8389 | 0.5739 | -31.59 |
| AP_small | – | – | – |
| AP_medium | 0.6507 | 0,5648 | -13.19 |
| AP_large | 0.6996 | 0.4508 | -35.56 |
| AR_1 | 0,0112 | 0,01 | -10.61 |
| AR_10 | 0.1116 | 0,0978 | -12.34 |
| AR_100 | 0.7002 | 0,5876 | -16.09 |
| AR_small | – | – | – |
| AR_medium | 0.6821 | 0.6216 | -8.86 |
| AR_large | 0.7447 | 0,5053 | -32.15 |
Детали выполнения:
- Подсказка SAM3: клетка, синяя клетка, красная клетка
- Блокнот для сравнения обучающих материалов YOLOv11 и SAM3
Обнаружение значимых объектов / Выделение объектов на изображении
В данном примере мы проводим сравнительный анализ наборов данных, включающих бинарную сегментацию с использованием масок для разделения переднего и заднего плана. Основное применение — задачи редактирования изображений, такие как удаление фона, где точное разделение объекта имеет решающее значение.
Коэффициент Дайса — это наш основной показатель оценки. На практике значения коэффициента Дайса быстро достигают уровня около 0,99, как только модель сегментирует большую часть области. На этом этапе значимые различия появляются в узком диапазоне от 0,99 до 1,0 . Небольшие абсолютные улучшения здесь соответствуют визуально заметным улучшениям, особенно вокруг границ объектов.
Для общего сравнения мы рассматриваем два показателя:
- Коэффициент Дайса : Взвешенный 3,0
- MAE (средняя абсолютная ошибка) : взвешенная с шагом 0,01.
Примечание : Я также добавил F1-меру, но позже понял, что F1-мера и коэффициент Дайса математически идентичны, поэтому я опустил её здесь. Хотя существуют специализированные метрики, ориентированные на границы возможностей, я исключил их, чтобы сохранить ориентацию на начинающего инженера . Мы хотим посмотреть, сможет ли кто-то с базовыми навыками превзойти SAM3, используя стандартные инструменты.
В логах Weights & Biases (W&B) результаты работы специализированной модели могут выглядеть объективно хуже по сравнению с SAM3. Это артефакт визуализации, вызванный бинарной пороговой обработкой. Наша модель ISNet предсказывает градиентную альфа-маску, которая позволяет получить плавные полупрозрачные края. Для синхронизации с W&B я использовал фиксированный порог 0,5 для преобразования этих масок в бинарные. В производственной среде настройка этого порога или использование исходной альфа-маски даст гораздо более высокое визуальное качество. Поскольку SAM3 создает бинарную маску прямоугольника, его результаты отлично выглядят в W&B. Я рекомендую обратиться к результатам, приведенным в разделе вывода ноутбука.
Проектирование трубопровода:
Для решения этой задачи я использовал ISNet, применив код модели и предварительно обученные веса из официального репозитория, но реализовал собственный цикл обучения и классы набора данных. Для оптимизации процесса я также реализовал:
- Синхронизированные преобразования : Я расширил возможности преобразований torchvision, чтобы обеспечить идеальную синхронизацию преобразований маски (таких как вращение или отражение) с изображением.
- Обучение со смешанной точностью : Я модифицировал класс модели и функцию потерь для поддержки смешанной точности. Для обеспечения численной стабильности я использовал BCEWithLogitsLoss .
1. Набор данных EasyPortrait
Я хотел включить в анализ задачу удаления фона, особенно для селфи/портретных снимков, которая сопряжена с высокими рисками. Это, пожалуй, самое популярное на сегодняшний день применение метода обнаружения значимых объектов. Главная сложность здесь — сегментация волос. Человеческие волосы имеют высокочастотные края и прозрачность, которые, как известно, очень трудно зафиксировать. Кроме того, люди носят разнообразную одежду, которая часто сливается с цветом фона.
Исходный набор данных содержит 20 000 размеченных изображений лиц. Однако предоставленный тестовый набор был значительно больше, чем набор для валидации. Запуск SAM3 на таком большом тестовом наборе превысил бы квоту Kaggle на использование графических процессоров на той неделе, а мне эта квота была нужна для других задач. Поэтому я поменял местами два набора, что позволило создать более управляемый конвейер оценки.
- Набор поездов : 14 000 изображений
- Набор изображений Val : 4000 изображений
- Тестовый набор : 2000 изображений
Стратегические улучшения:
Чтобы гарантировать полезность модели в реальных рабочих процессах, а не просто переобучение на валидационном наборе данных, я реализовал надежный конвейер аугментации. Вы можете увидеть аугментацию выше, но вот моя идея, лежащая в основе аугментации.
- Изменение размера с учетом пропорций : сначала я изменил размер по самой длинной стороне, а затем взял случайный фрагмент фиксированного размера. Это предотвратило эффект сплющенного лица, часто возникающий при стандартном изменении размера.
- Перспективные преобразования : Поскольку набор данных состоит в основном из изображений людей, смотрящих прямо в камеру, я добавил сильные перспективные сдвиги, чтобы имитировать ракурсы сидящих под углом или снимки в профиль.
- Коррекция цветовых искажений : я регулировал яркость и контрастность, чтобы корректировать освещение от недоэкспонированного до переэкспонированного, но сохранял нулевой сдвиг оттенка, чтобы избежать неестественных телесных тонов.
- Аффинные преобразования : Добавлено вращение для обработки различных наклонов камеры.

Из-за вычислительных ограничений я проводил обучение с разрешением 640×640 в течение 16 эпох . Это стало существенным недостатком, поскольку SAM3 работает и, вероятно, обучался с разрешением 1024×1024 , а обучение заняло 4 часа 45 минут .




Даже с учётом недостатка разрешения и минимального обучения, специализированная модель превзошла SAM3 на 0,25% в целом . Однако численные результаты скрывают интересный визуальный компромисс:
- Качество краев : В настоящее время предсказания нашей модели более зашумлены из-за короткой продолжительности обучения. Однако, когда они достигают цели, края получаются естественно размытыми, что идеально подходит для смешивания.
- Эффект «квадратности» SAM3 : SAM3 невероятно стабилен, но его края часто выглядят как многоугольники с высокими точками, а не как органические маски. Он создает квадратную, пикселизированную границу , которая выглядит искусственной.
- Победа в области волос : Наша модель превосходит SAM3 в областях, где преобладают волосы. Несмотря на шум, наша модель точно передает органический поток волос, в то время как SAM3 часто лишь приблизительно отображает эти области. Это отражается в средней абсолютной ошибке (MAE) , где SAM3 на 27,92% слабее .
- Проблемы с сегментацией одежды : Напротив, SAM3 отлично справляется с сегментацией одежды, где границы имеют более геометрическую форму. Наша модель по-прежнему испытывает трудности с текстурой и формой ткани.
| Модель | МАЭ | Коэффициент Дайса |
|---|---|---|
| ISNet | 0,0079 | 0,992 |
| SAM3 | 0,0101 | 0.9895 |
| Изменять | -27.92 | -0.25 |
Тот факт, что модель с ограниченными возможностями (более низкое разрешение, меньшее количество эпох) все еще может превзойти базовую модель по ее сильнейшему показателю ( MAE/точность границ ), свидетельствует о специализированном обучении. Если масштабировать модель до 1024 пикселей и обучать ее дольше, эта специализированная модель, вероятно, покажет дальнейшее превосходство над SAM3 в данном конкретном случае.
Детали выполнения:
- SAM3 Prompt: person, human, face
- Журнал обучения и сравнения
Заключение
На основе этого многодоменного сравнительного анализа данные указывают на четкий стратегический путь развития компьютерного зрения на производственном уровне. Хотя базовые модели, такие как SAM3, представляют собой огромный скачок в возможностях, их лучше использовать в качестве ускорителей разработки, а не в качестве постоянных производственных рабочих.
- Пример 1: Фиксированные категории и доступные размеченные данные (более 500 образцов). Обучение специализированной модели. Точность, надежность и в 30 раз более высокая скорость вывода значительно перевешивают небольшое время, затраченное на начальное обучение.
- Вариант 2: Фиксированные категории, но нет размеченных данных. Используйте SAM3 в качестве интерактивного помощника по разметке (не автоматического). SAM3 не имеет себе равных для бутстрапинга набора данных. После того, как у вас будет около 500 высококачественных кадров , перейдите к специализированной модели для развертывания.
- Вариант 3: Холодный старт (нет изображений, нет размеченных данных). Разверните SAM3 в режиме теневого доступа с низкой нагрузкой на несколько недель, чтобы собрать изображения из реального мира. После создания репрезентативного корпуса обучите и разверните модель, специфичную для данной области. Используйте SAM3 для ускорения рабочих процессов аннотирования.
Почему в производстве побеждает специалист?
1. Аппаратная независимость и экономическая эффективность
Для получения высококачественного изображения вам не обязательно нужна пленка H100. Специализированные модели, такие как YOLOv11, разработаны для обеспечения высокой эффективности.
- Обслуживание с помощью графического процессора : Один процессор Tesla T4 (стоимость которого ничтожна по сравнению с H100 ) может обслуживать большую пользовательскую базу с задержкой менее 50 мс . Его можно масштабировать горизонтально в зависимости от потребностей.
- Целесообразность использования ЦП : Для многих рабочих процессов развертывание на ЦП является жизнеспособным и высокорентабельным вариантом. Используя мощный модуль ЦП и горизонтальное масштабирование, можно управлять задержкой в районе 200 мс , сводя к минимуму сложность инфраструктуры.
- Оптимизация : Специализированные модели можно отфильтровывать и квантовать. Оптимизированная модель YOLO на ЦП может обеспечить непревзойденную производительность при высокой скорости вывода результатов.
2. Полная собственность и надежность
Когда вы владеете моделью, вы контролируете решение. Вы можете переобучить её для устранения конкретных ошибок в крайних случаях, исправления галлюцинаций или создания весов, специфичных для разных условий эксплуатации. Запуск десятка специализированных моделей, оптимизированных для конкретных условий, часто обходится дешевле и предсказуемее, чем запуск одной огромной базовой модели.
Будущая роль SAM3
SAM3 следует рассматривать как помощника в визуальном анализе. Это универсальный инструмент для любых задач, где категории не являются фиксированными, например:
- Интерактивное редактирование изображений : процесс сегментации, управляемый человеком.
- Поиск по открытому словарю : поиск любого объекта в обширной базе данных изображений/видео.
- Аннотирование с помощью ИИ : сокращение времени ручной разметки.
Команда Meta создала шедевр с SAM3, и понимание его концепции кардинально меняет ситуацию. Однако для инженера, стремящегося создать масштабируемый, экономически эффективный и точный продукт сегодня, специализированная модель Expert остается лучшим выбором. Я с нетерпением жду возможности добавить SAM4 в будущем, чтобы увидеть, как будет развиваться этот разрыв.
Вы наблюдаете, как фундаментные модели заменяют ваши специализированные трубопроводы, или их стоимость по-прежнему слишком высока? Давайте обсудим это в комментариях. Также, если эта информация оказалась для вас полезной, буду благодарен, если вы поделитесь ею!
Источник: towardsdatascience.com

























